2.2.3 Apprentissage non supervisé
Un modèle est préparé en déduisant
les structures présentes dans les données d'entrée. Il
peut s'agir d'extraire des règles générales. Il peut
s'agir d'un processus mathématique visant à réduire
systématiquement la redondance, ou d'organiser les données par
similarité. Un programme n'apprend pas à partir de données
étiquetées. Au lieu de cela, il tente de découvrir des
modèles dans les données [12].
Ici les données ne sont pas étiquetées,
L'objectif principal de l'apprentissage non supervisé est de permettre
à l'algorithme de trouver des patterns, des regroupements ou des
relations entre les données d'entrée, sans intervention
humaine.
2.3.4 Apprentissage par renforcement
L'apprentissage par renforcement (Reinforcement
Learning, en anglais) est une forme d'apprentissage automatique dans
laquelle un agent autonome apprend à prendre des décisions en
interagissant avec un environnement dynamique. Cet agent n'apprend pas à
partir d'un ensemble de données déjà
étiqueté (comme en apprentissage supervisé), mais à
travers des essais et des erreurs, en recevant des récompenses ou des
pénalités selon la qualité de ses actions.
2.3.5 Notions de Deep Learning
Le Deep Learning ou apprentissage profond est une branche
avancée de l'apprentissage automatique (machine learning) qui repose sur
l'utilisation de réseaux de neurones artificiels profonds,
composés de plusieurs couches. Ces architectures sont capables de
modéliser des relations complexes et de traiter des données de
grande dimension comme les images, les sons ou les textes non structurés
[13].
70
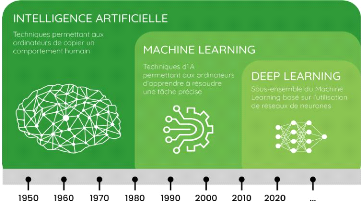
Figure 34 Machine learning, deep learning description
Un réseau de neurones est une structure inspirée
du fonctionnement du cerveau humain. Il est constitué de plusieurs
neurones artificiels.
Les approches classiques de Machine Learning
nécessitent peu de données pour fonctionner efficacement. Elles
s'appuient sur des architectures comme les arbres de décision, SVM ou
KNN, et offrent de bonnes performances lorsqu'elles sont appliquées
à des données structurées. Leur entraînement est
généralement rapide et peu coûteux.
En revanche, les modèles de Deep Learning sont
particulièrement adaptés aux données complexes telles que
les textes, les images ou les sons. Ils reposent sur des réseaux de
neurones profonds et exigent de grandes quantités de données pour
atteindre leur plein potentiel. Leur entraînement demande plus de temps
et mobilise davantage de ressources.
Cas d'usage du Deep Learning dans le traitement de
CV
L'usage du Deep Learning dans le traitement des curriculum
vitae (CV) constitue une avancée majeure dans l'optimisation des
processus de recrutement. Cette technologie, grâce à sa
capacité à traiter des données textuelles
hétérogènes et non structurées, permet de
répondre à des enjeux stratégiques liés à la
sélection automatisée et à la correspondance entre
candidatures et offres d'emploi.
| 

