II.3.7.2. Transformation des données
La transformation est une suite d'opérations qui a
pour but de rendre les données cibles homogènes afin qu'elles
puissent être traitées de façon cohérente. Par
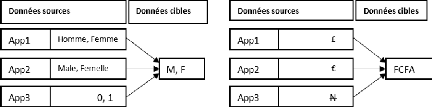
exemple, soient trois applications ayant des bases de données
différentes qui ont chacune sa structure, la transformation peut
consister à faire des opérations illustrées dans la figure
ci-dessous :
Chapitre II : Généralités sur les
entrepôts de données et les SIG
26
Bassirou Mohamet
Figure II. 8: Exemple d'opérations de
transformation
Elle consiste à filtrer les données afin
d'éliminer les données aberrantes: données sans valeurs ou
avec des valeurs manquantes. Souvent dans les bases de production, certaines
données sont sémantiquement fausses. Pour avoir une alimentation
de qualité, il faut avoir une bonne connaissance des données
à entreposer et des règles qui les régissent. Et savoir
corriger les données pour les doter d'un vrai sens sémantique.
Pour ce faire, on peut dédoubler des données pour gagner au
niveau de la cohérence. Les différentes tâches de la
transformation peuvent se résumer en :
· La consolidation des données ;
· La correction des données et élimination de
toute ambiguïté ;
· L'élimination des données redondantes ;
· Compléter et renseigner les valeurs manquantes.
Cette opération se solde par la production
d'informations dignes d'intérêt pour l'entreprise. En effet,
l'ensemble des données sources, après nettoyage ou transformation
d'après des règles précises ou par application de
programmes, seront restructurées et converties dans un format cible. Il
faut synchroniser les données pour que les valeurs
agrégées obtenues soient cohérentes, avant de passer
à la phase de chargement.
II.3.7.3. Chargement des données (Loading)
C'est l'opération qui consiste à charger les
données nettoyées dans l'entrepôt de données. Cette
opération est généralement assez longue en fonction du
volume de données à charger. Il faut alors mettre en place une
stratégie afin d'assurer des bonnes conditions à sa
réalisation.
Chapitre II : Généralités sur les
entrepôts de données et les SIG
II.3.7.4. Stratégies d'alimentation de l'ED
Le processus de l'alimentation peut se faire par l'utilisation
de plusieurs
stratégies. Le choix de la stratégie de
l'alimentation dépend de la disponibilité et
l'accessibilité des données sources. On distingue en effet trois
stratégies:
· Push : la logique de
chargement se trouve dans le système de production. Il « pousse
» les données vers la zone de préparation lorsque c'est
nécessaire. Malheureusement, si le système est occupé, il
ne poussera jamais les données ;
· Pull : contrairement
à Push, la logique du Pull se trouve dans la zone de préparation
des données. Il « tire » les données de la source vers
la zone de préparation. L'inconvénient de cette méthode
est qu'elle peut surcharger le système s'il est en cours
d'utilisation.
· Push-pull : c'est la
combinaison des deux méthodes. La source prépare les
données à envoyer et indique à la zone de
préparation qu'elle est prête. La zone de préparation va
alors récupérer les données.
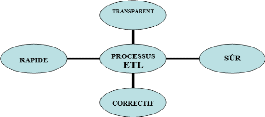
D'après (Kimball, 2004), le processus ETL doit
répondre à certaines exigences de qualité de
données. Pour ce faire, un processus ETL doit être :
· Sûr : le processus doit assurer
l'acheminement des données et leur livraison.
· Rapide : la quantité de
données manipulées pouvant causer des lenteurs, le processus
d'alimentation doit palier à ce problème et assurer le chargement
du Data Warehouse dans des délais acceptables.
· Correctif : le processus
d'alimentation doit apporter les correctifs nécessaires pour
améliorer la qualité des données ;
· Transparent : le processus doit
être transparent afin d'améliorer la qualité des
données.
27
Bassirou Mohamet
Figure II. 9: Objectifs de qualité de
données
28
Bassirou Mohamet
Chapitre II : Généralités sur les
entrepôts de données et les SIG
Dans ce chapitre, nous avons étudié les SIG, ses
quelques solutions existantes et des différents concepts ou techniques
de mise en oeuvre qui peuvent intervenir lorsque l'on souhaite mettre sur pied
une application dans le domaine du BI. Les approches vues jusque-là nous
présentent distinctivement les SIG et les ED. Dans le chapitre suivant
nous aborderons l'étude des EDS et des outils de mise en oeuvre des
systèmes d'aide à la décision spatiale.
29
Bassirou Mohamet
Chapitre III : Les EDS et outils de mise en oeuvre
| 

