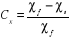Sida et Comportements Sexuels des femmes célibataires au Congo( Télécharger le fichier original )par Stève Bertrand MBOKO IBARA Université de Yaoundé II / Institut de Formation et de Recherche Démographique (IFORD) - DESS en Démographie 2008 |

D-/ LES DIFFÉRENTES METHODES D'ANALYSEa-/ Analyse descriptiveDans cette étude nous procéderons à la fois à l'analyse bivariée descriptive et à l'analyse descriptive multivariée. Nous recourons à l'analyse bivariée descriptive entre les variables indépendantes et les variables dépendantes pour déterminer le niveau de comportement sexuel en utilisant la statistique de Khi2. Cette statistique permet de déceler la liaison entre deux variables traduite par le rejet de l'hypothèse d'indépendance entre elles. Nous recourons à l'analyse multivariée descriptive pour regrouper les femmes célibataires en fonction de leurs caractéristiques au moyen de l'analyse factorielle des correspondances multiples. Principe de l'Analyse factorielle des correspondances multiples (AFCM) Les méthodes factorielles établissent des représentations synthétiques de vastes tableaux de données, en général sous forme de représentations graphiques. Ces méthodes ont pour objet de réduire les dimensions des tableaux de données de façon à représenter les associations entre individus et entre variables dans des espaces de faibles dimensions. L'espace de représentation obtenu est appelé plan factoriel. Les méthodes diffèrent selon la nature des variables analysées, le choix d'une méthode restant tributaire de l'objectif poursuivi par l'étude. L'analyse factorielle des correspondances multiples est un cas particulier des méthodes factorielles. Elle est utilisée à une fin descriptive et s'applique à des variables qualitatives dont on souhaite étudier l'interdépendance de façon concomitante. Cependant, plusieurs axes factoriels peuvent être définis, et leur combinaison pris 2 à 2 défini à chaque fois un plan factoriel susceptible d'être étudié. Des techniques appropriées aident cependant l'analyste sur le choix du nombre d'axes à retenir (histogramme des valeurs propres, principe de Kapper pour l'ACP, etc.). Comme il ne s'agit que d'une analyse descriptive, il ne faut pas perdre de vue que la liaison statistique significative entre deux variables peut être réelle ou fallacieuse, ce qui pourra être vérifié en contrôlant cette relation par d'autres variables. La corrélation n'étant pas la causalité, nous procéderons donc par la suite à une analyse explicative. b-/ La méthode d'analyse multivariée13(*)Il s'agit ici de faire une brève présentation des méthodes d'analyse multivariées en rapport avec nos variables d'analyse qui sont des variables qualitatives. La méthode multivariée explicative retenue dans le cas de cette étude est celle de la régression logistique. Les modèles de régression logistique sont utilisés pour décrire les relations entre une variable dépendante qualitative à deux modalités et des variables indépendantes. Celles-ci peuvent être quantitatives ou qualitatives. Elle nous permet de mettre en relief les déterminants des comportements sexuels des femmes célibataires et les mécanismes par lesquels certaines variables influencent ces comportements. Les variables de comportement sexuels à risque, qui sont ici des variables dépendantes au nombre de deux (le multipartenariat et la non-utilisation du condom au dernier rapport sexuel) sont toutes dichotomiques. Cette méthode est essentiellement probabiliste, elle fournit entre autres statistiques : Ø le "odd ratio" ou risque relatif de connaître l'évènement étudié ; Ø la statique de khi deux (Khi2) pour le test de signification du modèle et des paramètres ; Ø le pseudo R2 pour le test de l'adéquation du modèle ; Ø les seuils de signification des odds ratios. Considérons par exemple la variable dépendante Y1= « Multipartenariat sexuel des les 12 derniers mois» ; P(Y1=1) est la probabilité pour une célibataire d'avoir eu des rapports sexuels avec plus d'un partenaire dans les 12 derniers mois précédent l'enquête et 1-P(Y1=1) la probabilité de l'événement contraire. Alors, le modèle de régression logistique permet de mettre Z = log (P/1-P) = logit (P), sous la forme linéaire :Z = b0 + b1.X1 + b2.X2 + ....bn.Xn Le deuxième membre de l'équation représente le log des chances. Les coefficients bi permettent d'obtenir les « odds » (les risques) dont l'interprétation est relativement facile (odds= ebi ) : · Si bi est négatif ebi <1 : l'évènement a moins de chance de se produire par rapport à la modalité de référence de la variable. En d'autres termes, les individus appartenant à la modalité considérée de la variable explicative ont (1- ebi) moins de chance que leur homologue de la modalité de référence de subir l'évènement étudié. · Si bi est positif ebi >1 : l'évènement a plus de chance de se produire par rapport à la modalité de référence de la variable. Autrement dit, les individus appartenant à la modalité considérée de la variable explicative ont donc (ebi -1) plus de chance que leur homologue de la modalité de référence de subir l'évènement étudié. Le test de Khi2 permet de savoir si le modèle est adéquat ou pas. Si la probabilité critique associée au Khi2 est inférieure au seuil choisi le modèle est donc adéquat. Cela voudrait dire que les variables indépendantes considérées dans l'ensemble expliquent la variation de la variable dépendante. Elles peuvent donc prédire la valeur de Y. Dans le cas de cette étude, un modèle sera adéquat lorsque le seuil de signification associé au Khi2 sera inférieur ou égal à 5%. Le Pseudo R2 permet d'estimer la part (en %) de la variance de la variable dépendante expliquée par le modèle. Pseudo R2 = Khi-deux/ (Khi-deux +n) où n est la taille de l'échantillon La contribution de chaque variable indépendante à l'explication sera calculée à partir de la formule suivante : Cx: Contribution de la variable f : Khi deux finale s : Khi deux sans la variable * 13 Taffé P. 2004. |
|