II.6 LES TECHNIQUES DU DATA
MINING
Derrière ces analyses se positionnent des outils
basés sur des techniques différentes. Nous vous proposons une
présentation des plus importante de ces techniques.
- Analyse du panier de la ménagère
- Raisonnement basé sur la mémoire
- Détection automatique de clusters
- Analyse des liens
- Arbres de décision
- Réseaux de neurones
- Découverte de règles
- Signal Processing
- Fractales
II.6.1 Analyse du panier de la
ménagère
L'analyse du panier de la ménagère est un moyen
de trouver les groupes d'articles qui vont ensembles lors d'une transaction.
C'est une technique de découverte de connaissances non dirigée
(de type analyse de clusters) qui génère des règles et
supporte l'analyse des séries temporelles (si les transactions ne sont
pas anonymes). Les règles générées sont simples,
faciles à comprendre et assorties d'une probabilité, ce qui en
fait un outil agréable et directement exploitable par l'utilisateur
métier.
Exemple : Le client qui achète de la peinture
achète un pinceau
Le client qui achète du thé achète du
sucre
II.6.2 Analyse des liens
L'analyse des liens est une technique de description qui
s'inspire et repose sur la théorie des graphes. Elle consiste à
relier des entités entre elles (clients, entreprises, ...) par des
liens. A chaque lien est affecté un poids, défini par l'analyse,
qui quantifie la force de cette relation. Cette technique peut être
utilisée pour la prédiction ou la classification mais
généralement une simple observation du graphe permet de mener
à bien l'analyse.
II.6.3 Les arbres de
décision
Les arbres de décision sont utilisés dans le
cadre de la découverte de connaissances dirigée. Ce sont des
outils très puissants principalement utilisés pour la
classification, la description ou l'estimation. Le principe de fonctionnement
est le suivant : pour expliquer une variable, le système recherche le
critère le plus déterminant et découpe la population en
sous populations possédant la même entité de ce
critère. Chaque sous population est ensuite analysée comme la
population initiale. Le modèle rendu est facile à comprendre et
les règles trouvées sont très explicites. Ce
système est donc très apprécié.
Le but de cette technique est de créer un arbre de
décision procédant a une analyse critère par
critère. La détermination de ces critères significatifs
est faite selon les poids statistiques des valeurs. L'outil de data mining va
parcourir les différents critères possibles, dont la
finalité sera de trouver des liens entre les chemins qui ont une
signification par rapport à la problématique donnée.
On donne un ensemble X de N dont les éléments
sont notés xi et dont les P attributs sont quantitatifs. Chaque
élément de X est étiqueté, c'est-à-dire
qu'il lui est associé une classe ou un attribut cible que l'on note y
appartenant à Y.
A partir de ce qui précède, on construit un
arbre dit « de décision » tel que :
- chaque noeud correspond à un test sur la valeur d'un
ou plusieurs attributs ;
- chaque branche partant d'un noeud correspond à une ou
plusieurs valeurs de ce test ;
Les arbres de décisions ont pour objectif la
classification et la prédiction.
Leur fonctionnement est basé sur un enchaînement
hiérarchique de règles exprimées en langage courant.
Un arbre de décision est une structure qui permet de
déduire un résultat à partir de décisions
successives. Pour parcourir un arbre de décision et trouver une solution
il faut partir de la racine. Chaque noeud est une décision atomique.
Chaque réponse possible est prise en compte et permet de se diriger vers
un des fils du noeud. De proche en proche, on descend dans l'arbre
jusqu'à tomber sur une feuille. La feuille représente la
réponse qu'apporte l'arbre au cas que l'on vient de tester.
- Débuter à la racine de l'arbre
- Descendre dans l'arbre en passant par les noeuds de test
- La feuille atteinte à la fin permet de classer
l'instance testée.
Très souvent on considère qu'un noeud pose une
question sur une variable, la valeur de cette variable permet de savoir sur
quels fils descendre. Pour les variables énumérées il est
parfois possible d'avoir un fils par valeur, on peut aussi décider que
plusieurs variables différentes mènent au même sous arbre.
Pour les variables continues il n'est pas imaginable de créer un noeud
qui aurait potentiellement un nombre de fils infini, on doit discrétiser
le domaine continu (arrondis, approximation), donc décider de segmenter
le domaine en sous ensembles. Plus l'arbre est simple, et plus il semble
techniquement rapide à utiliser. En fait, il est plus intéressant
d'obtenir un arbre qui est adapté aux probabilités des variables
à tester. La plupart du temps un arbre équilibré sera un
bon résultat. Si un sous arbre ne peut mener qu'à une solution
unique, alors tout ce sous-arbre peut être réduit à sa
simple conclusion, cela simplifie le traitement et ne change rien au
résultat final.
