II.3.5.3. Le schéma en constellation
Dans un schéma en constellation, plusieurs
modèles dimensionnels se partagent certaines dimensions. En effet, il
est la fusion de plusieurs modèles en étoile qui utilisent des
dimensions communes. Il comprend en conséquence plusieurs faits et des
dimensions communes ou non. Dans l'exemple de la figure ci-dessous, nous avons
deux dimensions qui sont partagées : les dimensions « TEMPS »
et « GEOGRAPHIE ».
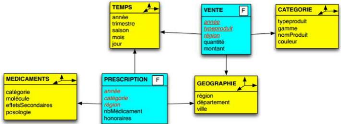
Figure II. 7: Exemple du schéma en
constellation
24
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.3.6. Modélisation logique des entrepôts de
données
Le niveau logique des ED présente la description de la
base multidimensionnelle qui sera utilisée selon la technologie choisie.
On distingue trois approches principales pour l'implémentation de
serveurs OLAP : Relational OLAP (ROLAP), Multidimensional OLAP (MOLAP) et
Hybrid OLAP (HOLAP) (Batouré, 2010). Les différents concepts
liés à OLAP sont les cubes de données, les
opérations OLAP.
II.3.7. Alimentation des entrepôts de données
(ETL)
Après la conception, vient la phase d'acquisition pour
alimenter l'entrepôt de données. Il faut déterminer et
recenser les données à entreposer. Nous recherchons ici des
données dans les ressources de l'entreprise. La démarche se
subdivise en un processus défini sous l'acronyme ETL (Extract,
Transform, Load), ETC en français (Extraction, Transformation,
Chargement). Ce processus constitue la phase de migration des données de
production dans le système décisionnel après qu'elles
aient subi des opérations de sélection, de nettoyage et de
reformatage dans le but de les homogénéiser. Cette phase
constitue une étape importante et très chronophage dans la mesure
où on l'estime à environ 80% du temps de mise en place de la
solution décisionnelle. (Simitsis et al., 2010; Jovanovic et al., 2012;
Papastefanatos et al., 2012; Akkaoui et al., 2011; Muñoz et al.,
2009).
II.3.7.1. Extraction des données sources
Selon (Kimball, 2005), « L'extraction est la
première étape du processus d'apport de données à
l'entrepôt de données. Extraire, cela veut dire lire et
interpréter les données sources et les copier dans la zone de
préparation en vue de manipulations ultérieures. »
Avant d'extraire les données des sources, elles subissent d'abord une
sélection afin de déterminer celles qui vont alimenter l'ED. En
effet, toutes les données sources ne sont pas forcément utiles.
Il faut soigneusement trier les données utiles qui feront l'objet
d'extraction pour enrichir l'ED selon les besoins d'analyse de l'entreprise.
25
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
L'extraction peut se faire à travers un outil
d'alimentation qui doit travailler de façon native avec les SGBD qui
gèrent les données sources. Ou alors l'on peut créer des
programmes extracteurs ; seulement, cette approche présente le risque de
faire des extractions erronées, incomplètes et qui peuvent
biaiser l'ED. Il faut alors gérer les anomalies en les traitant et en
gardant une trace.
L'extraction doit se faire conformément aux
règles précises du référentiel. Elle ne doit pas
non plus perturber les activités de production. Il faut faire attention
aux données cycliques. Celles qu'on doit calculer à chaque
période, pour pouvoir les prendre en considération. L'extraction
peut se faire en interne selon l'horloge interne ou par un planificateur ou par
la détection d'une donnée cible (de l'ED) ; ou en externe par des
planificateurs externes. Les données extraites doivent être
marquées par «horodatage» afin qu'elles puissent être
pistées. Il existe trois stratégies de détection de
changement :
· Colonnes d'audit : la colonne
d'audit, est une colonne qui enregistre la date d'insertion ou du dernier
changement d'un enregistrement. Cette colonne est mise à jour soit par
des triggers ou par les applications opérationnelles ;
· Capture des logs : On utilise les
fichiers logs des systèmes sources afin de détecter les
changements (généralement logs du SGBD). En plus de l'absence de
cette fonctionnalité sur certains outils ETL du marché,
l'effacement des fichiers logs engendre la perte de toute information relative
au changement ;
· Comparaison avec le dernier chargement
: le processus d'extraction sauvegarde des copies des chargements
antérieurs, de manière à procéder à une
comparaison lors de chaque nouvelle extraction. Cette méthode permet
d'éviter la perte d'un nouvel enregistrement des données de
production.
| 

