|

I
REPUBLIQUE DEMOCRATIQUE DU CONGO
MINISTERE DE
L'ENSEIGNEMENT SUPERIEUR ET UNIVERSITAIRE
UNIVERSITE SAINT LAURENT DE KANANGA
« USLKA »
B.P.70 KANANGA
FACULTE DE SCIENCES INFORMATIQUES
« Modélisation et implémentation
d'un système
décisionnel pour la gestion du personnel à
la Régie
des Voies Aériennes de Kananga ».
Présenté par KABEYA ILUNGA
Paulin
Mémoire présenté et défendu en
vue de l'obtention du Grade de Licencié en Sciences
Informatiques.
Option : Conception de
système d'information et programmation Avancée
Octobre 2021

EPIGRAPHE
« Il faut appeler science que l'ensemble des recettes
qui réussissent
toujours. Tout le reste est littérature, car
la science n'a pas de patrie ».
Paulin KABEYA ILUNGA

IN MEMORIAM

A vous cher père François ILUNGA,
chère mère
Marthe BUKAWU et très chère
grand-mère
Madeleine KABEDI, que la terre de nos
ancêtres
avait arraché si tôt, vos souvenirs
innombrables
marquants ne m'ont pas laissé
indifférent, de
là où vous êtes, sachez que votre
semence a porté
des fruits. Je ne saurai vous
oublier.
Paulin KABEYA ILUNGA
III
DEDICACE
A ma charmante épouse Jeannette
MBOMBO
En témoignage de nos moments de liesse, de
fraternité, d'amour et des épreuves difficiles qu'on a pu
surmonter ensemble et de tout ce qu'on a partagé et qu'on
partagéra toujours ensemble. Ton soutien moral,
matériel
et financier ainsi que ta compréhension ont toujours
été présents aux
moments les plus difficiles.
Aucun mot, aucune dédicace ne saurait exprimer mon
respect, ma
gratitude, pour m'avoir laissé la liberté
du choix, pour avoir eu confiance
en moi.
Je vous rends hommage par ce modeste travail en guise de
ma
reconnaissance éternelle et mon infini amour.
Paulin KABEYA ILUNGA
IV
REMERCIEMENTS
Le développement de tout homme implique des longues
années du dur labeur aux cours desquelles, il recherche par les
expériences vécues avec les autres et dans un silence
antérieur à pénétrer le mystère de son
être pour acquérir certaine maturité et donner un sens
à son existence.
Dans notre pèlerinage et plus
précisément durant l'élaboration de notre mémoire
de fin de cycle, des nombreuses personnes ont jouées des rôles
actifs, certaines par leurs conseils et dévouements, d'autres par leurs
soutiens moraux que matériaux.
Ainsi, au moment où nous publions notre
mémoire, nous nous sentons redevable envers eux. C'est pourquoi nous
voudrons nous acquitter de l'agréable devoir d'exprimer toute notre
reconnaissance à tous ceux qui de loin ou de prêt ont
contribué à donner à cette dissertation sa forme
actuelle.
Nos remerciements à notre Directeur le Professeur
Pierre KAFUNDA KATALAY pour son entière
disponibilité, son aide inestimable et ses conseils, sans lesquels ce
mémoire n'aurait pu aboutir.
Nous remercions de tout coeur le co-directeur de ce
mémoire en la personne de l'Ingénieur Cédrick
MUAMBA Muya pour ses différentes remarques et orientations dans
l'élaboration; qu'il trouve ici l'expression de nos sentiments de
gratitude.
Nous remercions également aussi les membres du
Comité de Gestion de l'Université Saint Laurent de Kananga pour
le suivi, disponibilité, leurs précieux conseils et remarques
constructives tout au long de nos cinq années d'études.
Que tous les enseignants de l'USLKA qui ont
contribué à notre formation, le long de ces cinq années
trouvent ici l'expression de ma gratitude et plus particulièrement
l'Assistant Pierrot MUKENDI ainsi que les Chefs des travaux Anaclet TSHIKUTU et
Nobla TSHILUMBA.
