Effet de la gouvernance sur l'attractivité des ide dans l'espace UEMOApar Babylas TEKO École Nationale d'Economie Appliquée et de Management (ENEAM) - Licence 2021 |

1.3.2. Les six Worldwide Governance Indicators (WGI)Les indicateurs mondiaux de gouvernance (Worldwide GovernanceIndicators (WGI)) de la Banque mondiale rendent compte de six grandes dimensions de la gouvernance pour plus de 200 pays et territoires :i)Voix et responsabilité ; ii)Stabilité politique et absence de violence ; iii)Efficacité du gouvernement ; iv)Qualité de la réglementation ; v)État de droit et vi)Contrôle de la corruption. Leii) et le vi)sont ceux utilisés dans ce travail : *La stabilité politique et l'absence de violence/terrorismemesure les perceptions de la probabilité d'instabilité politique et/ou de violence à motivation politique, y compris le terrorisme. *Le contrôle de la corruption saisit les perceptions de la mesure dans laquelle le pouvoir public est exercé à des fins de gain privé, y compris les formes de corruption, petites et grandes, ainsi que la `'capture'' de l'État par les élites et les intérêts privés. Les WGI sont des indicateurs composites de gouvernance basés sur plus de 30 sources de données sous-jacentes.Ces sources de données sont redimensionnées et combinées pour créer les six indicateurs agrégés à l'aide d'une méthodologie statistique3(*) connue sous le nom de modèle àcomposantes non observées.L'une des principales caractéristiques de cette méthodologie est qu'elle génère des marges d'erreur pour chaque estimation de la gouvernance.Ces marges d'erreur doivent être prises en compte lors des comparaisons entre pays et dans le temps. Le WGI s'appuie sur quatre différents types de sources de données : ï Des enquêtes auprès des ménages et des entreprises, dont les enquêtes Afrobarometer, Gallup World Poll, et l'enquête Global Competitiveness Report, ï Des fournisseurs d'informations commerciales, dont le Economist Intelligence Unit, IHS Markit, Political Risk Services, ï Des organisations non gouvernementales, dont Global Integrity, Freedom House, Reporters WithoutBorders, ï Des organisations du secteur public, notamment les évaluations CPIA de la Banque mondiale et des banques régionales de développement, le rapport de transition du EBRD, la base de données des profils institutionnels du ministère français des Finances. Méthodologie d'agrégation du WGI : Chacune des six mesures agrégées du WGI est construite en faisant la moyenne des données provenant des sources sous-jacentes qui correspondent au concept de gouvernance mesuré. Cette opération est réalisée au cours des trois étapes décrites ci-dessous. ÉTAPE 1 : Affectation des données des sources individuelles aux six indicateurs agrégés Les questions individuelles des sources de données sous-jacentes sont affectées à chacun des six indicateurs agrégés. Par exemple, une question d'enquête sur l'environnement réglementaire sera affectée à la Qualité de la réglementation, ou une mesure de la liberté de la presse sera affectée à Voix et responsabilité. Notez que toutes les sources de données ne couvrent pas tous les pays, et que les scores agrégés de gouvernance sont donc basés sur différents ensembles de données sous-jacentes pour différents pays. ÉTAPE 2 : Redimensionnement préliminaire des données des sources individuelles pour qu'elles aillent de 0 à 1 Les questions des sources de données individuelles sont d'abord redimensionnées pour aller de 0 à 1, les valeurs les plus élevées correspondant à de meilleurs résultats. Si, par exemple, une question d'enquête demande des réponses sur une échelle allant d'un minimum de 1 à un maximum de 4, nous redimensionnons un score de 2comme suit : (2-min)/(max-min)=(2-1)/3 = 0,33. Lorsqu'une source de données individuelle fournit plus d'une question relative à une dimension particulière de la gouvernance, nous faisons la moyenne des scores rééchelonnés. Bien que nominalement dans les mêmes unités0-1,