L'algorithme ID3 fut proposé par Quinlan en 1979 afin
de générer des arbres de décisions à partir de
données. Imaginons que nous ayons à notre disposition un ensemble
d'enregistrements. Tous les enregistrements ont la même structure,
à savoir un certain nombre de paires attribut ou valeur. L'un de ses
attributs représente la catégorie de l'enregistrement. Le
problème consiste à construire un arbre de décision qui
sur la base de réponses à des questions posées sur des
attributs non cibles peut prédire correctement la valeur de l'attribut
cible. Souvent l'attribut cible prend seulement les valeurs vrai, faux ou
échec, succès.
Les principales idées sur lesquels repose ID3 sont les
suivantes :
Dans l'arbre de décision chaque noeud correspond
à un attribut non cible et chaque arc à une valeur possible de
cet attribut. Une feuille de l' arbre donne la valeur escomptée de
l'attribut cible pour l'enregistrement testé décrit par le chemin
de la racine de l'arbre de décision jusqu'à la feuille.
Dans l'arbre de décision, à chaque noeud doit
être associé l'attribut non cible qui apporte le plus
d'information par rapport aux autres attributs non encore utilisés dans
le chemin depuis la racine. (Critère d'un bon arbre de
décision)
L'entropie est utilisée pour mesurer la
quantité d'information apportée par un noeud. (Cette notion a
été introduite par Claude Shannon lors de ses recherches
concernant la théorie de l'information qui sert de base à
énormément de méthodes du data mining.)
Un arbre de décision peut être exploité de
différentes manières :
Ø En y classant de nouvelles données (un noeud
racine par lequel entre les enregistrements),
Ø En faisant de l'estimation d'attribut,
Ø En extrayant un jeu de règles de
classification concernant l'attribut cible,
Ø En interprétant la pertinence des attributs de
noeuds feuilles qui correspondent à un classement.
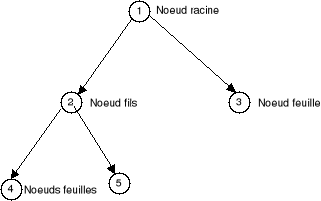
Fig.4 Les arbres de
décision
A. L' Algorithme de CART
Cet algorithme a été publié en 1984 par
L.Briemen. Il est utilisé dans de nombreux outils du marché.
Processus
Ø Trouver la première bifurcation,
Ø Développer l'arbre complet,
Ø Mesurer le taux d'erreur à chaque noeud,
Ø Calculer le taux d'erreur de l'arbre entier,
Ø Elaguer,
Ø Identifier les sous-arbres,
Ø Evaluer les sous-arbres,
Ø Evaluer le meilleur sous-arbre.
La première bifurcation est celle qui divise le mieux
les enregistrements en groupes. Ainsi pour déterminer le critère
qui effectuera le meilleur partage entre les éléments, un indice
de diversité est calculé, selon la formule suivante :
Max. de : diversité (avant division) -
(diversité fils gauche + diversité fils droit)
Il existe différents modes de calcul pour l'indice de
diversité :
Ø Min. (Probabilité(c1),
Probabilité(c2)),
Ø 2 Probabilité(c1)Probabilité(c2),
Ø
(Probabilité(c1)logProbabilité(c1))+Probabilité(c2)logProbabilité(c2))
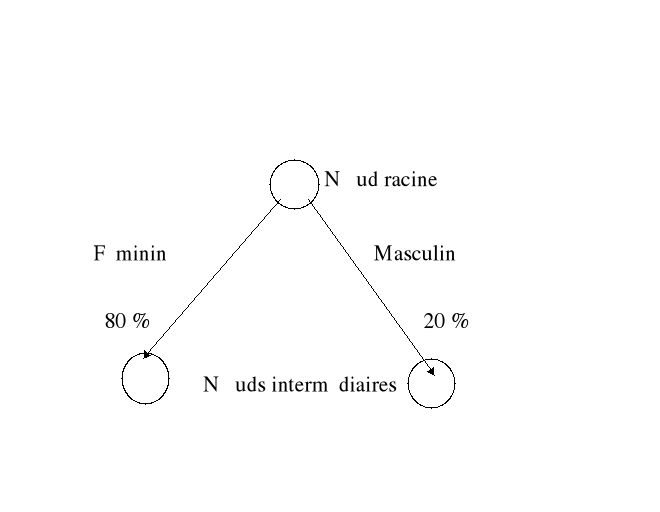
Fig : 5 L' Algorithme de
CART
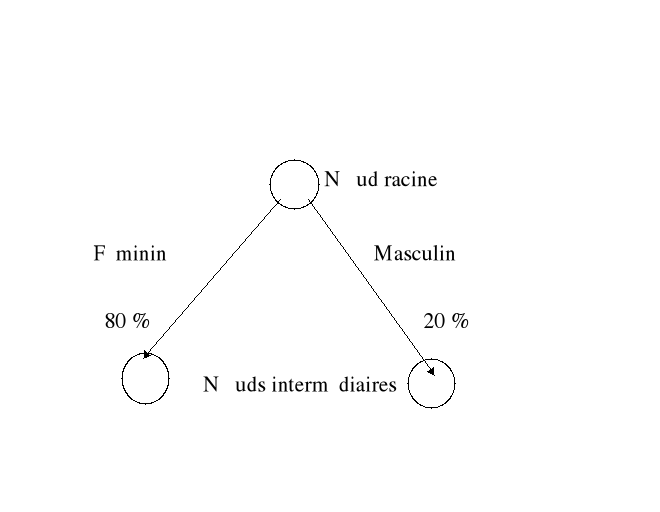
Une fois la première bifurcation établie, nous
avons donc le noeud racine qui se sépare en deux. L'étape
suivante est donc de développer l'arbre complet en divisant de la
même façon les nouveaux noeuds crées, et ainsi de suite
tant que le résultat de la division a une valeur significative. Le
dernier noeud étant le noeud feuille qui donne le classement final d'un
enregistrement.