Mes remerciements s'adressent au professeur
Laurent LUMU NGALAMULUME Tu es l'être le plus cher sur terre,
toi qui a pris la place d'un parent et qui a toujours su être à
mon écoute et me réconforter au moment opportun ; à tes
encouragements et tes prières qui m'ont toujours soutenue et
guidé ; ta bonté, ton honnêteté, ta
générosité et tes grandes qualités humaines
demeurent pour moi le meilleur exemple à suivre.
A ma jolie soeur Ivette KABEDI, mes chers frères
Serge KAYEMBE et Jean-Pierre TSHITENGE ; nul mot ne saurait exprimer l'amour,
la tendresse et l'attachement que j'ai pour vous. Je vous dédie ce
travail en témoignage de l'amour et des liens de sang qui nous unissent.
Puissions-nous rester unis dans la tendresse et fidèles à
l'éducation que nous avons reçue.
V
Mes remerciements s'adressent aussi plus
particulièrement à mes Oncles : Martin MADIMBA LUKUSA et Hubert
BEYA pour leur soutien moral, matériel et financier ; que le bon Dieu
vous bénisse.
Mes remerciements à mes meilleurs amis : Emmanuel
KABIENA, Joseph NTUMBA, Jean KAYIMUSUMBA et Michel BITANGALO, je vous dis que
la cohorte est atteinte.
Je remercie également mes compagnons,
collaborateurs et collaboratrices : Josée-Lyska NTUMBA, Christine
TSHILANDA, Angel MBUYI et Christophe KALONGA.
Je ne peux clore cette page sans remercier mes camarades
de lutte : Achille MALUNDU et Judith TSHIBOLA eux qui ont souffert ensemble
avec moi.
Que toute personne qui de loin ou de près à
contribuer à mes études trouve ici l'expression de ma
gratitude.
Paulin KABEYA ILUNGA
VI
SIGLES
CUBE : Schéma Multidimensionnel
DGRKOC : Direction Générale des Recettes du
Kasaï Occidental
DW : Data Warehouse
ECD : Employé de Courte Durée
EFA : Employé de Fonction Auxiliaire
ELD : Employé de Longue Durée
ETL : Extraction Transformation an Loading
GKN : Général Kinshasa Company
HDD : Hard Drive Disk
HOLAP : Hybrid On Line Analytic Processing
MCD : Modèle Conceptuel de Données
MLD : Modèle Logique de Données
MOA : Maîtrise d'Ouvrage
MOE : Maître d'oeuvre informatique
MOLAP : Multidimensinnel On Line Analytic Processing
MPD : Modèle Physique de Données
OLAP : On Line Analytic Processing
OLTP : On Line Transaction Processing
OMG : Object Management Group
OMT : Obect Modeling Technique
OOSE : Object Oriented Software Engineering
PC : Personnal Computer
PV : Procès-Verbal
RAM : Radom Access Memory
ROLAP : Relational On Line Analytic Processing
RVA : Régie des Voies Aériennes
SABENA : Société Anonyme Belge pour
l'Exploitation de la Navigation Aérienne
SARL : Société à
Résponsabilité Limitée
SGBD : Système de Gestion de Base de Données
SID : Système d'Information Décisionnel
UML : Unified Modeling Language
VII
LISTE DE FIGURES
Figure 1 : Architecture
Générale d'un système décisionnel
Figure 2: schéma en étoile
Figure 3: schéma d'un modèle en
flocon
Figure 4: Exemple de schéma
multidimensionnel
Figure 5: Architecture d'un Data
Mart
Figure 6 : Architecture ROLAP
Figure 7: Architecture MOLAP
Figure 8 : Architecture HOLAP
Figure 9: Arbre de décision construit
à partir de l'attribut âge
Figure 10 : Arbre de décision
finale
Figure 11 : graphe connexe
Figure 12 : Arbres
Figure 13 : arborescence
Figure 14 : Diagramme de cas
d'utilisation de la gestion du personnel
Figure 15 : diagramme de
séquence de cas d'utilisation engager
Figure 16 : diagramme
d'activité de cas Engager
Figure 17 : diagramme de
séquence lister personnel
Figure 18 : diagramme
d'activité lister personnel
Figure 19 : diagramme de
séquence modifier_personnel
Figure 20 : diagramme
d'activité modifier personnel
Figure 21 : diagramme de classe de
la gestion du personnel
Figure 22 : SQL Server
Figure 23 : Microsoft SQL Server
Management Studio
Figure 24 : création de la
base de données
Figure 25 : nouvelle base de
données
Figure 26 : table
Figure 27 : Business Intelligence
Figure 28 : Assistant Source de
données
Figure 29 : Gestionnaire de
connexion
Figure 30 : Assistant source de
données
Figure 31 : Sélection des
tables
Figure 32 : création
dimensions
Figure 33 : création de
cube
VIII
LISTE DE TABLEAUX
Tableau 1 : Différence entre SGBD et
entrepôts de données
Tableau 2 : compare les
caractéristiques des systèmes
Tableau 3: le processus du
datamining.
