Impact des Technologies de l'Information et de la Communication (TIC) sur le tissu productif des biens et services au Maroc( Télécharger le fichier original )par Ghynel NGASSI NGAKEGNI INSEA Rabat - Ingenieur d'Etat en Statistique et Economie (Majeur: Statistique) 2010 |

ï II. Mise en oeuvre de la méthodologie de Box and Jenkins pour des prévisions à l'horizon 2020ï Cette partie porte sur la modélisation des indicateurs des TIC (nombre de lignes téléphoniques pour 100 habitants, nombre d'ordinateurs personnels pour 100 habitants) à long terme, à savoir la détermination du processus en mesure de reproduire l'évolution de ces indicateurs. A partir du modèle optimal retenu, on établira des prévisions annuelles. La modélisation des indicateurs et les prévisions en résultant est obtenue par application de la méthode d'analyse univariée de Box & Jenkins, qui constitue l'outil le plus approprié à l'étude des séries temporelles annuelles et devant servir à des prévisions de long terme. Cette approche consiste à déterminer le modèle qui permet de reproduire le plus fidèlement l'évolution de ces indicateurs et d'établir les prévisions sur un horizon déterminé. ï La méthode retenue comporte les étapes suivantes : 1. Analyse de la série des indicateurs (tendance, ajustement). 2. Identification et validation des modèles susceptibles de reproduire la série chronologique des indicateurs annuels. 3. Choix du modèle le plus approprié sur la base de critères statistiques. 4. Détermination, à partir du modèle retenu, des valeurs attendues des indicateurs annuels pour la période prospective considérée. ï ï L'analyse portera sur les séries des valeurs annuelles enregistrées pour les indicateurs à entre 1975 et 2008. Au terme de cette analyse, on présentera l'ajustement des indicateurs pour la période [2009-2020]. ï Dans le but d'illustrer la méthode de Box&Jenkins d'une manière bien détaillée, on a choisi comme exemple, le nombre de lignes téléphoniques (pour 100 habitants), c'est-à-dire de lignes téléphoniques reliant l'appareil d'un client à un réseau téléphonique public. L'indicateur évalue leur nombre par tranche de 100 habitants. ï Il aurait été également intéressant de faire des prévisions du nombre de GSM pour 100 habitants, vu son poids actuel dans l'évolution des TIC mais par faute de statistiques fiables et suffisantes, nous n'avons pas pu réaliser ces prévisions. ï ï ï ï ï II.1. Etape n° 1 : Stationnarisation ï Le premier reflexe est de visualiser la série ; ainsi le graphique représentant l'évolution de la série {Xt : nombre de lignes téléphoniques pour 100 habitants} est le suivant : ï ï Figure 19 : Présentation graphique de l'évolution de la série des nombres de lignes téléphoniques pour 100 habitants.
ï ï ï Clairement, cette série n'est pas stationnaire en tendance. Il faut la différencier à l'ordre 1. Ceci implique l'application d'une différence, en d'autres termes l'application de l'opérateur 1-B. ï Ainsi, nous disposons d'une nouvelle série d'étude, dont le graphe est le suivant : ï Figure 20 : Evolution de la série des nombres de lignes téléphoniques pour 100 habitants ï après différentiation.
ï ï ï D'après ce graphique, la série est stationnaire en tendance, il nous permet aussi de conclure qu'elle est aussi stationnaire en variance. Il est à noter que nous n'avons pas eu à traiter le problème de saisonnalité pour l'ensemble des séries du nombre de lignes téléphoniques pour 100 habitants, car nous traitons des données annuelles dont le caractère dominant est l'évolution depuis 1975 jusqu'à 2008. ï Après l'analyse préliminaire effectuée sur la série de NLT_100_HAB, les conditions sont maintenant remplies pour la recherche dans la famille des modèles ARMA le modèle qui s'adapte le mieux aux données de la série Ut = (1-B) Xt. ï ï II.2. Etape n°2 : Identification ï La méthode usuelle consiste à se baser sur la forme des fonctions d'autocorrélation et d'autocorrélation partielle de la série étudiée (éventuellement transformée) afin de choisir un modèle ARMA ou éventuellement plusieurs modèles qui seront examinés, en utilisant SPSS on obtient les graphiques des ACF et PACF de la série Ut. ï ï Figure 21 : Corrélogramme simple de la série NLT_100_HAB .
ï ï ï ï Figure 22 : Corrélogramme partiel de la série NLT_100_HAB.
