2.2.2.Post-traitement sans superviseur
Dans une reconnaissance des mots manuscrits arabe avec la
prise en compte en entré des mots à avoir en sortis (le
dictionnaire), notre système permet d'enregistrer les lettres reconnues
ainsi les lettres reconnues afin de trouver à la fin le taux d'erreur.
Dans ce cas nous travaillons dans un espace limité puisqu'on
connaît le mot prévu à connaître et aussi les lettres
qui le composent. Notre étude nous a amené à un
résultat de précision qui est de 100%.
Notre étude menée a été
implémentée dans une école pour l'enseignement des
âgés, elle consiste à évaluer la vraisemblance
caractère par caractère (caractère acquis et le
caractère prévue). Notre système dépend ici de la
qualité d'acquisition d'image.
Notre système donne une statistique sur les mots reconnus
ainsi les lettres trouvées et lettres non reconnues.
2.3. Statistiques de reconnaissances
Nous présentons dans le tableau n°7 une
étude sur le nombre des mots reconnus, le nombre des lettres non
reconnues et les lettres reconnues des élèves. Nous
déduisons dans la figure 26 le taux d'erreur4 par mot de
chaque élève d'après le tableau statistique.
4 Taux d'erreur = T. Lettres Non Reconnues*100 / T.
Lettres
|
Scripteur
Mot
|
Ali
|
Salah
|
Che-
dli
|
Fat-
ma
|
Man-
oubia
|
Fathi
|
Fahi
ma
|
Moha
-med
|
Hass-
ouna
|
Lamine
|
|
|
M
|
L
|
L
|
M
|
L
|
L
|
M
|
L
|
L
|
M
|
L
|
L
|
M
|
L
|
L
|
M
|
L
|
L
|
M
|
L
|
L
|
M
|
L
|
L
|
M
|
L
|
L
|
|
ML
|
L
|
|
|
CCN
|
|
|
|
|
|
|
|
|
|
|
CCNCCNCCNCCNCCNCCN
|
|
|
|
|
|
|
|
|
|
|
|
CCNCCN
|
|
|
|
CC
|
N
|
|
|
|
C
|
|
|
C
|
|
|
|
C
|
|
C
|
|
|
C
|
|
|
C
|
|
|
C
|
|
|
C
|
|
|
C
|
|
|
C
|
|
91:91
|
0
|
2
|
2
|
1
|
4
|
0
|
0
|
2
|
2
|
0
|
2
|
2
|
1
|
4
|
0
|
0
|
2
|
2
|
0
|
2
|
2
|
0
|
2
|
2
|
0
|
2
|
2
|
0
|
2
|
2
|
|
Uzi
|
0
|
2
|
1
|
1
|
3
|
0
|
0
|
2
|
1
|
1
|
3
|
0
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
|
ÁL42
|
0
|
3
|
1
|
1
|
4
|
0
|
1
|
4
|
0
|
1
|
4
|
0
|
1
|
4
|
0
|
1
|
4
|
0
|
1
|
4
|
0
|
1
|
4
|
0
|
1
|
4
|
0
|
0
|
3
|
1
|
|
e
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
|
67
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
2
|
1
|
1
|
3
|
0
|
1
|
2
|
1
|
0
|
2
|
1
|
|
89
|
0
|
2
|
1
|
1
|
3
|
0
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
0
|
2
|
1
|
|
itatià
|
1
|
3
|
0
|
1
|
3
|
0
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
1
|
3
|
0
|
1
|
2
|
1
|
1
|
2
|
1
|
0
|
2
|
1
|
|
Á4-
|
0
|
2
|
1
|
1
|
3
|
0
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
0
|
2
|
1
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
0
|
2
|
1
|
|
äl.t.m.%1Ç
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
1
|
6
|
0
|
|
ÿî
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
1
|
3
|
0
|
|
|
526
|
|
|
130
|
|
|
526
|
|
|
635
|
|
|
635
|
|
|
526
|
|
|
834
|
|
|
834
|
|
|
835
|
|
|
32
|
8
|
|
|
9
|
|
|
05
|
|
|
9
|
|
|
0
|
|
|
1
|
|
|
9
|
|
|
1
|
|
|
1
|
|
|
0
|
|
|
7
|
|
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
NT
|
T
|
|
|
OLL
|
|
|
|
|
|
|
|
|
|
|
OLLOLLOLLOLLOLLOLL
|
|
|
|
|
|
|
|
|
|
|
|
OLLOLL
|
|
|
|
OL
|
L
|
|
|
TRN
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TRNTRNTRNTRNTRNTRNTRNTRNTR
|
|
|
|
|
|
|
|
|
|
|
|
|
N
|
|
E
|
|
R
|
E
|
|
|
RE
|
|
|
RE
|
|
|
RE
|
|
|
RE
|
|
|
RE
|
|
|
RE
|
|
|
RE
|
|
|
RE
|
|
R
|
Tableau n°7 : Statistiques de reconnaissances
MC : Mot Connu
LC : Lettre Connue
LNC : Lettre Non Connue
NOTE : La somme des mots reconnus par le système TLR :
Total des lettres reconnues
TLNR : Total des lettres non reconnues
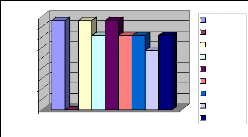
18,00%
16,00%
14,00%
12,00%
10,00%
4,00%
8,00%
6,00%
2,00%
0,00%
Taux d'erreur
Ali
Salah Chedli Fatma Manoubia Fathi
Fahima Mohamed Hassouna
Figure 26 : Taux d'erreurs
D'après l'histogramme des taux d'erreurs, nous avons pu
aider les instituteurs à prendre des décisions sur la formation
des élèves. Lorsque le taux d'erreur décroît dans ce
cas on est sur la bonne route mais lorsque le taux augmente dans ce cas le
niveau de l'élève décroît et l'instituteur sera
capable de corriger les erreurs et de découvrir les erreurs engendrer
par l'élève.
3. Conclusion
Nous avons montré dans ce chapitre le mécanisme
d'extraction des mots manuscrits. Notre système a été
implémenté dans une école pour l'enseignement des
âgées. Nous avons présenté notre extension sur le
système «RIMA » et nous avons décrit brièvement
les atouts de notre système de découvrir les bons parmi les
mauvais élèves. A partir des taux erreurs obtenu par notre
système nous avons pu aider les instituteurs à prendre une bonne
décision et découvrir très vite les lacunes des
élèves.
| 
