4. Conclusion
Nous avons présenté dans ce chapitre les
différents aspects du développement de notre système. Nous
avons décrit précisément notre système et nous
avons montré le mécanisme de reconnaissance des mots manuscrits.
Notre système a permis d'obtenir des bons résultats au niveau de
la reconnaissance. Pour valider et tester notre système nous allons
l'implémenter dans une école qui enseigne des personnes
âgées et nous nous contenterons d'évaluer les examens des
élèves.
Chapitre
4
|
Application du
système « RIMA »
dans une école pour
l'enseignement des
âgés
|
Objectifs du chapitre
Nous présentons dans ce chapitre les résultats
des expériences effectuées dans une école qui enseigne des
personnes âgées. Nous s'intéresserons sur la correction
automatique des examens sans intervention humaine. Nous présentons aussi
une extension du système «RIMA» qui effectuera la correction
des examens. Nous montrons que notre système peut s'applique dans
l'enseignement assisté par ordinateur.
1. Extension du système « RIMA »
1.1.Présentation
Nous avons ajouté une extension au système
« RIMA » qui se base sur la reconnaissance des mots manuscrits avec
un processus de post-traitement supervisé. Cette extension du
système accepte en entrée des copies de plusieurs
élèves et qui se charge de les traiter une par une. Chaque copie
sera subdivisée en plusieurs images, ces dernières seront
envoyées au système « RIMA » pour l'évaluation
et enfin le résultat obtenu sera retourné à la l'extension
du système. La figure 24 montre le processus de d'évaluation des
copies des examens.
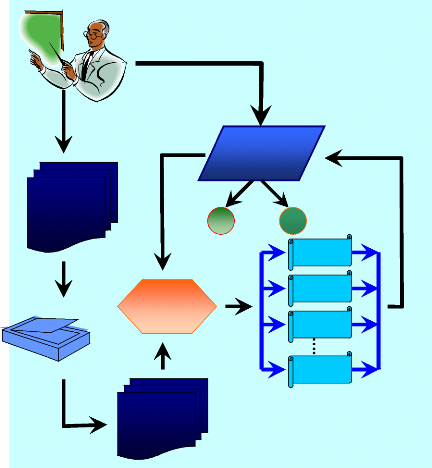
Dicte une l ste des mots aux élèves
Copies des
élèves
scanner
Copies des
élèves
(images)
Extension
de RIMA
Envoi la liste des mots dictés
Mot incorrect Mot correct
O 1
RIMA
Sous Système
de
reconnaissance
Mot n°n
Mot n°1
Mot n°2
Mot n°3
Figure 24 : Processus d'évaluation des examens
1.2.Description détaillée
Dans une première étape nous devons demander aux
élèves d'écrire les 122 formes des lettres dans les
différentes positions, ensuite nous devons les scanner et les passer aux
sous- système d'apprentissage afin de créer notre base de
données.
Dans une deuxième étape l'instituteur dicte
à ces élèves une liste de mots, ces derniers doivent
être écrit séparément et l'un au dessous de l'autre
dans un périmètre fixé dans la copie afin de localiser les
mots manuscrites dans la copie. Une fois cette étape est
terminée, l'instituteur scanne toutes les copies et les ranges dans le
disque dur. Chaque image (copie) sera subdivisé en plusieurs sous images
qui seront traité une par une par notre système « RIMA
» et qui donnera pour chaque image traité le résultat (1
s'il le mot en question correspond à celui entré par
l'instituteur OU 0 si le mot n'est pas reconnu) ainsi qu'il nous donnera les
lettres reconnues et les lettres non reconnues. L'extension du système
se charge de compter les scores des points afin d'attribuer pour chaque copie
une note.
Voici dans ce qui ce qui suit un algorithme du processus
d'évaluation des copies :
|
Algorithme ExRIMA
Début
Pour chaque copie de i à n faire
Subdiviser la copie en plusieurs sous image
Pour chaque image faire
Passer chaque image au système « RIMA »
avec le mot a reconnaître
LC (- Lettres reconnues
LNC (- Lettres non reconnues
X (- note de l'image obtenue par le système « RIMA
» NOTE[ i] (-NOTE[ i] +X
Fin Pour
Fin Pour
Afficher les notes des élèves
Fin
|
Note : Résultat vaut 1 s'il y 'a eu une reconnaissance et
0 sinon. 2. Test et expérience
2.1.Données d'expérience
Nous avons extrait 10 copies de 10 élèves qui
étudiaient dans une école pour l'enseignement des
âgées. Chaque copie contenait 10 mots qui sont
séparés les un des autres. D'abord nous avons demandé aux
élèves d'écrire dans une feuille les différentes
formes d'écriture des lettres manuscrites afin de construire une base
minimale d'apprentissage. Voici dans le tableau n°4 la base
d'apprentissage minimale d'un mono-scripteur et dans le tableau n°5 les
mots manuscrits des élèves qui sont dictés par
l'instituteur, et Voici dans la figure 25 un exemple d'une copie d'examen.