Tableau 4: les taches et technique du
datamining.
Tableau 5: exemples pratiques
Tableau 6: Liste des matériels
existants
Tableau 7: Autres matériels
Tableau 8 : Dictionnaire de
données
Tableau 9 : Identification Engager
personnel
Tableau 10 : identification de
Lister personnel
Tableau 11 : identification de
modifier personnel
1
0. INTRODUCTION GENERALE
C'est lorsque la fumée des annonces se dissipe et
lorsque le tapage médiatique s'apaise que l'on peut voir,
éventuellement, les projets se mettre en place. L'innovation arrive sur
le terrain au moment où elle quitte la scène.
La raison d'être d'un Système d'Information
Décisionnel est l'établissement de ponts entre opérations
et stratégie, entre automatisation et conduite, entre détail et
synthèse, entre situation et évolution. On lui demande, en
quelque sorte, de faire le grand écart entre des notions
indépendantes ou opposées. On peut se demander pourquoi un tel
besoin apparaît aujourd'hui avec une telle ampleur.
En réalité, l'information décisionnelle
est une notion ancienne ; l'idée de Système d'Aide à la
Décision (Decision Support System) est en effet âgée d'un
bon quart de siècle. Elle est donc largement plus ancienne que toutes
les techniques auxquelles on l'associe aujourd'hui. Elle a toutefois
fondamentalement évolué depuis sa naissance. Cette
évolution a été rendue possible, mais non pas
provoquée, par l'innovation technologique.
En particulier, l'expansion actuelle des entrepôts de
données découle presque directement des nouvelles
caractéristiques de l'« écosystème » dans lequel
vivent les organisations. Dans un univers marqué par des
phénomènes de déréglementation et de
mondialisation, même si la portée de ces phénomènes
a été jusqu'à présent largement
exagérée, la compétition et le changement imposent un
nouveau cadre de prise de décisions et une nouvelle conception de la
stratégie. Cette nouvelle donne et affecte en premier lieu les
entreprises intervenant dans les secteurs les plus concurrentiels, pour
lesquelles l'adaptation au changement est une question de survie
immédiate.
Le modèle du commandement central, de l'automatisation
et du contrôle a posteriori, qui correspondait à l'environnement
plus stable des précédentes décennies, n'est pas assez
souple pour ce nouveau contexte.
C'est aujourd'hui la logique de la détection
avancée et de l'adaptation rapide qui tend à prévaloir, de
manière inégale mais réelle. Tout ceci implique
nécessairement une redistribution de la responsabilité
décisionnelle. Il en résulte une gigantesque dissémination
de l'information décisionnelle et un foisonnement de projets aussi
variés dans leur envergure que dans leur contenu.
Un modèle de données sans données ne
serait bien entendu qu'une coquille vide. A la problématique de la
modélisation succède donc naturellement celle de l'alimentation.
Or l'alimentation d'un entrepôt de données décisionnel
n'est pas qu'un problème de connectique et de transfert physique. C'est
même le problème politique, conceptuel et architectural le plus
délicat du système, et le plus susceptible de décider de
la réussite d'un projet.