L'arbre résultant n'est pas obligatoirement le
meilleur, la prochaine étape est de calculer le taux d'erreur pour
chaque noeud. Si nous supposons que 11 enregistrements sur 15 sont
classés correctement d'après l'ensemble d'apprentissage, la
probabilité pour ce noeud est de 11/15 soit 0,7333. Le taux d'erreur
attribué est de 1 - 0,7333 = 0,2667.
Le calcul du taux d'erreur de chaque noeud étant fait,
il est possible de calculer le taux d'erreur de l'arbre entier soit :
t : taux d'erreur d'un noeud
P : probabilité d'aller au noeud
Taux d'erreur de l'arbre = (t * P)
Soit dans l'exemple, avec un taux d'erreur de (15/17) pour le
noeud Masculin
((11/15) * 0,80) + ((15/17) * 0,20) = 0,763
Le danger de l'arbre de décision, tel qu'il est
constitué à l'issue du premier passage, est que certains noeuds
feuilles ne contiennent pas suffisamment d'enregistrements pour être
significatifs. Il faut élaguer, le plus complexe étant de trouver
la bonne limite à appliquer.
Le choix des branches à supprimer, se fait par
l'intermédiaire du taux d'erreur ajusté d'un arbre qui se
calcule, sur chaque sous arbre possible, comme suit :
Soit le compte des feuilles
Taux d'erreur ajusté = taux d'erreur + compte des
feuilles
Un premier sous arbre est candidat lorsque son taux d'erreur
ajusté devient plus petit ou égal au taux d'erreur ajusté
de tout l'arbre. Toutes les branches, qui n'en font pas partie, sont
élaguées, et le processus recommence ainsi de suite jusqu'au
noeud racine.
Il faut donc maintenant choisir parmi tous les sous arbres
candidats. Pour cela, chaque sous arbre va être exécuter avec un
ensemble de test, celui qui aura le plus petit taux d'erreur sera
considéré comme le meilleur.
Enfin pour contrôler l'efficacité du sous arbre
sélectionné, un ensemble d'évaluation va lui être
soumis. Son taux d'erreur obtenu donnera une estimation des performances de
l'arbre.
Tout d'abord, CHAID utilise pour choisir les bifurcations le
test du chi-2, que l'on ne détaillera pas ici.
Et enfin, contrairement aux autres il ne développe pas
l'arbre complet, pour ensuite l'élaguer, mais tente dès le
premier passage de limiter sa croissance.
B. L'Algorithme ID3
Le principe de l'algorithme ID3 pour déterminer
l'attribut à placer à la racine de l'arbre de décision
peut maintenant être exprimée : rechercher l'attribut qui
possède le gain d'information maximum, le placer en racine, et
itérer pour chaque fils, c'est à dire pour chaque valeur de
l'attribut. Cela étant dit, on peut donner L'ALGORITHME
ID3.
entrées : ensemble d'attributs A;
échantillon E; classe c
début
initialiser à l'arbre vide;
si tous les exemples de E ont la
même classe c
alors étiqueter la racine par
c;
sinon si l'ensemble des attributs A
est vide
alors étiqueter la
racine par la classe majoritaire dans E;
sinon soit a le meilleur
attribut choisi dans A;
étiqueter la racine par
a;
pour toute valeur v
de a
construire une branche
étiquetée par v;
soit Eav l'ensemble des exemples tels
que e(a) = v;
ajouter l'arbre construit par
ID3(A-{a}, Eav, c);
finpour
finsinon
finsinon
retourner racine;
fin
| 

