Impact des Technologies de l'Information et de la Communication (TIC) sur le tissu productif des biens et services au Maroc( Télécharger le fichier original )par Ghynel NGASSI NGAKEGNI INSEA Rabat - Ingenieur d'Etat en Statistique et Economie (Majeur: Statistique) 2010 |

II.5. Validation du modèleII.5.1.Test statistique sur le modèle global En examinant le tableau de l'analyse de la variance ci dessous, Tableau 14 : Tableau ANOVA du modèle.
Nous constatons que le test d'hypothèse, Vs nous pousse à rejeter l'hypothèse au seuil car la statistique de Fisher-Snedecor observée est supérieure au fractile de la loi de Fisher-Snedecor lu sur la table au seuil d'où le modèle est globalement significatif, ceci par le fait que les variables Stock de capital TIC, Stock de capital hors TIC et le stock de travail engagé à l'échelle nationale (L) y compris la variable Dummy D_1998 sont globalement significatives. II.5.2.Test statistique sur les coefficients du modèle A partir des relations définies auparavant, le test statistique sur les coefficients du modèle, convient à calculer les ratios de student et de les comparer à la valeur lue dans la table au seuil 5% du fractile de student qui est égale a dans notre cas. Tableau 15 : Tableau des coefficients du modèle avec intervalles de confiance des paramètres estimés
D'après le tableau ci-dessus, nous obtenons : . Pour l'hypothèse Vs , on a on accepte l'hypothèse. D'où la variable Ln_KTIC ne contribue pas à l'explication de la variable Ln_Y. . Pour l'hypothèse Vs , on a on rejette l'hypothèse. D'où la variable Ln_KHTIC contribue à l'explication de la variable Ln_Y. . Pour l'hypothèse Vs , on a on accepte l'hypothèse. D'où la variable Ln_L ne contribue pas à l'explication de la variable Ln_Y . Pour l'hypothèse Vs , on a on accepte l'hypothèse. D'où la variable D_1998 contribue a l'explication de la variable Ln_Y. II.5.3. Test de détection d'une multi-colinéarité (test de Farrar et Glauber ) . Ce test revient à tester l'hypothèse (les séries sont orthogonales) Vs (les séries sont dépendantes).Avec D, le déterminant de la matrice des coefficients de corrélation des variables (Ln_KTIC, Ln_KHTIC, Ln_L et D_1998). Le calcul du déterminant D, nous donne : = La valeur empirique de calculée à partir de l'échantillon est : Nous allons comparer cette valeur au fractile de chi-deux à degré de liberté pour un seuil on ; on rejette l'hypothèse nulle. Ceci dit qu'il y a présomption de multi-colinéarité entre les variables explicatives. L'aboutissement à ce résultat est toujours dû aux limites du modèle pour un pays en développement, comme nous l'avons déjà mentionné plus haut. II.5.4.Coefficient de détermination Tableau 16 : Tableau récapitulatif du modèle1.
En examinant ce tableau, nous enregistrons un coefficient de détermination ; ceci peut s'expliquer par le fait que de variation totale du PIB est dû aux variables explicatives (KTIC, KHTIC, L et D_1998) et nous pouvons souligner que la qualité du modèle obtenu est relativement bonne. II.5.5.Test sur les résidus du modèle 1) Test d'autocorrélation des résidus : statistique de Durbin-Watson Tableau 17 : Test d'autocorrélation des résidus : statistique de Durbin-Watson.
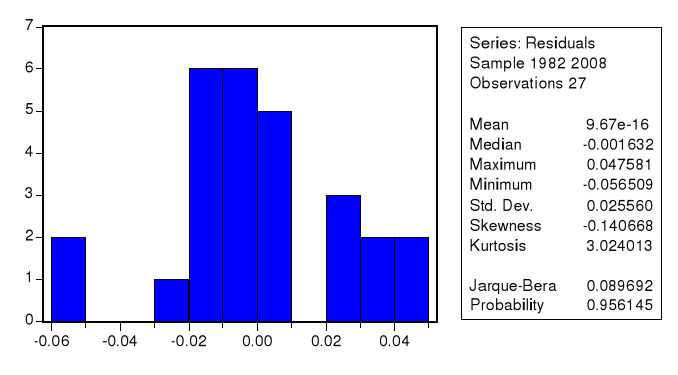
La valeur de la statistique montre qu'il y a absence d'autocorrélation des résidus. 2) Test de normalité des résidus :statistique de Jarque Bera Figure 11 : Test de normalité des résidus : statistique de Jarque Bera.
La probabilité de Jarque-Bera (0.956145) est supérieure à 5% ; cela implique que les résidus suivent une loi normale. 3) Test d'hétéroscédacticité des résidus : test de White Tableau 18 : Test d'hétéroscédacticité des résidus : test de White.
Les deux probabilités sont supérieures à 5% donc on accepte l'hypothèse d'homoscédasticité des erreurs. Les estimations obtenues par les moindres carrés ordinaires sont optimales. 4) Test de spécification Il existe plusieurs tests de spécification (Ramsey, etc). Ici, nous retenons le test de Ramsey. Le Reset13(*) teste les erreurs de spécification suivantes :
Tableau 19 : Test de spécification.
Les deux probabilités sont supérieures à 5% donc on accepte l'hypothèse Ho, le modèle est bien spécifié. 5) Test de Rendement d'échelle constant Ce test nous permet de tester si le PIB augmente dans une proportion identique aux facteurs de production ou pas. Dans ce cas nous allons tester l'hypothèse suivante : VS La statistique de student calculée est donc égale, sous , à Or la matrice des variances covariances des coefficients est donnée par : Tableau 20 : Matrice des variances covariances des coefficients du modèle1.
Soit : = 0.53275143+0.30463681+0.7666345+2*0.39370923+2*0.4222887+2*0.30901201 = 3.8540426 Nous avons 60% de risque de rejeter l'hypothèse à tort, nous pouvons considérer le rendement d'échelle comme significativement croissant. D'où La production augmente plus vite que les facteurs de production. * 13 Regression Specification Error Test |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||