Chapitre 1
Fouille de données d'usage du Web
1. Web
Content Mining Web Structure Mining
Web Mining
Web Usage Mining
Introduction
Les sites Web représentent actuellement une
véritable source de production de grands volumes d'informations. La
recherche d'information, la consultation de données et l'achat en ligne,
sont des exemples de l'utilisation du Web. Dans le but d'améliorer ces
services et d'autres nous nous intéressons aux informations liées
au comportement des utilisateurs de cet environnement .C'est dans cet espace
que nous pouvons récupérer une quantité d'informations
pertinentes.
Pour fixer les idées, nous introduisons dans ce
chapitre la fouille de données du web et précisément la
fouille de donnée d'usage du web, les diverses définitions,
concepts, les données d'usage et quelque approches d'analyse que nous
utiliserons tout au long de ce mémoire.
2.
Fouille de données du Web
La fouille du Web (Web Mining (WM), en anglais) [01]
s'est développée à la fin des années 90 et
consiste à utiliser l'ensemble des techniques de la fouille de
données afin de développer des outils permettant l'extraction
d'informations pertinentes à partir de données du Web (documents,
traces d'interactions, structure des liens, etc.).
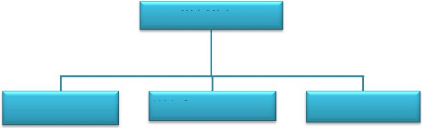
2.1. Taxonomie du Fouille de données du Web
Selon l'objectif visé plusieurs types d'études
peuvent être réalisés (FIG.1.1), à savoir :
a. L'analyse du contenu des pages Web (Web Content
Mining) :
C'est le processus d'extraction des connaissances à
partir du contenu réel des pages Web. Les informations provenant du Web
sont stockées dans des bases de données. Ces dernières
sont ensuite analysées en utilisant les langages d'interrogations des
bases de données et les techniques de fouille de données.
b. L'analyse des liens entre les pages Web (Web
Structure Mining) :
Il s'agit d'une analyse de la structure du Web, de
l'architecture et des liens qui existent entre les différents sites.
L'analyse des chemins parcourus permet par exemple de déterminer combien
de pages consultent les internautes en moyenne et ainsi d'adapter
l'arborescence du site pour que les pages les plus recherchées soient
dans les premières pages du site. De même, la recherche des
associations entre les pages consultées permet d'améliorer
l'ergonomie du site par création de nouveaux liens
c. L'analyse de l'usage des pages Web (Web Usage Mining)
:
Cette dernière branche du Web Mining consiste à
analyser le comportement de l'utilisateur à travers l'analyse de son
interaction avec le site Web. Cette analyse est notamment centrée sur
l'ensemble des clics effectués par l'utilisateur lors d'une visite au
site (on parle alors d'analyse du clickstream). L'intéret est d'enrichir
les sources de données utilisateur (bases de données clients,
bases marketing, etc.) à partir des connaissances extraites des
données brutes du clickstream et ce afin d'affiner les profils
utilisateur et les modèles comportementaux.
C'est précisément sur cet axe, exploité
plus en détail dans le présent chapitre que se focalise la
présente thèse.
| 