ï ï ï ï Au vu de ces deux corrélogrammes, il est difficile d'identifier clairement une représentation caractéristique moyenne mobile ou autorégressive. Toutefois nous pouvons commencer par spécifier un modèle ARIMA (0, 1,1). En effet, nous pouvons considérer que le corrélogramme partiel (PACF) décroit lentement tandis que le corrélogramme simple(ACF) a son premier terme significativement différent de 0. ï Les deux corrélogrammes permettent une autre spécification d'un modèle ARIMA (1, 1,0).En effet, nous pouvons considérer que le corrélogramme simple (ACF) décroit lentement tandis que le corrélogramme partiel (PACF) a son premier terme significativement différent de 0. ï Un troisième processus à analyser est celui qui combine les deux précédents processus ï ARIMA (0, 1,1) et ARIMA (1, 1,0)) noté ARIMA (1, 1,1). ï A ces processus, nous pouvons analyser le cas d'un dernier en supposant qu'aucun des termes des deux corrélogrammes n'est significativement différent de zéro ; il s'agira du modèle ARIMA (0, 1,0). ï ï I.4.3. Etape n°3 : Estimation des paramètres ï La sortie des résultats de SPSS concernant le premier modèle est le suivant : ï ï Tableau 31 : Description du modèle 3
ï ï Tableau 32 : Paramètres du modèle ARIMA.
ï ï ï ï ï ï ï Ainsi le paramètre estimé est de 0,372. ï En procédant de la même façon on obtient les paramètres des trois modèles potentiels qui sont résumés dans le tableau suivant : ï ï Tableau 33 : Résumé des paramètres des trois modèles.
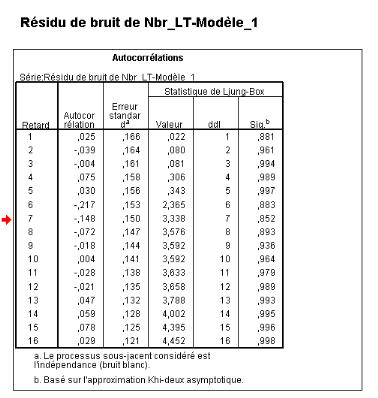
ï ï ï ï I.4.4. Etape n°4 : vérification de la justesse du modèle ï Pour vérifier la justesse du modèle, nous disposons une batterie de tests qui permettent d'accepter ou de rejeter le modèle choisi. · Test sur les paramètres : ï Les coefficients des deux modèles (ARIMA (1,1, 0) et ARIMA (0, 1,1)) sont significativement différents de zéro au seuil de 5%. En effet leurs p-value sont inférieurs à 0,05 (voir tableau ci-dessus). ï En revanche, les deux coefficients et ? du modèle ARIMA (1, 1,1) ne sont pas différents de zéro au seuil de 5%. Ceci conduit à écarter ce modèle de la suite de l'analyse. ï Le test sur les paramètres ne s'applique pour le modèle ARIMA (0, 1,0). · Test sur les résidus (test de bruit blanc) ï Lorsque le processus est bien estimé, les résidus (écart entre les valeurs observées et les valeurs estimées par le modèle) doivent se comporter comme un bruit blanc. ï On doit vérifier qu'il n'existe aucune autocorréllation ou autocorrélation partielle significativement non nulle pour le processus étudié, ainsi on étudie les autocorrélogrammes simples (ACF) et partiels (PACF) des résidus chaque processus. ï ï Ainsi, pour le premier modèle ARIMA (1, 1,0) nous avons les autocorrélogrammes suivants : ï Figure 23 : Corrélogramme simple des résidus du NLT_100_HAB- modèle_1.
ï ï ï ï Figure 24 : Corrélogramme partiel des résidus du NLT_100_HAB- modèle_1.
ï ï ï ï Au regard de ces graphiques, toutes les corrélations ne peuvent pas être considérées comme significativement différentes de 0. Nous pouvons donc consulter la statistique de Ljung et Box afin de tester si le processus est bien un bruit blanc. ï ï Test global à partir de la statistique de Ljung-Box ï Le test de Ljung-Box pour un ordre K, correspond à l'hypothèse nulle : H0 : ñk = 0 k K et est construit de la façon suivante : ï ï Avec K = N/4, dans notre cas on prend K=8 ï La sortie de SPSS concernant la statistique Ljung-Box pour le premier modèle ï ARIMA (1, 1,0) est le suivant : ï ï Tableau 34 : Test de validité du modèle à travers les résidus.
ï ï ï ï Toutes les probabilités (sig) sont supérieures à 0,05 ; nous pouvons donc conclure quant à la validité de notre modèle ARIMA (1, 1,0). ï La même démarche nous permet d'accepter les deux autres modèles ARIMA (0, 1,1) et ARIMA (0, 1,0) dont les valeurs relatives à la statistique de Ljung-Box sont résumées dans le tableau suivant : ï ï Tableau 35 : Test global de Ljung-Box pour les deux modèles ARIMA (0, 1,0) et ï ARIMA (0, 1,1) générant éventuellement la série du nombre de lignes téléphoniques
ï ï Sont donc en concurrence trois modèles. Dressons un tableau récapitulatif des éléments qui vont nous permettre de trancher : ï ï Tableau 36 : Tableau récapitulatif des éléments permettant de choisir le modèle adéquat (critères AIC et SCB).