Le marché met progressivement à notre
disposition un certain nombre d'outils et de composants susceptibles de jouer
un rôle dans la construction des solutions décisionnelles. Nous
croyons utile de résumer ici les grandes alternatives technologiques.
2
Enfin, il nous a semblé indispensable de
présenter le présent travail sur « la
modélisation et l'implémentation d'un système
décisionnel pour la gestion du personnel à la RVA Kananga
».
0.1. Choix et intérêt du sujet 0.1.1.
Choix du sujet
Nous avons choisi ce sujet pour deux raisons :
Aider les décideurs de la Régie des Voies
Aériennes du Kasaï Central d'avoir toutes les données
nécessaires à la prise de décision en un temps
réduit et d'éviter les erreurs dans l'analyse et
l'interprétation de données ;
La seconde réside sur l'obligation qu'à tout
étudiant de présenter et défendre un mémoire
à la fin du deuxième cycle en Informatique afin de faire la
liaison des théories apprises dans notre formation à la
pratique.
0.1.2. Intérêt du
sujet
Ce mémoire présente pour nous un triple
intérêt :
? Il nous permet d'obtenir le grade de Licencié en
Sciences Informatiques dès qu'il est défendu et accepté
;
? Pour la RVA Kasaï Central, cette étude permettra
d'améliorer son système de
gestion du personnel et surtout dans la prise de
décisions par les décideurs ; ? Pour les futurs chercheurs qui
embrasseront le domaine du système décisionnel, c'est
un document de référence.
0.2. Etat de la question
Dans cette partie, il nous convient de signaler que nous
n'avons pas la présentation de faire de ce mémoire une
originalité scientifique personnelle d'autant plus certains de nos
prédécesseurs ont déjà abordé ce sujet d'une
manière ou d'une autre. Parmi eux, voici ceux qui ont retenu notre
attention :
? MANKAMBA YANKUMBA Jean-Luc, UKA 2015-2016 : « Mise
en place d'un système décisionnel basé sur le Data Mart et
l'arbre de décision pour le recrutement du personnel à la DGRKOC
» ; il s'est penché sur les problèmes liés
à la gestion du personnel en général et en particulier sur
la gestion des recrutements.
Quant à nous, nous allons nous basés sur «
la modélisation et l'implémentation d'un système
décisionnel pour la gestion du personnel à la RVA Kananga »,
tout en se focalisant sur la gestion de recrutement, de congé ainsi
que la retraite du personnel de cette Régie des Voies
Aériennes.
3
0.3. Problématique et hypothèses 0.3.1.
Problématique
La problématique se présente dans toute
recherche scientifique comme un ensemble des préoccupations que posent
un chercheur et qui nécessite des réponses dès que l'on
descend sur terrain. Cela étant, elle est définie comme
l'ensemble des questions que l'on se pose devant un constat que soulève
une étude ou une recherche pour arriver à la
vérité.1
Ainsi, notre problématique se résume en ces termes
:
? Le déploiement d'un système décisionnel
pour la gestion du personnel pourra-t-il
aider les décideurs de la RVA Kasaï Central à
prendre des bonnes décisions ? ? La gestion du personnel tenue
manuellement donne-t-elle satisfaction?
? Comment le système décisionnel peut-il
contribué à l'amélioration de la prise de décision
?
0.3.2. Hypothèses
Les hypothèses sont définies comme des
suppositions liées à un phénomène donné dont
on veut se proposer de vérifier si elle est pertinente ou non à
travers la mise en oeuvre de diverses méthodes de
recherche.2
Les hypothèses sont des propositions des réponses
provisoires émises par le chercheur comme fil conducteur qui seront
infirmées ou affirmées.3
Nous pensons que le déploiement d'un système
décisionnel pour la gestion du personnel constituera une solution pour
pallier aux difficultés majeures dans la prise de décisions par
les décideurs; il permettra à la RVA de se doter d'un outil
rentable pour un bon rendement car il consiste au déploiement de Cube
afin de manipuler les données et fouiller ces dernières pour la
prise de décisions en un temps très court.
