L'espace web du sénégal : étude de son degré d'ouverture ´ travers l'analyse des liens hypertextes( Télécharger le fichier original )par El Hadji Malick GUEYE Université Paris 10 Nanterre - Master de Recherche 2005 |

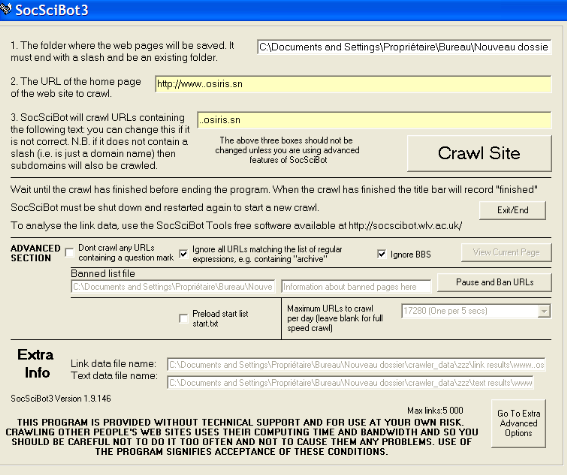
Partie IV : Analyse de l'espace Web du SénégalI. La constitution du corpusLa constitution du corpus est l'étape cruciale de notre étude. Notre objectif était de rassembler avec la manière la plus exhaustive possible l'ensemble des sites Web sénégalais. Pour des raisons techniques quant à la constitution de cette liste de sites et afin d'être beaucoup plus précis dans notre analyse, nous avons décidé de ne prendre que les sites avec le ccTLD .sn. Cette procédure mettra naturellement à côté les sites Web sénégalais enregistrés sous des gTLDs comme .com, .org, .edu (...) et même certains avec des codes de pays comme .fr, .ca ou autres. Connaissant la limite des moteurs de recherche commerciaux notamment la limitation « volontaire » des résultats, nous avons contacté le Pr. Mike Thelwall de The Statistical Cybermetrics Research Group84(*) de l'Université de Wolverhampton (voir page 49) pour voir s'il n'y a pas un moyen de constituer ce corpus, avec une très bonne exhaustivité. Malheureusement, le crawler dont il disposait n'a pu nous trouver que 79 sites correspondant à l'ensemble des sites composés au maximum de trois lettres (ex : www.xxx.sn). Passer à quatre lettres, à cinq et ainsi de suite demanderait beaucoup de temps car son programme procède en testant toutes les combinaisons possibles des noms de domaine avec le ccTLD .sn. Afin de compléter notre corpus, nous avons eu recours à Google avec la requête « site:.sn » et à Altavista avec « domain:.sn ». Avec le premier nous avons pu remonter jusqu'à 438 résultats bruts et à 1050 avec le second. Après traitement et nettoyage, le croisement entre le crawl du Pr. Thelwall et les résultats des deux moteurs a donné 333 sites, et après vérification de chaque adresse URL, il ne restait plus que 278 (voir la liste en Annexes) sites effectivement en ligne sur les 910 sites officiellement déclarés auprès de NIC Sénégal. Cette liste de sites ainsi rassemblée n'est en fait qu'une étape vers le corpus final devant servir à l'analyse de l'espace Web du Sénégal. L'étape suivante a concerné d'une part, le choix et l'affectation de métadonnées devant permettre la description de chaque site, et d'autre part, la recherche des liens hypertextes. S'inspirant en grande partie de la typologie dressée par Prime-Claverie (2004)85(*), nous avons choisi les champs suivants pour décrire chacun des sites Web Sénégalais : - NS (nom du site) : c'est tout simplement l'adresse URL du site - TA (type d'autorité) : c'est la personne morale ou physique qui est à l'origine de la création du site et qui en assure le fonctionnement et la mise à jour et est ainsi responsable du contenu. L'autorité peut ainsi être une institution, une entreprise, une association ou une personne physique. - TS (type de site) : on distinguera dans ce champs quatre types de site : le homeserveur qui fait une présentation de l'autorité du site en question et donne les différents types d'information qui permettent de le décrire. C'est le type de site le plus fréquent. Ensuite nous avons le site de recherche qui, comme son nom l'indique permet d'accéder aux différentes ressources du Web. Il peut s'agir des moteurs de recherche ou les annuaires. Le troisième type de site est le site de ressources qui propose des ressources propres à l'exemple des bases de données ou les bibliothèques. Enfin, nous avons les services web qui proposent des services liés à la vie sur le Web et l'Internet, comme des messageries, forums de news... - DO (domaine d'activité du site) : - LI (liens internes) : nous entendons par là l'ensemble des liens hypertextes partant du site et pointant vers d'autres sites de l'ensemble (.sn). Le but étant d'étudier par la suite le degré de connectivité des sites sénégalais. - LE (liens externes) : pour ce qui est des liens externes, c'est l'ensemble des liens partant du site et pointant vers d'autres ccTLDs autre que le (.sn) et vers les gTLDs. - TLD (Top Level Domain) : ce champ fait en quelque sorte la récapitulation des différents TLDs (les génériques et les codes de pays) trouvés dans les champs LI et LE et permettra de répartir et d'analyser la présence de chacun d'eux dans le corpus global. L'habillage des champs Types d'autorité (TA), Type de sites (TS) et Domaines (DO), a été effectué après une visite de chaque site afin de bien nous assurer de l'exactitude de ces données. Ainsi, après cette première affectation exécutée, la tâche principale de la constitution de ce corpus est la recherche des liens hypertextes. Nous avons choisi de ne pas utiliser les moteurs de recherche commerciaux pour des raisons évoquées plus haut. Notre choix s'est porté sur le robot Soscibot86(*), développé et mis en libre utilisation en ligne par l'équipe du Pr. Thelwall pour faciliter en quelque sorte le travail des wébomètres et cybermètres. Cet outil, spécialement fait pour ces genres d'études est relativement facile à utiliser avec d'abord l'interface de recherche. Notons que le démarrage de l'opération de recherche nécessite au préalable la mention d'une adresse e-mail accompagnée d'un petit commentaire (sur les raisons du crawl) que le robot envoie aux sites parcourus pour les avertir qu'ils sont en train d'être aspirés. Question d'éthique !
