2.2. Description détaillée
Nous allons détailler l'architecture globale du
système et expliquer chaque composant et son processus de
fonctionnement.
2.2.1. Sous système d'apprentissage
Le sous système d'apprentissage est la première
phase dans le processus de reconnaissance de mots manuscrits, parce que notre
approche est basée sur une décision analytique (ascendante)
c'est-à-dire qu'il faut avoir une base d'apprentissage des
différentes formes d'écriture des lettres manuscrites arabes pour
reconnaître un mot.
2.2.1.1. Pré-traitement
Le pré-traitement inclut toutes les fonctions
effectuées avant de commencer le traitement pour produire une version
« nettoyée » de l'image d'origine afin qu'elle puisse
être utilisée directement et efficacement. Ainsi le
pré-traitement comprend la binarisation, la normalisation et
l'encadrement.
a. Binarisation
La binarisation est la première étape de
pré-traitement elle consiste à convertir l'image
numérisée en une image binaire. Cependant, la binarisation est
une opération qui produit deux classes de pixels, en
général, ils sont représentés par des pixels noirs
et des pixels blancs.
Ainsi les pixels correspondant à des points
élevés doivent être binarisés en noire (valeur=1) et
ceux dans les creux doivent être binarisés en blanc (valeur=0). La
figure 10 montre une image avant est après binarisation.

Image avant binarisation Image après binarisation
Figure 9 : Exemple de binarisation d'une image couleur.
Ainsi, nous avons proposé l'algorithme de binarisation qui
utilise un seuil par défaut égale à 127 (50% de la valeur
maximale: 255)
Algorithme
POUR i de 1 à largeur FAIRE
POUR j de 1 à hauteur FAIRE
p = Image1 .pixel (i, j)
SI p < seuil ALORS
val E- 0
INON
val E- 255
FIN SI
Image2 .MettrePixel (i, j , val)
FIN POUR FIN POUR
Fin
b. Encadrement
L'encadrement c'est le processus de localisation de la lettre,
c'est de définir les cordonnées de la lettre dans l'image. Pour
cela nous avons crée une fonction qui permet de donner les
propriétés suivantes : haut, bas, gauche, droite, afin de passer
à l'encadrement de la lettre.
Nous présentons ci-dessous l'algorithme utilisé
:
Type LocaliserCordonner : enregistrement
G: entier
H: entier
D: entier B: entier
Fin
Fonction LocaliserLettre (var image : Bitmap) :
LocaliserCordonner
var
i,j : entier
hauteur, largeur :entier Lettre : LocaliserCordonner Couleur :
entier
|
Début
|
|
|
|
G
|
=
|
-1
|
|
H
|
=
|
-1
|
|
D
|
=
|
-1
|
|
B
|
=
|
-1
|
hauteur = GetHauteur (image)
largeur = GetLargeur (image)
// En Haut
Pour i de 1 à largeur faire
Pour j de 1 à hauteur faire
Couleur EH GetPixel(image, j, i)
Si ((Couleur <> 1) ET (Couleur <> -1) ) Alors
Lettre.H EH i Sortir Pour
Fin Si Fin Pour
i (Lettre . H) <> -1 Then Sortir Pour
Fin Si
Image
Largeur
Lettre
Fin Pour
i (Lettre . H = -1) Then GetReelText E- Lettre Sortir
de la fonction
End If
// A Gauche
Pour i de 1 à hauteur
Pour j de Lettre.H à largeur
Couleur EH GetPixel(image, j, i)
i ((Couleur <> 1) ET (Couleur <> -1)) Alors
Lettre.G EH i
Largeur
Sortir Pour



Fin Si Fin Pour
Image
i (ReelText.G) <> -1 Then Sortir Pour