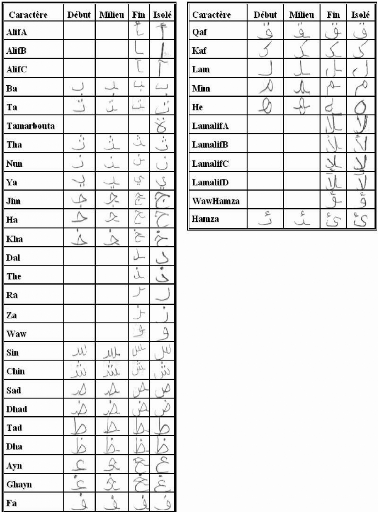
Tableau n°4: Base d'apprentissage minimale d'un
mono-scripteur
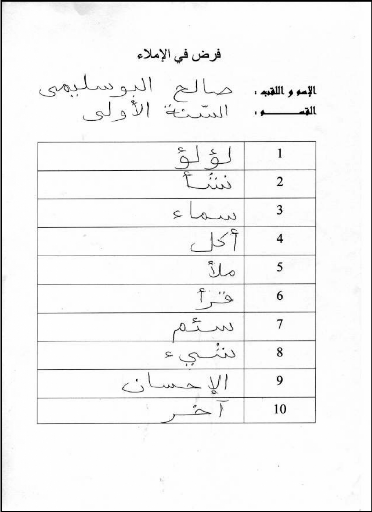
Figure 25 : Exemple d'une copie d'examen d'un
élève
Nous présentons dans le tableau n°5 les mots
manuscrits des élèves dictés par l'instituteur. Nous
allons tester notre système avec ces données pour voir le taux de
reconnaissance des mots manuscrits.
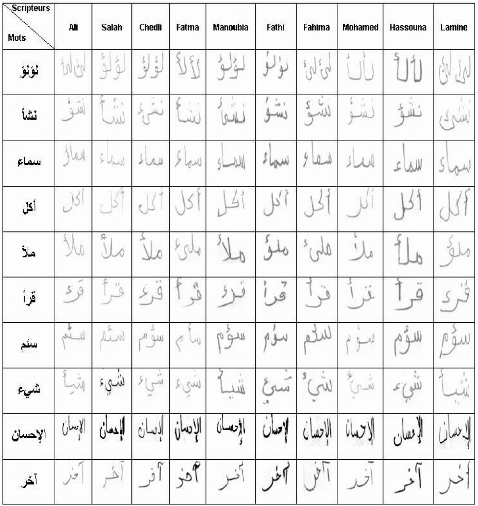
Tableau n°5 : Données d'expériences
2.2. Expérimentation
2.2.1.Post-traitement avec superviseur
Pour améliorer le taux d'erreur dans la correction des
mots reconnus par le système, nous avons mené une correction avec
un superviseur qui est l'utilisateur. Nous présentons dans
le tableau n°6 les résultats des essais
expérimentaux d'une étude expérimentale sur des mots
manuscrits arabe et nous se basons sur la reconnaissance système sans
savoir préalablement les mots prévus à avoir. Dans ce cas
notre système travaille dans un vocabulaire ouvert sans dictionnaire et
le correcteur n'est autre que l'utilisateur. Pour chaque échelle de
précisons de longueur 10%, nous présentons le taux et nombres de
mots correspondants.
|
Précision
|
Taux des mots
|
Nombre des mots
|
|
90%=p=100%
|
64%
|
64
|
|
80%<p<90%
|
9%
|
9
|
|
70%<p=80%
|
8%
|
8
|
|
60%<p=70%
|
5%
|
5
|
|
50%<p=60%
|
4%
|
4
|
|
40%<p=50%
|
4%
|
4
|
|
30%<p=40%
|
3%
|
3
|
|
20%<p=30%
|
2%
|
2
|
|
10%<p=20%
|
1%
|
1
|
|
0%<p=10%
|
0%
|
0
|
|
0%
|
0%
|
0
|
|
Totaux
|
100%
|
100
|
Tableau n°6 : Résultat d'expérimentation
| 