les données rééchelonnées ne sont pas
nécessairement comparables entre les sources. Par exemple, une source de
données peut mesurer les perceptions de la corruption sur une
échelle de0 à 3, tandis qu'une autre peut le faire sur une
échelle de1 à 10. Ou, plus subtilement, deux sources de
données peuvent toutes deux utiliser une échelle allant
théoriquement de 0 à 1, mais pour l'une, dans la pratique, la
plupart des scores sont regroupés entre 0,3 et 0,7 ; tandis que
pour l'autre, les scores sont regroupés entre0 et 1.Si la remise
à l'échelle max-min ci-dessus ne corrige pas cette source de
non-comparabilité, la procédure utilisée pour construire
les indicateurs agrégés le fait.Dans cette méthodologie,
ces différences dans le choix explicite et implicite des unités
dans les données observées de chaque source sont capturées
par les différences entre les sources dans
les paramètres ÉTAPE 3 : Utilisation d'un modèle à composantes non observées pour construire une moyenne pondérée des indicateurs individuels pour chaque source. Un outil statistique connu sous le nom de modèle à composantes non observées(UnobservedComponentsModel(UCM)enanglais) est utilisé pour rendre les données rééchelonnées de0 à 1comparables entre les sources, puis pour construire une moyenne pondérée des données de chaque source pour chaque pays. L'UCM part du principe que les données observées de chaque source sont une fonction linéaire du niveau de gouvernance non observé, plus un terme d'erreur. Cette fonction linéaire est différente pour les différentes sources de données, et corrige ainsi la non-comparabilité des unités des données redimensionnées notée ci-dessus. Les estimations de la gouvernance qui en résultent sont une moyenne pondérée des données de chaque source, les pondérations reflétant le modèle de corrélation entre les sources de données. Pour chacune des six composantes de la gouvernance, on suppose
qu'on peut écrire le score observé du paysjsur
l'indicateurk, (1) Où Le terme d'erreur Compte tenu des estimations des paramètres du
modèle, (2) On utilise cette moyenne conditionnelle comme l'estimation de
la gouvernance. Il s'agit simplement d'une moyenne pondérée des
scores rééchelonnés pour chaque pays, Une observation cruciale cependant est qu'il existe une incertitude inévitable autour de cette estimation de la gouvernance. Cette incertitude est capturée par l'écart-type de la distribution de la gouvernance conditionnelle aux données observées : (3) Cet écart-type est d'autant plus faible que le nombre
de sources de données k disponibles pour un pays est
élevé, et que les sources de données individuelles sont
précises, c'est-à-dire Les mesures composites de la gouvernance générées par l'UCM sont exprimées en unités d'une distribution normale standard, avec une moyenne de0,un écart-type de1, et allant d'environ-2,5 à +2,5 ; les valeurs les plus élevées correspondant à une meilleure gouvernance. Les données sont également présentées en termes de rang centile, allant de0 (rang le plus bas) à 100 (rang le plus élevé). Dans la suite, le cadre théorique de la recherche composé d'éléments d'un protocole de recherche et la revue de littérature. Chapitre 2 : Cadre théorique * 3Cette méthodologie est celle décrite sur le site de WGI à l'adresse suivante : https://info.worldbank.org/governance/wgi/Home/Documents |
|



 et
et 
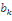 ci-dessous.
ci-dessous.