Lettre
Fin Si Fin Pour
i (ReelText.G = -1) Then GetReelText EH ReelText Sortir de la
fonction
Fin Si
// A Droite
Pour i de hauteur à ReelText.G (pas -1)
Pour j de ReelText.H à largeur
Couleur EH GetPixel(image, j, i)
Si ((Couleur <> 1) ET (Couleur <> -1)) Alors


Image
Largeur
Lettre
ReelText.D EH i Sortir Pour
Fin Si
Fin Pour
Si (ReelText.D) <> -1 Then Sortir Pour
Fin Si

Fin Pour
i (ReelText.D = -1) Then GetReelText EH ReelText Sortir de la
fonction
Fin Si
// En bas
Pour i de largeur à ReelText.H (pas-1)
Pour j de ReelText.D à hauteur
Couleur EH GetPixel(image, j, i)
Si ((Couleur <> 1) ET (Couleur <> -1)) Alors
ReelText.B EH i
Sortir Pour
Image
Largeur
Lettre
Fin Si Fin Pour
i (ReelText.B) <> -1 Then Sortir Pour
Fin Si
Fin Pour
i (ReelText.B = -1) Then GetReelText EH ReelText Sortir de la
fonction
Fin Si
LocaliserMot EH ReelText Fin
Cette fonction permet donc de localiser une lettre ou un mot
dans une image tout en parcourant toute l'image et en localisant les pixels
noirs. Donc cette phase est vraiment la plus intéressante dans notre
sous système de prétraitement puisqu'elle nous offre un gain de
temps que ce soit dans l'apprentissage ou dans la reconnaissance de mot. La
figure 10 montre un exemple de localisation d'un mot dans une image et par la
suite un encadrement de ce dernier.
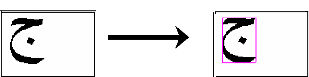
A Gauche
56
En Haut
47
En Bas
A Droit
104
107
Figure 10 : Exemple d'encadrement d'une lettre dans une image c.
Normalisation (Adaptation)
La normalisation consiste à transformer la taille de
l'image et l'adapter à une dimension fixée a priori par
l'utilisateur (voir figure 11), pour cela nous avons proposés une
procédure qui permet de normaliser l'image encadrée dans une
dimension de 64*64 pixels.
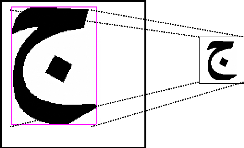
Image 1
Image2
Figure 11 : Exemple de normalisation d'une lettre
Cette procédure copie le contenu d'une première
image pixel par pixel et la copie, rétrécie ou agrandie, dans une
seconde image.
Nous avons utilisé une échelle qui sera
calculée automatiquement en fonction de la dimension de la lettre
encadrée dans l'image par rapport à la dimension 64*64 pixels.
Alors, on note les différentes échelles :
ü Echelle>1 : Pour agrandir
ü Echelle <1 : Pour rétrécir
ü Echelle =1 : Pour garder la même taille
La normalisation est effectuée par l'algorithme
ci-dessous :
Procedure Normalisation (Image1 : Bitmap, Image2 : Bitmap,
Echelle : Réel): Bitmap
Var
X, Y: Réel c :Long
i, j : Réel
Hauteur, Largeur : Réel
HAdap, LAdap : Réel
Début
Hauteur= ReelText.B- ReelText.H
Largeur= ReelText.D-
ReelText.G
EchelleH = Hauteur / Image2 .ScaleHeight EchelleV = Largeur /
Image2 .ScaleWidth
j = 0
Pour y de ReelText.H à ReelText.B (pas de EchelleH) Faire
i = 0
Pour x de ReelText.D à ReelText.G (pas de EchelleV) Faire
c = Image1 . Point (x, y)
Image2 . PSet (i, j ) , c
i = i + 1
Fin Pour
j = j + 1 Fin Pour
Fin
2.2.1.2.Traitement
Dans cette étape, il y aura l'apprentissage des
modèles des lettres par des matrices de distribution puis leur stockage
dans une base de données.