De ce qui concerne la gestion du personnel tenue manuellement,
elle ne donne pas satisfaction du fait qu'elle présente quelques
erreurs, plus de lourdeur et lenteur dans la prise de décisions.
D'où, le système décisionnel contribuera
à l'amélioration de la prise de décisions par les
décideurs dès qu'il est mis en place, car il mettra les
données nécessaires à la disposition des décideurs
à un temps réduit pour que les bonnes décisions soient
prises.
0.4. Méthodes et techniques 0.4.1.
Méthodes
La méthode est un ensemble des principes, des
règles et d'opérations intellectuelles permettant d'analyser les
données collectées en vue d'atteindre les
résultats.4
1 MALENGA M. ; Notes de cours d'initiation à la
Recherche Scientifique, G1 Informatique, USLKA, 2016-2017,
inédit
2 MUKADI C. ; Notes de Cours de Méthodes de Recherche
Scientifique, G2 Informatique, USLKA, 2017-2018, inédit
3 GRAWITZ M. ; Les méthodes des Sciences Sociales,
Paris, édition Dalloz, 1955, p.10
4 FREYSSINET J. ; Méthode de recherche en Sciences
Sociales, éd.Mont Chrétien, Paris, 1997, p.12
4
En outre, la méthode est un ensemble ordonné des
principes et règles permettant de comprendre la structure fonctionnelles
de l'institution et avoir une idée sur son organisation
interne.5
Pour bien mener notre étude, nous avons recourus aux
méthodes suivantes:
Méthode analytique: qui nous
a permis à faire l'analyse des faits. Cette méthode va de l'effet
aux causes. Hélas! Comme elle ne suffisait pas, nous avons fait appel
à deux autres méthodes;
La méthode historique:
celle-ci nous a permis de connaitre l'origine des événements du
fait qu'elle est une méthode descriptive, sa démarche est parfois
chronologique. Et enfin;
La méthode structurale: qui a
consisté à connaitre les relations que l'élément
entretien avec la structure. Ces principes opératoires consistent
à identifier un phénomène ou une entité sociale
à étudier et ensuite analyse ce phénomène ou
entité dans sa totalité.
0.4.2. Techniques
En vue de récolter les données
nécessaires dans Régie et correspondantes à notre
problématique, nous nous sommes référer aux techniques
ci-dessous:
? Technique d'interview: elle nous a
servi à interviewer les agents de la place avec une série des
questions plus détaillées et face auxquelles des réponses
nous ont été données et ont aidées à
l'élaboration de ce mémoire;
? Technique documentaire: celle-ci
nous a aidés plus dans la récolte de données utiles et
fiables tout en lisant les ouvrages et les archives ayant trait aux faits qui
causent le disfonctionnement dans la gestion du personnel;
? Technique d'observation: cette
dernière nous a permis quant à elle d'observer le
déroulement des activités faisant l'objet de notre
étude.
0.5. Objectif de la recherche
Notre objectif est d'apporter des solutions nouvelles pour la
modélisation et le développement d'entrepôts. Face à
la profusion d'informations hétérogènes, la conception et
le développement de systèmes décisionnels adaptés
s'avèrent primordiaux. Le cadre applicatif de notre mémoire de
fin de cycle se situe dans le domaine décisionnel notamment sur
«Le déploiement d'un système décisionnel pour le
gestion du personnel au sein de la Régie des Voies Aériennes de
Kananga».
Par ailleurs, les applications décisionnelles (et plus
généralement toutes les applications décisionnelles)
utilisent fréquemment des données temporelles. Malgré
l'intérêt que portent les décideurs aux évolutions
des données, les systèmes commerciaux actuels n'intègrent
pas l'historisation des données dans les entrepôts. En outre, peu
de travaux de recherche sur les entrepôts traitent de cet aspect. C'est
ainsi que notre étude est d'une grande importance car les
résultats obtenus à la fin pourraient aider le service du
5 GRAWITZ M. ; Op.cit, p.14
5
personnel de la RVA à adopter des nouvelles
stratégies dans la prise de décisions sur la gestion du
personnel.