 ,comme une fonction linéaire de la gouvernance non
observée dans le paysj,
,comme une fonction linéaire de la gouvernance non
observée dans le paysj,
 ,et un terme de perturbation,
,et un terme de perturbation, 
 comme suit :
comme suit :
 +
+ 
 (
(
 +
+
 )
)
 et
et
 sont des paramètres qui mettent en correspondance la gouvernance
non observée dans le paysj,
sont des paramètres qui mettent en correspondance la gouvernance
non observée dans le paysj,
 , avec les données observées de la sourcek,
, avec les données observées de la sourcek, 
 . Nous pouvons alors utiliser les estimations de ces paramètres
pour rééchelonner les données de chaque source en
unités communes. Comme choix inoffensif d'unités, nous supposons
que
. Nous pouvons alors utiliser les estimations de ces paramètres
pour rééchelonner les données de chaque source en
unités communes. Comme choix inoffensif d'unités, nous supposons
que
 est une variable aléatoire normalement distribuée avec une
moyenne0 et de variance1.Nous supposons que le terme d'erreur est
également normalement distribué, avec une moyenne nulle et une
variance qui est la même dans tous les pays, mais diffère selon
les indicateurs, c'est-à-dire :
est une variable aléatoire normalement distribuée avec une
moyenne0 et de variance1.Nous supposons que le terme d'erreur est
également normalement distribué, avec une moyenne nulle et une
variance qui est la même dans tous les pays, mais diffère selon
les indicateurs, c'est-à-dire : 
 . Nous supposons également que les erreurs sont
indépendantes entre les sources, c'est-à-dire que
. Nous supposons également que les erreurs sont
indépendantes entre les sources, c'est-à-dire que
 ]
] 
 0pour la sourcemdifférente de la sourcek. Cette hypothèse
d'identification affirme que la seule raison pour laquelle deux sources peuvent
être corrélées chacune avecl'autre est qu'elles mesurent
toutes deux la même dimension sous-jacente non observée de la
gouvernance.
0pour la sourcemdifférente de la sourcek. Cette hypothèse
d'identification affirme que la seule raison pour laquelle deux sources peuvent
être corrélées chacune avecl'autre est qu'elles mesurent
toutes deux la même dimension sous-jacente non observée de la
gouvernance.
 capture deux sources d'incertitude dans la relation entre la vraie
gouvernance et les indicateurs observés. Premièrement, l'aspect
particulier de la gouvernance couvert par l'indicateurkpourrait être
imparfaitement mesuré dans chaque pays, reflétant soit des
erreurs de perception de la part des experts (dans le cas de sondages
d'experts), soit une variation d'échantillonnage (dans le cas
d'enquêtes auprès de citoyens ou d'entrepreneurs).
Deuxièmement, la relation entre le concept particulier mesuré par
l'indicateurket l'aspect plus large correspondant de la gouvernance peut
être imparfaite.Par exemple, même si l'aspect particulier de la
corruption couvert par un certain indicateurk,(tel que la prévalence des
"pratiques irrégulières") est parfaitement mesuré, il peut
néanmoins être un indicateur bruyant de la corruption s'il existe
des différences entre les pays dans ce que l'on considère comme
des "pratiques irrégulières".Ces deux sources d'incertitude sont
reflétées dans la variance spécifique à
l'indicateur du terme d'erreur,
capture deux sources d'incertitude dans la relation entre la vraie
gouvernance et les indicateurs observés. Premièrement, l'aspect
particulier de la gouvernance couvert par l'indicateurkpourrait être
imparfaitement mesuré dans chaque pays, reflétant soit des
erreurs de perception de la part des experts (dans le cas de sondages
d'experts), soit une variation d'échantillonnage (dans le cas
d'enquêtes auprès de citoyens ou d'entrepreneurs).
Deuxièmement, la relation entre le concept particulier mesuré par
l'indicateurket l'aspect plus large correspondant de la gouvernance peut
être imparfaite.Par exemple, même si l'aspect particulier de la
corruption couvert par un certain indicateurk,(tel que la prévalence des
"pratiques irrégulières") est parfaitement mesuré, il peut
néanmoins être un indicateur bruyant de la corruption s'il existe
des différences entre les pays dans ce que l'on considère comme
des "pratiques irrégulières".Ces deux sources d'incertitude sont
reflétées dans la variance spécifique à
l'indicateur du terme d'erreur,
 .Plus cette variance est faible, plus un signal précis de
gouvernance est fourni par la source de données correspondante.