ï ï Les statistiques AIC et SBC mesurent la qualité d'ajustement du modèle. AIC est le critère d'information d'Akaike et SBC est le critère bayesien de Schwartz. Nous utilisons ces critères pour choisir entre différents modèles estimés, le modèle qui a les critères AIC et SBC les plus faibles (ce modèle étant le meilleur). ï Ici, l'ARIMA (0, 1,1) a ses deux critères AIC et SBC inférieurs à ceux de l'ARIMA (1, 1,0) et ARIMA (0, 1,0). Modèle retenu : ARIMA (0, 1, 1). ï Le résumé des étapes qui nous ont permis de déterminer le processus final générant la série des nombres de lignes téléphoniques est le suivant : ï Série initiale : Xt {Série des nombres de lignes téléphoniques} ï Série différenciée : Ut = (1-B) Xt ï Le modèle final retenu pour la série {Xt} est le modèle ARIMA (0, 1,1) suivant :
ï ï I.4.5. Etape n°5 : Elaboration des prévisions ï Le tableau suivant présente les valeurs réelles et valeurs simulées à partir du modèle estimé, aussi bien pour la période initiale (1975-2008) que pour la période des prévisions (2009-2020). ï ï Tableau 37 : Tableau des valeurs réelles et valeurs simulées à partir du modèle estimé ï ARMA (0, 1,1).
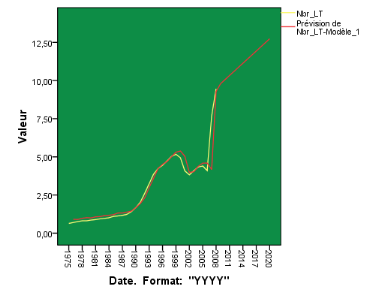
ï ï ï L'erreur relative18(*) moyenne est de 11%, elle est considérée faible, ceci traduit le faible écart entre les valeurs prédites et les valeurs réelles. On peut dire alors que la capacité prédictive de ce modèle est bonne. ï ï I.4.6. Etape n°6 : Vérification des prévisions obtenues ï Pour vérifier la qualité des prévisions obtenues, on construit le graphe des valeurs réelles et celui des valeurs simulées que l'on compare afin de voir l'éventuel écart ou rapprochement entre les courbes. ï Figure 25 : Graphe des valeurs réelles et des valeurs simulées.
ï ï ï ï Nous remarquons que le graphe(en jaune) des valeurs réellement observées « colle » sur toute la période d'étude avec celui(en rouge) des valeurs estimées par le modèle, ceci montre que le processus choisi donne des prévisions correctes. ï En utilisant les prévisions calculées, on a un constate un taux de croissance moyen annuel de 2% du nombre de lignes téléphoniques pour 100 habitants pour la période 2009-2020 contre un taux de 7% pour la période de 1975-2008. ï Ce taux de 2%, relativement faible pourrait s'expliquer par le fait que l'augmentation des opérateurs privés a entrainé un recours à la téléphonie mobile par la population marocaine ; ce qui se traduit par une baisse du raccordement à un réseau fixe. Toutefois l'augmentation élevée pour la première période se trouve justifier puisque la population n'avait pas d'autres choix que la téléphonie fixe. Cependant, il faut noter que le taux de 2% pour cette période de 11 ans (2009-2020) est élevé comparativement à la même période antérieure de 11 ans (1998-2009).Cela pourrait trouver une explication par l'arrivée du nouvel opérateur Wana en 2007 qui fournit des offres très intéressantes de la téléphonie fixe à la portée de bon nombre de citoyens. ï ï En appliquant la même démarche pour l'autre série des indicateurs que sont le nombre d'ordinateurs personnels (pour 100 habitants) c'est-à-dire d'ordinateurs conçus pour n'être utilisés que par une seule personne, nous présentons seulement les résultats des prévisions pour cet indicateur et nous renvoyons les détails sur les étapes du modèle à l'annexe (Annexe n° I). ï ï Tableau 38 : Prévisions du nombre d'ordinateurs personnels pour 100 habitants.
ï ï L'erreur relative moyenne pour ce modèle est également considérée faible (15%), ce qui nous permet de dire que la capacité prédictive de ce modèle est aussi bonne. ï On constate à travers les prévisions faites ,une augmentation considérable du nombre d'ordinateurs pour 100 habitants d'ici 2015 ; cela trouve une explication par les efforts engagés par les pouvoirs publics pour promouvoir les TIC dans les années à venir. Nous pouvons citer entre autres le projet Injaz à travers lequel une quantité importante d'ordinateurs est mise à la disposition des étudiants. * 18 La formule de l'erreur relative est la suivante ER = |Valeur réelle - Valeur prédite | / Valeur réelle |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||