CHAPITRE II. LA SEGMENTATION [1, 4, 5, 12, 15, 18, 22]
L'objectif de la classification est le suivant : on dispose de
données non étiquetées. On souhaite les regrouper par
données ressemblantes. Cette manière de définir
intuitivement l'objectif de la classification cache la difficulté de
formaliser la notion de ressemblance entre deux données. Au-delà
des algorithmes existants, une bonne partie de l'art à acquérir
consiste ici à imaginer cette formalisation. Ainsi, soit un ensemble X
de N données décrites chacune par leurs P attributs. La
classification consiste à créer une partition ou une
décomposition de cet ensemble en groupes telle que :
Critère 1 : les données appartenant au
même groupe se ressemblent ;
Critère 2 : les données appartenant
à deux groupes différents soient peu ressemblantes.
Clairement, la notion de « ressemblance » doit
être formalisée. Cela est fait en définissant une distance
entre tout couple de points du domaine D. Toute la difficulté est
là : définir correctement cette distance. De là
dépend le résultat de la segmentation. Si l'utilisation d'une
distance euclidienne est a priori une bonne idée, ce n'est pas la seule
possibilité, loin s'en faut. En particulier, on a rarement
d'informations concernant la pertinence des attributs : seuls les attributs
pertinents doivent intervenir dans la définition de la distance. De
plus, dans la segmentation que l'on aimerait obtenir, la pertinence des
attributs peut dépendre du groupe auquel la donnée appartient.
Ne connaissant pas les critères de partitionnement a priori, on doit
utiliser ici des algorithmes d'apprentissage non supervisés : ils
organisent les données sans qu'ils ne disposent d'information sur ce
qu'ils devraient faire.
Il existe deux grandes classes de méthodes :
Ø non hiérarchique : on décompose
l'ensemble d'individus en k groupes ;
Ø hiérarchique : on décompose l'ensemble
d'individus en une arborescence de groupes.
On peut souhaiter construire une décomposition :
Ø telle que chaque donnée appartienne à
un et un seul groupe : on obtient une partition au sens mathématique du
terme ;
Ø dans laquelle une donnée peut appartenir
à plusieurs groupes;
Ø dans laquelle chaque donnée est
associée à chaque groupe avec une certaine probabilité.
Notons que le problème de segmentation optimale en k
groupes est NP- complet. Il faut donc chercher des algorithmes calculant une
bonne partition, sans espérer être sûr de trouver la
meilleure pour les critères que l'on se sera donnés.
Idéalement, dans un processus de fouille de données, la
segmentation doit être une tâche interactive : une segmentation est
calculée et proposée à l'utilisateur qui doit pouvoir la
critiquer et obtenir, en fonction de ces critiques, une nouvelle segmentation,
soit en utilisant un autre algorithme, soit en faisant varier les
paramètres de l'algorithme, ...
Définition 1 :
Soit X un ensemble de données, chacune
décrite par P attributs. On nomme « centre de gravité »
g de X une donnée synthétique dont chaque attribut est
égal à la moyenne de cet attribut dans X. Soit, g = (a1, a2, ...,
a3).
Hartigan, est un des premiers à discuter
différents choix possibles du nombre de classes. Au fil des
années, plusieurs statistiques ont été proposées
afin de décider le nombre de classes à choisir et peuvent
être utilisées comme règle d'arrêt dans le cadre des
méthodes hiérarchiques. Elles utilisent
généralement les sommes des carrés inter - groupes, ainsi
que les sommes des carrés intra - groupes, notées respectivement
par B et W pour une partition P en k
classes {c1....Ck}:
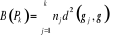
Où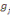 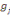 , j = 1, ..., k, est le centre de gravité de la classe Cj
et g le centre de gravité de l'ensemble des objets. , j = 1, ..., k, est le centre de gravité de la classe Cj
et g le centre de gravité de l'ensemble des objets.
Nj représente le poids de la classe
Cj
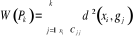
Où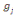 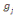 , j = 1, ..., k, est le centre de gravité de la classe Cj
On peut également exprimer ces mesures à l'aide des notions
d'inertie d'un groupe. , j = 1, ..., k, est le centre de gravité de la classe Cj
On peut également exprimer ces mesures à l'aide des notions
d'inertie d'un groupe.
Soit P, une partition en k classe {C1... Ck} alors
on obtient :

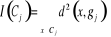
Où 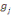 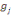 , j = 1, ..., k, est le centre de gravité de l'ensemble des
points de Cj avec g = , j = 1, ..., k, est le centre de gravité de l'ensemble des
points de Cj avec g = 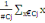 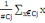 avec avec
#Cj représentant le nombre de points dans Cj.
D'après le théorème de Koeng - Huygens, l'inertie totale T
ne dépend pas de la partition choisie et est exprimée par T = W +
B et vaut T= 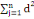 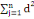 (xi, g). L'inertie intra- classe W est un critère
classique d'évaluation d'une partition, mesurant
l'homogénéité des classes de la partition. Par
conséquent, il suffit de trouver une partition qui minimise
W(Pk). De manière équivalente, on cherchera à
maximiser B(Pk) l'inertie interclasse qui mesure la
séparation des classes. Dans ce cas, une partition vérifie les
principes de cohésion interne et d'isolation externe (xi, g). L'inertie intra- classe W est un critère
classique d'évaluation d'une partition, mesurant
l'homogénéité des classes de la partition. Par
conséquent, il suffit de trouver une partition qui minimise
W(Pk). De manière équivalente, on cherchera à
maximiser B(Pk) l'inertie interclasse qui mesure la
séparation des classes. Dans ce cas, une partition vérifie les
principes de cohésion interne et d'isolation externe
II.1.La segmentation
hiérarchique
Il s'agit de représenter des individus sur un arbre
hiérarchique, dont chaque noeud porte le nom de ''Palier'' ; chaque
palier d'une hiérarchie sur I correspond à un groupe d'individus
de I. Ces individus sont plus proches entre eux (au sens de la mesure de
ressemblance choisie) que les niveaux de palier correspondant sont bas. On peut
détenir une hiérarchie de la manière suivante :
Soit X une matrice de données n x p définie par
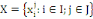 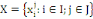 où I est un ensemble de n objectifs (lignes,
observations, instances, individus) et J est un ensemble de p variables
(colonnes, attributs) où I est un ensemble de n objectifs (lignes,
observations, instances, individus) et J est un ensemble de p variables
(colonnes, attributs)
| 