.Plus cette variance est faible, plus un signal précis de
gouvernance est fourni par la source de données correspondante.
 ,
, 
 et
et 
 , on peut maintenant construire des estimations de la gouvernance
inobservée
, on peut maintenant construire des estimations de la gouvernance
inobservée
 , étant donné les données observées
, étant donné les données observées
 pour chaque pays. En particulier, le modèle des composantes
inobservées nous permet de résumer nos connaissances sur la
gouvernance inobservée dans le paysjen utilisant la
distribution de
pour chaque pays. En particulier, le modèle des composantes
inobservées nous permet de résumer nos connaissances sur la
gouvernance inobservée dans le paysjen utilisant la
distribution de
 conditionnelle aux données observées
conditionnelle aux données observées
 . Cette distribution est également normale, avec la moyenne
suivante :
. Cette distribution est également normale, avec la moyenne
suivante :
 ,...,
,..., 
 ]
] 


 Cette remise à l'échelle place les données
observées de chaque source dans les unités communes choisies pour
la gouvernance non observée. Les poids attribués à
chaque sourceksont donnés par
Cette remise à l'échelle place les données
observées de chaque source dans les unités communes choisies pour
la gouvernance non observée. Les poids attribués à
chaque sourceksont donnés par
 ,et sont d'autant plus grandes que la variance du terme d'erreur de la
source est faible. En d'autres termes, les sources qui fournissent un signal de
gouvernance plus informatif reçoivent un poids plus élevé.
Bien que cette pondération améliore la précision
statistique des indicateurs agrégés, elle n'affecte
généralement pas beaucoup le classement des pays sur les
indicateurs agrégés.
,et sont d'autant plus grandes que la variance du terme d'erreur de la
source est faible. En d'autres termes, les sources qui fournissent un signal de
gouvernance plus informatif reçoivent un poids plus élevé.
Bien que cette pondération améliore la précision
statistique des indicateurs agrégés, elle n'affecte
généralement pas beaucoup le classement des pays sur les
indicateurs agrégés.
 ,...,
,..., 
 ]
] 


 est petit. Nous appelons ce nombre comme "l'erreur standard" de notre
estimation de la gouvernance pour chaque pays. Ces erreurs standard sont
essentielles à l'interprétation correcte de nos estimations de la
gouvernance, car elles capturent l'incertitude inhérente à la
mesure de la gouvernance. Par exemple, lorsque nous comparons les estimations
de la gouvernance pour deux pays ou pour un seul pays, nous indiquons toujours
l'intervalle de confiance à90 %associé aux deux estimations de
la gouvernance, c'est-à-dire l'estimation de la gouvernance+/- 1,64fois
son écart-type. Cette fourchette, que nous appelons "marge d'erreur"
pour le score de gouvernance, a l'interprétation suivante : sur la base
des données observées, nous pouvons être sûrs
à90 %que le véritable niveau de gouvernance, mais non
observé, des pays se situe dans cette fourchette.
est petit. Nous appelons ce nombre comme "l'erreur standard" de notre
estimation de la gouvernance pour chaque pays. Ces erreurs standard sont
essentielles à l'interprétation correcte de nos estimations de la
gouvernance, car elles capturent l'incertitude inhérente à la
mesure de la gouvernance. Par exemple, lorsque nous comparons les estimations
de la gouvernance pour deux pays ou pour un seul pays, nous indiquons toujours
l'intervalle de confiance à90 %associé aux deux estimations de
la gouvernance, c'est-à-dire l'estimation de la gouvernance+/- 1,64fois
son écart-type. Cette fourchette, que nous appelons "marge d'erreur"
pour le score de gouvernance, a l'interprétation suivante : sur la base
des données observées, nous pouvons être sûrs
à90 %que le véritable niveau de gouvernance, mais non
observé, des pays se situe dans cette fourchette.