I. 5 Mesure de
ressemblance entre individus à descriptions classiques
Le processus de classification vise à structurer les
données contenues dans X={X1, X2, ...,
Xn} en fonction de leurs ressemblances, sous forme d'un ensemble de
classes à la fois homogènes et contrastées.
L'ensemble d'individu X est décrit
généralement sur un ensemble de m variables Y= {Y1,
Y2,..., Ym} définies chacune par :
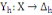
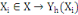
Où Äk est le domaine d'arrivée
de la variable Yh.
En conséquence, les données de classification
sont décrites dans un tableau Individus-variables où chaque case
du tableau contient la description d'un individu sur une des m variables. Ce
tableau Individus-Variables est en général un tableau
homogène qui peut être de type quantitatif (où toutes les
variables sont quantitatives) ou qualitatif (où toutes les variables
sont qualitatives).
I.5.1 Tableau de données
numériques (continues ou discrètes)
La distance la plus utilisée pour les données de
type quantitatives continues ou discrètes est la distance de Minkowski
d'ordre á définie dans Rm par :
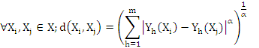
Où 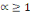 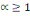 , ,   si : si :
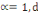 Ø Ø 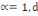 est la distance de city-block ou Manhattan. est la distance de city-block ou Manhattan.
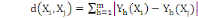 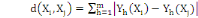
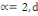 Ø Ø 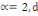 est la distance Euclidienne classique. est la distance Euclidienne classique.
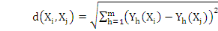 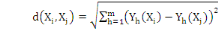
Dans ce travail on ne considérera pas des individus
à description symbolique. C'est pourquoi, nous n'avons pas
définie la mesure de ressemblance correspondante à ce type de
données.
I.6.Le bruit
Il importe de ne pas faire comme si toutes les données
ont une valeur connue, et encore moins une valeur valide ; il faut donc
gérer des données dont certains attributs ont une valeur inconnue
ou invalide ; on dit que les données sont « bruitées ».
La simple élimination des données ayant un attribut dont la
valeur est inconnue ou invalide pourrait vider complètement la base de
données ! On touche le problème de la collecte de données
fiables qui est un problème pratique très difficile à
résoudre. En fouille de données, il faut faire avec les
données dont on dispose sans faire comme si on disposait des valeurs de
tous les attributs de tous les individus.
I.7.Différentes
tâches d'extraction d'information
Le datamining comprend 5 tâches principales
Ø Classification
Ø Clustering (Segmentation)
Ø Recherche d'associations
Ø Recherche de séquences
Ø Détection de déviation
I.7.1. Problème de
classification
Dans les problèmes, chaque donnée est
affectée d'une caractéristique, par exemple une couleur.
Supposons que l'ensemble des couleurs possibles soit fini et de faible
cardinalité. Le problème de classification consiste alors
à prédire la couleur d'un point quelconque étant
donné un ensemble de points colorés.
Géométriquement, cela revient à trouver
un moyen de séparer les points les uns des autres, en fonction de leur
couleur. S'il n'y a que deux couleurs, un simple (hyper)plan peut suffire
à les séparer ; ceux d'une certaine couleur sont d'un coté
de l'hyperplan, les autres étant de l'autre coté. Dans ce cas,
les points sont linéairement séparables (séparables par un
objet géométrique qui ressemble à une droite, un hyperplan
pour être plus précis au niveau du vocabulaire).
Généralement, des points d'une couleur
donnée se trouvent du mauvais coté de l'hyperplan. Cela peut
résulter d'erreurs dans l'évaluation des attributs (on s'est
trompé en mesurant certains attributs, ou en attribuant sa couleur
à la donnée) ; dans ce cas, les données sont
bruitées. Cela peut aussi être intrinsèque aux
données qui ne peuvent pas être séparées
linéairement. Il faut alors chercher à les séparer avec un
objet non hyper planaire.
| 