a. Construction de la matrice de distribution
La construction de la matrice de distribution est l'une des
phases importantes dans notre système. Nous considérons par
exemple la représentation de la lettre 'jim', qui s'écrit en
arabe 'Ì' dans sa forme isolée, sur une matrice 5x5
constituée par les nombres des pixels de a à y :
a
|
b
|
c
|
de
|
|
f
|
g
|
|
hij
|
|
k
|
l
|
|
mno
|
|
|
pq
|
r
|
st
|
|
u
|
v
|
w
|
x
|
y
|
|
On suppose que l'on dispose de plusieurs représentants
similaires mais pas tout à fait identiques à la lettre 'jim' ; le
nombre minimum de représentant d'une forme de cette lettre est 1 et le
nombre maximum ainsi que la variation maximale sont en fonction de la
discrimination qui en résulte sur la totalité de la base
d'apprentissages (de '' à 'í') ; ce cas idéal
dépend du nombre de pixels contenue dans la matrice (voir figure 12).

Figure 12 : Exemple de matrice de distribution (5*5) de la lettre
alphabet arabe «jim »
Les différents modèles du 'jim' devront
être les plus différents possibles (pour couvrir la plus grande
gamme de 'jim', mais chacun d'eux devra toujours être plus proche de la
classe des 'jim' plutôt que de tout autre classe de lettres.
Pour chaque pixel d'un caractère on étudie les
deux cas suivants :
ü les pixels qui sont de 1 à 100 indiquent la
présence du caractère;
ü les pixels qui ont un 0 indiquent l'absence du
caractère.
On suppose qu'on a une image comme celle de la figure 8
contenant la lettre 'jim' encadrée, si on applique maintenant une
matrice de 5x5 sur cette lettre. Cependant chaque cellule va avoir un nombre de
pixels. Pour cela nous avons crée une procédure qui permet de
transformée l`image d'une lettre en une matrice de dimension 5x5
contenant dans chaque cellule un nombre des pixels.
Procedure GetMatriceDistribution(Image:Bitmap , ReelText:
LocaliserCordonner)
Var
i,j : entier
IncH, IncV : entier
|
x,
|
y
|
:
|
entier
|
|
a,
|
b
|
:
|
entier
|
|
l,
|
k
|
:
|
entier
|
couleur : entier long matrice[5][5] : entier
Début
IncH = (ReelText.B - ReelText.H) / 5
IncV = (ReelText.G -
ReelText.D) / 5
x F 0
j F ReelText.D
Tant que (j < ReelText.G)
x F x + 1
y F 0
i F ReelText.H
Tant que (i < ReelText.B)
y F y + 1
Pour k = j To j + IncH
Pour l = i To i + IncV
couleur = GetPixel(Image, k, l)
If couleur = 0 Then
matrice[ x] [ y] F matrice[ x] [ y] + 1 End If
Fin Pour Fin Pour
i = i + IncH Fin tant que
j = j + IncV
Fin tant que
b. Base de données du système
La base de données utilisée est construite
à partir de l'ensemble de graphèmes issus des écritures
écrites par différents scripteurs. Chaque lettre doit être
représentée dans la base sous ces différentes formes
(début, milieu, fin, isolée) comme dans le tableau n°2.
|
Caractère
|
Début
|
Milieu
|
Fin
|
Isolé
|
|
AlifA
|
|
|
1Ü
|
|
|
AlifB
|
|
|
YÜ
|
Ç
|
|
AlifC
|
|
|
cÜ
|
d
|
|
Ba
|
Üe
|
ÜfÜ
|
YÜ
|
È
|
|
Ta
|
Üi
|
i
|
iÜ
|
Ê
|
|
Tamarbouta
|
|
|
|
É
|
|
Tha
|
b
-1
|
Ire
|
t.
iÜ
|
t.