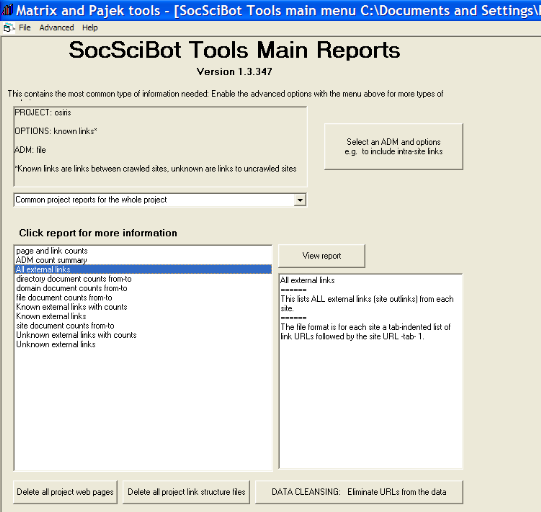
Figure 9 : Interface de recherche de Soscibot Après l'étape de recherche qui peut durer de quelques secondes à plusieurs heures en fonction de la taille du site à aspirer, l'interface résultats nous offre un rapport complet sur le crawl avec le nombre de pages contenues dans le site, le nombre de liens trouvés, la répartition des noms de domaine, etc.
Figure 10 : Interface de restitution des résultats d'un crawl par Soscibot Les liens hypertextes ainsi fournis vont subir un traitement avant leur affectation dans le corpus. Ainsi, nous avons procédé d'abord à une normalisation et à une réduction des liens à leur forme canonique (ex : le lien www.brvm.org/fr/marche/donnees/cours_obligations.htm deviendra www.brvm.org). Car, vu que notre objectif général est d'étudier le degré de connexion entre sites Web, conserver la forme complète des hyperliens trouvés n'augmenterait en rien à la pertinence de notre analyse et ne ferait qu'encombrer notre corpus. Remarque : Le moteur Soscibot, en dépit des nombreux avantages qu'il présente notamment la possibilité de remonter jusqu'à 5000 liens par site (alors que les moteurs de recherche commerciaux comme Google ne restituent pas plus de 300) mais aussi la restitution des résultats en différentes catégories bien classifiées et dans des formats exportables sur Excel, il comporte quelques limites. L'une de ses limites est l'impossibilité d'aspirer des sites dont la page d'accueil est une application Flash ou Java. Ainsi, nous avons une vingtaine de sites qui n'ont pas donné de résultats. Nous sommes obligés d'entrer par une page intérieure en espérant parcourir tout le site et de récupérer la totalité des liens. Par ailleurs, on note aussi la particularité du site de l'IRD ( www.ird.sn). En fait, avec plusieurs tentatives, c'est le seul site que le robot n'a pu parcourir. Pourtant sa page d'accueil n'est ni en application Flash ni en Java. Peut-être est-il protégé des aspirations. Une fois finie la recherche suivie des opérations de nettoyage, de normalisation et d'affectation des liens dans le corpus, voici un exemple de la forme que prendra notre corpus final : NS- www.osiris.sn TA- Association TS- Site de ressources DO- NTIC; LI- .enda.sn; .cresp.sn; .isoc.sn; LE- le-senegal.com; .funredes.org; .famafrique.org; .anais.org; .fdd.org; .intracen.org; .unrisd.org; TLD- .sn; .sn; .sn; .com; .org; .org; .org; .org; .org; .org; Comme on le voit, la compilation du corpus a été effectuée sous la forme d'une référence bibliographique, et ceci dans le but d'avoir un format compatible avec le logiciel que l'on va utiliser pour l'exploitation et l'analyse de nos données, Mathéo Analyzer,87(*) outil bibliométrique assez complet notamment avec les corpus volumineux. Avant d'entrer dans la phase analyse, nous allons présenter d'abord dans le tableau suivant les grands chiffres de notre corpus :
Tableau 1 : Tableau récapitulatif des grands chiffres du corpus Comme nous l'avons signalé plus haut, les liens internes sont l'ensemble des liens vers les sites de l'ensemble (.sn). C'est pourquoi nous constatons une absence de gTLDs dans ce groupe et un ccTLD unique, le .sn. Dans la partie suivante, nous tenterons d'approfondir et de détailler ces chiffres pour bien comprendre l'espace Web du Sénégal notamment la manière dont il est structuré et comment il s'ouvre au monde (le reste de la toile). * 84 http://cybermetrics.wlv.ac.uk/ * 85 Ibid. * 86 http://soscibot.wlv.ac.uk * 87 http://www.matheo-software.com/ |
|