CHAPITRE III. CIBLAGE DES
OFFRES [3,7]
III.1 Définition
Définition 1
On dispose d'un ensemble X de N données
étiquetées. Chaque donnée xi est
caractérisée par P attributs et par sa classe yi € Y. Dans
un problème de classification, la classe prend sa valeur parmi un
ensemble fini. Le problème consiste alors, en s'appuyant sur l'ensemble
d'exemples
X =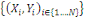 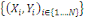 À prédire la classe de toute nouvelle donnée x À prédire la classe de toute nouvelle donnée x
  D. D.
On parle de classification binaire quand le nombre de classes
|Y| est 2 ; il peut naturellement être quelconque. Dans tous les cas, il
s'agît d'un attribut qualitatif pouvant prendre un nombre fini de
valeurs.
Dans l'absolu, une donnée peut appartenir à
plusieurs classes : c'est alors un problème multi-classes. Ici, on
considère que chaque donnée appartient à une et une seule
classe.
Définition 2
Un exemple est une donnée pour laquelle on dispose
de sa classe. On utilise donc un ensemble d'exemples classés pour
prédire la classe de nouvelles données ; c'est une tâche
d'« apprentissage à partir d'exemples », ou de «
apprentissage supervisé ».
Définition 3
Un « classeur » est une procédure (un
algorithme) qui, à partir d'un ensemble d'exemples, produit une
prédiction de la classe de toute donnée.
D'une manière générale, un classeur
procède par « induction » : à partir d'exemples (donc
de cas particuliers), on construit une connaissance plus
générale. La notion d'induction de connaissances implique la
notion de « généralisation » de la connaissance :
à partir de connaissances éparses, les exemples, on induit une
connaissance plus générale. Naturellement, même si l'on
suppose que la classe des étiquettes n'est pas erronée, il y a un
risque d'erreur lors de la généralisation ; ce risque est
quantifié par la notion de « taux d'échec », ou
d'« erreur en généralisation ».
Quand on tente d'induire de la connaissance, il faut
déterminer, au moins implicitement, la pertinence des attributs pour la
prédiction de l'étiquette d'une donnée quelconque : c'est
cela « généraliser ». D'une manière ou d'une
part, explicitement ou pas, généraliser implique de construire un
modèle des données.
La taille de ce modèle est un paramètre
important. à l'extrême, il est aussi gros que l'ensemble des
exemples : dans ce cas, on n'a rien appris, rien
généralisé et on est incapable d'effectuer une
prédiction fiable pour une donnée qui ne se trouve pas dans
l'ensemble des exemples : on a sur-appris.
A un autre extrême, on peut n'avoir appris que les
proportions des différentes étiquettes dans l'espace des
données : par exemple, 1=3 des données sont bleues et les autres
sont rouges, cela sans lien avec la description des données ;
prédire la classe revient alors à tirer la classe au hasard avec
ces proportions un tiers/deux tiers : on a pris trop de recul et on n'est plus
capable d'effectuer une prédiction fiable pour une donnée
particulière.
Entre ces deux extrêmes, il y a un juste milieu ou le
modèle a pris du recul par rapport aux exemples, a su extraire les
informations pertinentes du jeu d'exemples pour déterminer
l'étiquette de n'importe quelle donnée avec une
probabilité élevée de succès ; le modèle est
alors de taille modérée et la probabilité d'erreur de ce
modèle est la plus faible que l'on puisse obtenir : on a un
modèle optimisant le rapport qualité/prix, i.e.
probabilité d'effectuer une prédiction correcte/coût du
modèle. La recherche d'un modèle optimisant ce rapport est
l'objectif de l'apprentissage automatique, lequel est l'un des outils
indispensables pour la réaliser de la fouille de données.
On distingue deux grands types de classeurs :
Ø ceux qui utilisent directement les exemples pour
prédire la classe d'une donnée ;
Ø ceux pour lesquels on a d'abord construit un
modèle et qui, ensuite, utilisent ce modèle pour effectuer leur
prédiction.
Le problème de classification présente de
nombreuses difficultés ou problèmes à résoudre tels
que :
Ø Méthode d'induction du classeur ;
Ø Comment utiliser le classeur obtenu ;
Ø Comment évaluer la qualité du classeur
obtenu : taux d'erreur ou de succès ;
Ø Comment traiter les attributs manquants dans le jeu
d'apprentissage ;
Ø Comment traiter les attributs manquants dans une
donnée à classer ;
Ø Estimer la tolérance au bruit : le bruit
concerne ici la valeur des attributs de l'exemple avec lequel on construit le
classeur.
| 