i-,
|
|
Nun
|
Ür
|
jÜ
|
üÜ
|
ä
|
|
Ya
|
Üu
|
ÜvÜ
|
cÜ
|
í
|
|
Jim
|
Üx
|
ÜyÜ
|
eÜ
|
Ì
|
|
Ha
|
Ü{
|
Ü[Ü
|
|Ü
|
Í
|
|
Kha
|
Ü~
|
ÜÜ
|
ÉÜ
|
Î
|
|
Dal
|
|
|
àÜ
|
Ï
|
|
The
|
|
|
1Ü
|
Ð
|
|
Ra
|
|
|
.Ü
|
Ñ
|
|
Za
|
|
|
.Ü
|
Ò
|
|
Waw
|
|
|
jÜ
|
æ
|
|
Sin
|
Üf
|
Ü,Ü
|
LÜ
|
Ó
|
|
Chin
|
Ü
|
ÜfÜ
|
LAÜ
|
Ô
|
|
Caractère
|
Début
|
Milieu
|
Fin
|
Isolé
|
|
Sad
|
Ü4
|
Ü4Ü
|
uÜ
|
Õ
|
|
Dhad
|
Ü.
|
Ü.Ü
|
LÜ
|
Ö
|
|
Tad
|
Ü/
|
ÜùÜ
|
IÜ
|
Ø
|
|
Dha
|
Üà
|
ÜàÜ
|
MÜ
|
Ù
|
|
Ayn
|
Üc
|
Ü'Ü
|
Ü
|
Ú
|
|
Ghayn
|
Üe
|
Ü4Ü
|
Ü
|
Û
|
|
Fa
|
à
|
ÜiÜ
|
cÜ
|
|
|
Qaf
|
à
|
ÜIÜ
|
dÜ
|
Þ
|
|
Kaf
|
ÜÂ
|
ÜuÜ
|
Ü
|
ß
|
|
Lam
|
Ü\
|
ÜÜ
|
JÜ
|
á
|
|
Mim
|
Ü»
|
ܼÜ
|
eÜ
|
ã
|
|
He
|
Üå
|
ÜgÜ
|
ÁÜ
|
Â
|
|
LamalifA
|
|
|
Ü
|
Ä
|
|
LamalifB
|
|
|
9Ü
|
Æ
|
|
LamalifC
|
|
|
Ü
|
È
|
|
LamalifD
|
|
|
9Ü
|
Ê
|
|
WawHamza
|
|
|
àÜ
|
Ä
|
|
Hamza
|
ÜÍ
|
ÜÎÜ
|
zÜ
|
Æ
|
Tableau n°2: Différentes formes des lettres de
l'alphabet arabe
L'écriture manuscrite pour un mono-scripteur doit avoir
122 formes d'apprentissage. Le tableau 3 illustre le nombre d'apprentissage
pour chaque position de la lettre dans le mot.
Plus la base de données d'apprentissage est grande plus
les résultats de reconnaissances des graphèmes sera plus
élevés. Ainsi on obtient un taux de reconnaissance de mots plus
importants.
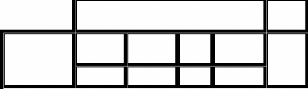
37
23
Nombres d'apprentissages
Isolée
39
Total
122
23
Lettre
Alphabet
Arabe
Début
Milieu
Fin
Tableau n°3 : Nombres des formes d'apprentissages
mono-scripteur 2.2.2. Sous système de reconnaissance
2.2.2.1. Pré-traitement
Le pré-traitement est un module qui correspond exactement
à celui du sous système d'apprentissage.
