I.3.6 Les variables à
descriptions modales
C'est le cas d'une variable Yh qui peut être
décrite par une fonction définie sur le domaine d'observation
0h dans [0,1].
I.3.7 Les variables
taxonomiques ou structurées
Les domaines d'observation des variables de classification
peuvent être munis parfois de connaissances supplémentaires
appelées connaissances du domaine. Ces connaissances
supplémentaires sont définies dans le cas de descriptions
univaluées mais peuvent être prises en compte dans un traitement
sur des descriptions multivaluées (exemple : dans le calcul de la
mesure de ressemblance entre les individus au cours d'un processus de
classification automatique).
Il arrive par exemple qu'un expert puisse fournir une
structuration des valeurs du domaine d'observation sous la forme d'un arbre
ordonné, d'un graphe orienté, etc. Une variable dont le domaine
d'observation est représenté par une structure
hiérarchique est dite variable taxonomique ou encore
structurée.
I.4. Les mesure de
ressemblance
Tout système ayant pour but d'analyser ou d'organiser
automatiquement un ensemble de données ou de connaissances doit
utiliser, sous une forme ou une autre, un opérateur capable
d'évaluer précisément les ressemblances ou les
dissemblances qui existent entre ces données.
La notion de ressemblance (ou Proximité) a fait l'objet
d'importantes recherches dans des domaines extrêmement divers. Pour
qualifier cet opérateur, plusieurs notions comme la similarité,
la dissimilarité ou la distance peuvent être utilisées.
I.4.1 Définition
Nous appelons similarité ou dissimilarité
toute application à valeurs numériques qui permet de mesurer le
lien entre les individus d'un même ensemble. Pour une
similarité le lien entre deux individus sera d'autant plus fort que sa
valeur est grande. Pour une dissimilarité le lien sera d'autant plus
fort que sa valeur de dissimilarité est petite
I.4.2 Indice de
dissimilarité
Un opérateur de ressemblance 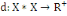 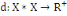 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 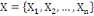 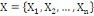 est dit indice de dissimilarité (ou dissimilarité), s'il
vérifie les propriétés suivantes : est dit indice de dissimilarité (ou dissimilarité), s'il
vérifie les propriétés suivantes :
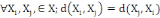 1. 1. 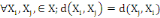 (propriété de symétrie) (propriété de symétrie)
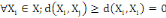 2. 2. 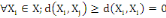 (propriété de positivé) (propriété de positivé)
I.4.3 Distance
Un opérateur de ressemblance 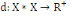 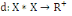 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 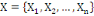 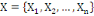 est dit distance, s'il vérifie en plus des deux
propriétés 1 et 2 les propriétés d'identité
et d'inégalité triangulaire suivantes : est dit distance, s'il vérifie en plus des deux
propriétés 1 et 2 les propriétés d'identité
et d'inégalité triangulaire suivantes :
3.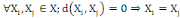 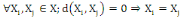 (propriété de d'identité) (propriété de d'identité)
4.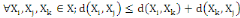 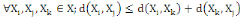 (inégalité triangulaire) (inégalité triangulaire)
1.4.4 Indice de
similarité
Un opérateur de ressemblance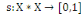 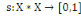 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 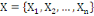 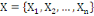 est dit indice de similarité (ou similarité), s'il
vérifie en plus de la propriété de symétrie (1) les
deux propriétés suivantes : est dit indice de similarité (ou similarité), s'il
vérifie en plus de la propriété de symétrie (1) les
deux propriétés suivantes :
5.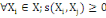 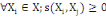 (propriété de positivité) (propriété de positivité)
6.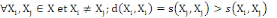 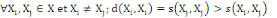 (propriété de maximisation). (propriété de maximisation).
Il convient de noter ici que le passage de l'indice de
similarité s à la notion duale d'indice de dissimilarité
(que nous noterons d), est trivial. Etant donné smax la
similarité d'un individu avec lui-même (smax= 1 dans le cas d'une
similarité normalisée), il suffit de poser :
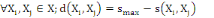
| 

