2.2. Approches de reconnaissance
Deux approches s'opposent en reconnaissance des mots : globale et
analytique. La figure n°1 nous montre comment réaliser un
système OCR.
2.2.1. Approche globale
L'approche globale se base sur une description unique de
l'image du mot, vue comme une entité indivisible. Disposant de beaucoup
d'informations, en effet, la discrimination de mots proches est très
difficile, et l'apprentissage des modèles nécessite une grande
quantité d'échantillons qui est souvent difficile à
réunir.
Cette approche est souvent appliquée pour
réduire la liste de mots candidats dans le contexte d'une reconnaissance
à grands vocabulaires. Il est nécessaire d'utiliser dans ce cas
des primitives très robustes (coarse features). Le mot reconnu est
ensuite trouvé à l'aide de primitives de plus en plus
précises (ou d'un classifieur de plus en plus fin). Cette combinaison de
classifieurs est appelée combinaison sérielle par Madvanath [S.
Madvanath & V. Govindaraju 1992], par opposition à la combinaison
parallèle où les sorties des classifieurs sont
considérées en même temps. Pour les vocabulaires
réduits et distincts (exemple: reconnaissance de montants
littéraux de chèques bancaires), cette approche reste
parfaitement
envisageable comme cela a été fait par Simon [J.
C. Simon 1992], Gilloux [M. Gilloux & M. Leroux 1993], Knerr [S. Knerr
& al. 1997], Guillevic [D. Guillevic and C. Suen 1997] et Saon [A.
Belaïd et G. Saon. 1997].
2.2.2. Approche analytique
L'approche analytique basée sur un découpage
(segmentation) du mot. La difficulté d'une telle approche a
été clairement évoquée par Sayre en 1973 et peut
être résumée par le dilemme suivant : "pour
reconnaître les lettres, il faut segmenter le
tracé et pour segmenter le tracé, il faut
reconnaître les lettres". Il s'ensuit qu'un processus de reconnaissance
selon cette approche doit nécessairement se concevoir comme un processus
de relaxation alternant les phases de segmentation et d'identification des
segments. La solution communément adoptée consiste à
segmenter le mot manuscrit en parties inférieures aux lettres
appelés graphèmes et à retrouver les lettres puis le mot
par combinaison de ces graphèmes. C'est une méthode de
segmentation explicite qui s'oppose à la segmentation interne où
la reconnaissance des lettres s'opère sur des hypothèses de
segmentation variables (générées en fonction des
observations courantes) [R. G. Casey and E. Lecolinet 1995]. Cette approche est
la seule applicable dans le cas de grands vocabulaires.
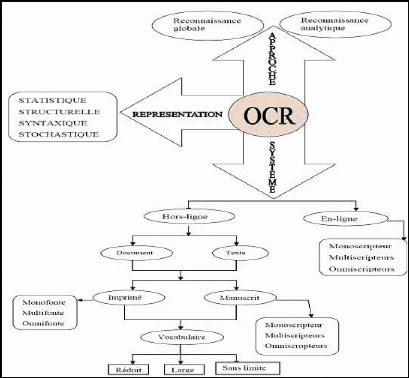
Figure 1: Différents systèmes,
représentations et approches de reconnaissance.
2.2.3. Problématique de l'approche
analytique
L'approche analytique présente quelques
problèmes au niveau de la localisation. Sayre en 1973 a
évoqué le dilemme suivant : «Pour apprendre les
modèles de lettres il faut pouvoir localiser ces
dernières, et pour les localiser il faut avoir appris
les modèles des lettres ». On distingue alors trois grandes voies
de segmentations :
ü segmentation explicite : segmentation sur des
critères topologiques (Figure 2a)
ü segmentation implicite : segmentation d'après les
modèles de lettres (Figure 2b)
ü sans segmentation : détection de la
présence d'une lettre (Figure 2c)

Figure 2 : Exemples de Segmentations [A. Belaïd 2002].
a. Segmentation explicite
L'avantage de cette segmentation c'est que l'information est
localisée explicitement et ça va dans le sens de Sayre puisque on
sépare les lettres non pas d'après leur reconnaissance, mais
d'après des critères topologiques ou morphologiques.
Le défaut majeur de cette segmentation vient en
premier lieu de choix des limites indépendant des critères des
modèles : les limites sous-optimales pour les modèles et
modélisation sous-optimale. En deuxième lieu il n'existe pas de
méthode de segmentation fiable à 100% et pour toute erreur de
segmentation pénalise le système dès la base.
La segmentation explicite n'est pas parfaite pour un
système de reconnaissance des mots manuscrite [A. Belaïd 2002].
b. Segmentation implicite
L'avantage de cette segmentation c'est que l'information est
localisée par les modèles des lettres et la validation se fait
par ses modèles. Il n'y aura pas d'erreur de segmentation et enfin on
contourne le dilemme de Sayre car en connaissant les lettres, on n'engendre pas
d'erreur de segmentation.
Les défauts de cette segmentation viennent du fait que
l'espace de recherche des limites se trouve très augmenté et le
problème est ramené à un problème de recherche de
zones où se trouvent ces limites, reposant le problème de Sayre
sur les zones.
Cette segmentation présente des avantages et des
inconvénients ce qui fait que cette approche est insuffisante pour une
modélisation optimale de l'écriture [Belaïd A. 2002].
c. Sans segmentation
Les avantages de cette segmentation c'est qu'elle
résout tous les problèmes d'optimalité cités, elles
ne délimitent pas les lettres, elles ont une vision globale des mots, et
donc écartent la sous-optimalité de la segmentation.
Les principaux défauts c'est qu'elle pose le
problème de l'optimalité de l'apprentissage des lettres :
c'est-à-dire comment apprendre correctement sans délimiter
correctement, cela repousse le problème d'optimalité au niveau de
l'apprentissage.
Cette approche reste la seule approche optimale
vis-à-vis des mots elle nécessite cependant un apprentissage
adéquat pour conserver l'optimalité : l'effort portera sur ce
point [Belaïd A., 2002].
| 