2.2.2.2. Traitement
Le traitement est le processus de reconnaissance du mot il
consiste à comparer chaque tranche d'un mot qui est
représentée dans une matrice de distribution à celle des
modèles de la base de données d'apprentissage, afin de
reconnaître toutes les graphèmes constituant le mot ce qui abouti
à la reconnaissance du mot lui-même. Tous les différentes
parties du traitement seront détaillées dans ce qui suit.
a. Extraction incrémental des trames (par
partitionnement)
L'extraction incrémental des trames permet de trancher
à chaque itération une partie de taille fixe du mot
encadrée afin de la mettre dans une matrice de distribution.
b. Correspondance
La correspondance est un processus très important dans
notre système puisque qu'il permet de prendre une décision en
fonction de la comparaison des caractéristiques des matrices des
caractères qui sont dans la base de données d'apprentissage et
à celle acquise. Pour cela nous allons définir une fonction qui
calcule le coefficient de corrélation entre deux matrices de
distributions. Tout le problème consiste donc à étudier
les coefficients de corrélations dont le but est de décider quel
caractère va-t-ont entretenir.
Le coefficient de corrélation désigne la pente a
qui donne le sens de corrélation, mais pas sa qualité:
/ a>0: corrélation positive / a<0:
corrélation négative
a=0 : pas de corrélation
La qualité de la corrélation peut être
mesurée par un coefficient de corrélation r : dont la formule est
ci-dessous :
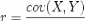
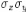
Avec X la variable qui représente les valeurs de la
matrice de distribution de l'image acquise et Y la variable qui
représente les valeurs de la matrice de distribution du modèle de
la base de données d'apprentissage.
Le coefficient de corrélation est compris entre 1 et +1.
Plus il s'éloigne de zéro, meilleure est la corrélation
ü r = +1 corrélation positive parfaite
ü r = 1 corrélation négative parfaite
ü r = 0 absence totale de corrélation
Voici quelques exemples de corrélation dont le coefficient
de corrélation r est indiqué dans chaque cas :
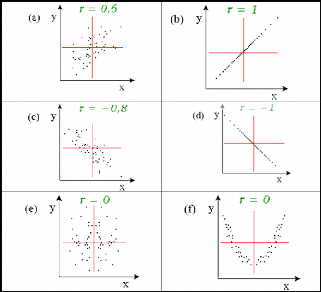
Figure 13 : Exemples de corrélation
La figure a et b nous présentent une corrélation
parfaite alors que c et d présentent une coopération imparfaite
mais pour le cas de e et fil y'a absence totale de corrélation.
Le processus de correspondance que nous adoptons est
décrit dans la figure 14. Nous avons en entrée la matrice de
distribution, la position de la primitive extraite (début, milieu, fin).
Suivant cette position on parcourt notre base de données d'apprentissage
pour retenir les matrices ayant mêmes positions et on calcule la
corrélation entre la matrice acquise avec celles retenus. Ensuite on
fait la sélection de la meilleure corrélation suivant un seuil
fixé par l'utilisateur. Le résultat enfin peut être une
lettre ou le vide.
Le système prend en charge la reconnaissance de la
première lettre pour pouvoir identifier le scripteur et ensuite le
système se charge de prendre cette condition afin de modifier la
requête de sélection pour diminuer le parcours de toute la base de
données d'apprentissage et d'aboutir à des résultats
parfaits.
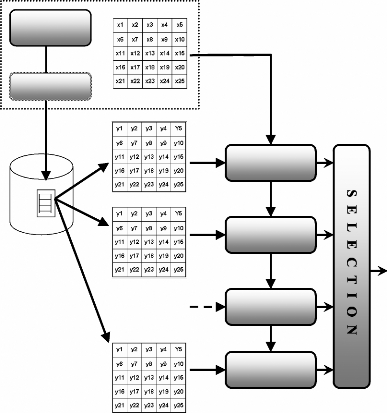
BD
d'apprentissage
Id. Scripteur
Position
lettre
'1
'2
'n
+
X
.
.
.
Corrélation
Corrélation
Corrélation
Corrélation
Résultat
Figure 14 : Processus de correspondance
c. Reconnaissance
La reconnaissance est le résultat obtenu par le processus
de correspondance qui va nous donner deux types de décisions que nous
définissons dans ce qui suit:
v Lettre reconnu : dans ce cas nous somme obligé
procéder a deux opérations:
1. c'est de modifier le processus de correspondance en
prenant en charge l'identité du scripteur de la lettre reconnu afin de
modifier le processus de correspondance pour qu'il évite le parcours de
toute la base de données.
