3. Problèmes liés à l'OCR
La tâche de l'OCR n'est pas aisée, La figure
n°3 nous montre un schéma général d'un système
de reconnaissance de caractères. Des divers problèmes compliquent
le processus de reconnaissance, parmi lesquels on peut citer [Al-Badr 1995],
[Ben Amara N. 1999]:
V' La qualité du document : un document
télécopié ou photocopié plusieurs fois est plus
difficile à traiter que la copie originale. L'écriture peut
devenir plus mince ou au contraire plus épaisse, dégradée
avec des parties du texte qui manquent ou de tâches qui apparaissent, des
ouvertures ou des bouchages de boucles ...
V' L'impression : un document composé est de meilleure
qualité qu'un document dactylographié qui, à son tour, est
plus clair qu'un texte issu d'une imprimante matricielle. Une imprimante
à jet d'encre peut introduire des tâches d'encre et un
étalement des caractères, une imprimante laser peut
générer des lignes ou des fonds ...
V' La discrimination de la forme : selon le style de la fonte
utilisée, son corps et sa graisse..., le caractère change de
graphisme. Le nombre de formes est d'autant plus important que le nombre de
styles d'écriture est élevé. De plus, plusieurs
caractères présentent une forte ressemblance tels que:
pour l'arabe: bet , .et ?~? et j
pourleLatin:UetV,Oet0,Set5,Zet2.
V' Le support de l'information, tel que le papier, joue
également sur les performances
de la reconnaissance par sa
qualité: son grammage, sa granulation et sa couleur.
V' L'acquisition: la numérisation en temps réel
introduit souvent des distorsions dans l'image. Dans le cas hors-ligne la
qualité du texte numérisé est un compromis entre les
variations de la position (inclinaison, translation,
rétrécissement...), la propreté de la vitre du dispositif
de numérisation et sa résolution.
V' Les variations des dimensions : un «pitch » de
10, 12 ou de 16 ... (10, 12 ou 16 cpi (character per inch)). Un pitch de 10
implique des caractères plus grands aussi bien en largeur qu'en hauteur
que ceux d'un pitch de 12.
En plus de ces problèmes un système OCR devrait
être capable de distinguer entre un texte et une figure, de
reconnaître les caractères ligaturés et d'être
indépendant des variations de l'espace aussi bien inter-mots que de
l'interligne.
Les problèmes posés par la reconnaissance
optique de l'écriture manuscrite, sont plus complexes que ceux
liés à l'écriture imprimée. Les erreurs de lecture
dans le cas du manuscrit sont dues aux variations infinies de l'écriture
de nature aléatoire qui dépendent de facteurs particuliers du
scripteur et des conditions de l'écriture.
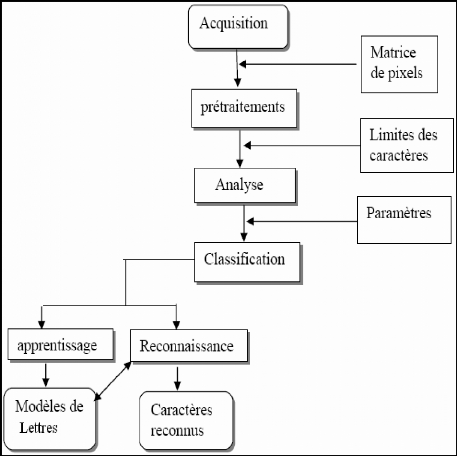
Figure 3 : Schéma général d'un
système de reconnaissance de caractères.
4. Processus de reconnaissance
Un système de reconnaissance fait appel
généralement aux étapes suivantes : acquisition,
prétraitements, segmentation, extraction des caractéristiques,
classification, suivis éventuellement d'une phase de post-traitement.
4.1. Phase d'acquisition
L'acquisition permettant la conversion du document papier sous
la forme d'une image numérique (bitmap). Cette étape est
importante car elle se préoccupe de la préparation des documents
à saisir, du choix et du paramétrage du matériel de saisie
(scanner), ainsi que du format de stockage des images.
La numérisation du document est opérée
par balayage optique. Le résultat est rangé dans un fichier de
points, appelés pixels, dont la taille dépend de la
résolution [Belaïd A. 1995]. La Figure 4 montre différents
niveaux de résolution utilisés pour le même document. On
peut remarquer la dégradation occasionnée par 75 ppp,
l'insuffisance des 300 ppp pour le graphique, et l'inutilité des 1200
ppp pour l'ensemble.
La technicité des matériels d'acquisition
(scanner) a fait progrès ces dernières années. On trouve
aujourd'hui des scanners pour des documents de différents types
(feuilles, revues, livres, photos, etc.). Leur champ d'application va du "scan"
de textes au "scan" de photos en 16 millions de couleurs (et même plus
pour certains). La résolution par défaut est de l'ordre de 300
à 1200 ppp selon les modèles.
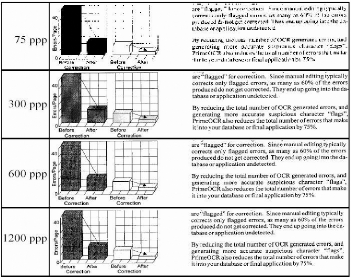
Figure 4 : Différents niveaux de résolution [A.
Belaïd et Y. Belaïd 1992]
4.2. Phase de prétraitement
Le prétraitement consiste à préparer les
données issues du capteur à la phase suivante. Il s'agit
essentiellement de réduire le bruit superposé aux données
et essayer de ne garder que l'information significative de la forme
représentée. Le bruit peut être dû aux conditions
d'acquisition (éclairage, mise incorrecte du document, ...) ou encore
à la qualité du document d'origine.
Parmi les opérations de prétraitement
généralement utilisées on peut citer : l'extraction des
composantes connexes, le redressement de l'écriture, le lissage, la
normalisation et la squelettisation (figure 5).
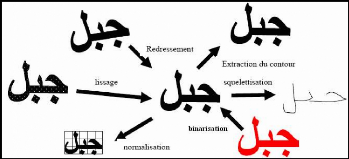
Figure 5 : effets de certaines opérations de
prétraitement. a. La binarisation
La binarisation c'est le passage d'une image en couleur ou
définie par plusieurs niveaux de gris en image bitonale (composée
de deux valeurs 0 et 1) qui permet une classification entre le fond (image du
support papier en blanc) et la forme (traits des gravures et des
caractères en noir).
Pour des images de niveaux de gris, on peut trouver dans [O.
D. Trier & T. Taxt 1995] une liste des méthodes de binarisation,
proposant des seuils adaptatifs (ex. s'adaptant à la différence
de distribution des niveaux de gris). [Y. Liu & S. Srihari 1997] proposent
une solution pour les images d'adresses postales. La recherche du seuil passe
par plusieurs étapes : binarisation préliminaire basée sur
une distribution de mixture multimodale, analyse de la texture à l'aide
d'histogrammes de longueurs de traits, et sélection du seuil à
partir d'un arbre de décision.

Figure 6 : Exemple de Binarisation adaptative [H. Emptoz & F.
Lebougoies 2003]
b. Extraction de composantes connexes
Une composante connexe (CXX) est un ensemble de points dans
le plan. Elle peut correspondre à un point diacritique, un accent, au
corps d'un caractère ou d'une chaîne de caractères... Une
fois localisés les CXX sont regroupées pour former les mots.
Cette technique est utilisée pour le repérage des points
diacritiques dans les images de textes arabes [N. Ben Amara 1999].
c. Redressement de l'écriture
L'un des problèmes rencontrés en OCR est
l'inclinaison des lignes du texte, qui introduit des difficultés pour la
segmentation. L'inclinaison peut provenir de la saisie, si le document a
été placé en biais, ou être intrinsèque au
texte. Il convient alors de le redresser afin de retrouver la structure de
lignes horizontales d'une image texte. Si á est l'angle d'inclinaison,
pour redresser l'image, une rotation isométrique d'angle -á est
opérée grâce à la transformation linéaire
suivante [Steinherz 1999] :
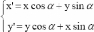
d. Lissage
L'image des caractères peut être
entachées de bruits dus aux artefacts de l'acquisition et à la
qualité du document, conduisant soit à une absence de points ou
à une surcharge de points. Les techniques de lissage permettent de
résoudre ces problèmes par des opérations locales qu'on
appelle opérations de bouchage et de nettoyage [Burrow 2004].
L'opération de nettoyage permet de supprimer les
petites tâches et les excroissances de la forme. Pour le bouchage il
s'agit d'égaliser les contours et de boucher les trous internes à
la forme du caractère en lui ajoutant des points noirs.
Plusieurs autres techniques similaires sont utilisées
dont la méthode statistique, une méthode basée sur la
morphologie mathématique [N. Ben Amara 1999].
e. Normalisation
Après la normalisation de la taille, les images de tous
les caractères se retrouvent définies dans une matrice de
même taille, Pour faciliter les traitements ultérieurs (Figure
n° 7).
Le principe de la normalisation est d'essayer de normaliser
localement différentes parties du mot, de manière à
augmenter la ressemblance d'une image à une autre.
Cette opération introduit généralement de
légères déformations sur les images. Cependant certains
traits caractéristiques tels que la hampe dans les caractères
(Ø Ù á Ç par exemple) peuvent être
éliminées à la suite de la normalisation, ce qui peut
entraîner à des confusions entre certains caractères
[Steinherz 1999].

Figure 7 : Exemple de normalisation de mots manuscrits [A.
Belaïd 2002]. f. Squelettisation
Le but de cette technique est de simplifier l'image du
caractère en une image à « ligne » plus facile à
traiter en la réduisant au tracé du caractère. Les
algorithmes de squelettisation se basent sur des méthodes
itératives. Le processus s'effectue par passes successives pour
déterminer si un tel ou tel pixel est essentiel pour le garder ou non
dans le tracé [Steinherz 1999].
La squelettisation des caractères arabes peut induire en
erreur : deux points diacritiques sont souvent confondus avec un seul [N. Ben
Amara 1999].
| 