2. dans un deuxième opération nous ne sommes
pas sûre de la terminaison du processus de reconnaissance sur le mot
alors on doit vérifier a chaque itération si on n'a pas atteint
la fin du mot. Dans ce cas nous avons deux autres conditions:
Fin mot - non: dans ce cas on mémorise le
caractère obtenu par le processus de correspondance et évidement
qui a le plus grand score. Enfin en recommence de processus d'acquisition d'une
nouvelle partition tout en éliminant les partitions parcourues puisque
nous avons abouti à une reconnaissance.
Fin mot - oui: dans ce cas on rassemble tous les
caractères collectés pour construire le mot en solution et nous
mettons fin au processus de reconnaissance.
v Lettre non reconnu: dans ce cas on conserve la partition
précédente et on lui ajoute une nouvelle partition et on
recommence le processus d'acquisition d'une nouvelle partition.
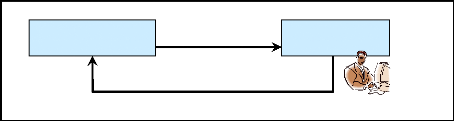
2.2.2.3. Post-traitement
Cette étape permet de vérifier et de corriger
les éventuelles erreurs de la reconnaissance (figure 15). Cette
étape est effectuée manuellement, et permet d'expérimenter
la précision du système.
Reconnaissance
Correction
Compréhension
Figure 15 : Processus de correction
Après chaque processus de reconnaissance de mot, il va
être envoyé au correcteur pour la compréhension :
c'est-à-dire vérifier si le mot entré correspond à
celui obtenu.
Nous avons ajouter au niveau de ce processus une
évaluation automatique sans intervention humaine (figure 16), elle est
basé sur une évaluation non supervisée c'est-à-dire
qu'à la fin de la reconnaissance, on vérifie si le mot obtenu
correspond a celui demandé, si c'est le cas alors le système
mémorise les lettres reconnues et les lettres non reconnues et donnera
en sortie une valeur comprise entre 0 et 1. 0 si le mot qu'on veut avoir dans
le résultat ne correspond pas à celui reconnu et 1 dans le cas
contraire.
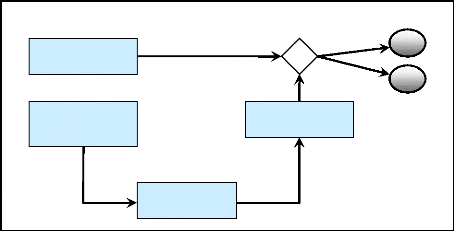
Image du Mot à
reconnaître
Evaluatio!f, automatique
Mot à obtenir
0
No!f,
(;ui
1
Reconnaissance
Mot solution
Figure 16 : Le processus d'évaluation automatique du
résultat 3. Conclusion
Nous avons proposés dans ce chapitre une architecture
de reconnaissance d'écriture manuscrite arabe hors-ligne, nous avons
détaillé les différentes parties et module de cette
architecture. Dans le chapitre suivant nous allons décrire la
réalisation du prototype que nous avons développé pour
mettre en oeuvre notre travaille. Nous allons aussi mener une étude
expérimentale pour valider les résultats de reconnaissance pour
notre méthode.
Chapitre
3
|
RÉALISATION
DU
SYSTEME
|
Objectifs du chapitre
Nous présentons dans ce chapitre la réalisation
du système de reconnaissance de mots manuscrits arabe hors-ligne
basée sur une écriture multi-scripteurs qui est
déjà détaillée dans le chapitre
précédent avec une description du prototype ainsi que ses
différentes fonctionnalités et maquettes. Mais d'abord nous
décrivons le modèle de développement suivi.
| 