Enfin, le présent mémoire apportera une solution
à la modélisation d'un système décisionnel qui
prendra en compte les problèmes difficiles à gérer et
trouver une solution voulue. C'est ainsi que dans le cadre de notre formation
spécifique entant que concepteur
de système d'information, celui-ci facilitera à
la communauté scientifique à pouvoir identifier les
problèmes similaires à celui que nous tentons de résoudre
ici pour y trouver
des solutions dans un court délai.
0.6. Délimitation de la recherche
Vu que le terrain de recherche est trop vaste, il est
impérieux que chaque chercheur limite ses recherché dans le temps
et dans l'espace.
a) Dans le temps: notre
étude va de 2020 à 2021, l'année 2020 est choisie comme
point de départ de nos recherches et 2021 comme l'année de fin de
nos investigations, ou soit une année de recherches.
b) Dans l'espace: elle porte sur la
Régie des Voies Aériennes Central précisément dans
le service Administratif, Financier et Commercial ayant en charge la gestion du
personnel.
La raison majeure qui nous a amené à faire ce
choix sur la gestion du personnel se justifie qu'entend que chercheur,
certaines observations sur la RVA nous ont prouvés qu'elle a les
difficultés dans la gestion à ce qui concerne le personnel.
0.7. Subdivision du travail
Hormis l'introduction et la conclusion générale, ce
mémoire portera sur cinq chapitres à savoir:
? Chapitre premier qui abordera les
Généralités sur le Système Décisionnel (e
Business);
? Chapitre deuxième qui portera sur les entrepôts de
données (Data Warehouse); ? Chapitre troisième qui parlera de
Datamining ;
? Chapitre quatrième qui traitera sur la
présentation du cadre d'étude et spécification de besoins
;
? Chapitre cinquième qui chutera par
l'implémentation de la Solution.
6
CHAPITRE I : GENERALITES SUR LES SYSTEMES
DECISIONNELS
I.0. Introduction
Toute entreprise qui veut atteindre des performances est
censée prendre des décisions rationnelles en se basant sur un
système décisionnel. La faillite de bon nombre d'entreprises est
due au manque d'un personnel qualifié, à une mauvaise gestion et
à une prise de décisions non adéquate.
I.1. Présentation du
décisionnelle
Avant de rentrer dans des considérations techniques,
il est bon de faire un point sur ce qu'est le décisionnel et ce que ce
terme sous-entend. Pour faire très simple, l'informatique
décisionnelle recouvre tous les moyens informatiques destinés
à améliorer la prise de décision des décideurs
d'une organisation. Cette définition pose trois nouvelles questions :
? Qu'est-ce qu'un décideur ?
? Qu'est-ce qui peut permettre d'améliorer la prise de
décision ?
? Quels sont les moyens informatiques disponibles ?
I.2. Définition d'un système
décisionnel
Les systèmes décisionnels sont un ensemble de
technologies destinées à permettre aux collaborateurs d'avoir
accès et de comprendre les données de pilotage plus rapidement,
de telle sorte qu'ils prennent des décisions meilleures et plus rapides
pour enfin atteindre les objectifs de leur organisation. Les systèmes
décisionnels dans leur version la plus complète. 6
1.2.1. La notion de décideur
Sous le modèle du taylorisme et jusque dans les
années 1890, les organisations étaient organisées de
manière pyramidale. Les décisions étaient prises au sommet
de la pyramide et les ordres étaient transmis de manière
descendante et unilatérale à tous les niveaux
opérationnels. Dans ce type d'organisation, les décideurs
étaient seulement les dirigeants de l'organisation.
Ce type d'organisation était efficace tant que le
marché était localisé et qu'il suffisait de produire pour
vendre. Depuis, nous sommes confrontés à une complexité
grandissante du marché liée :
? À la mondialisation : les concurrents sont plus
nombreux, plus innovants, mieux armés.
6 KAFUNDA KATALAYI JP,
Entrepôts des données, L2 informatique option Gestion, cours
inédit, U.K.A 2015-2016.
7
? À une modification des comportements d'achats :
l'organisation se doit d'être centrée client. En effet, les
Produits sont de plus en plus personnalisés (on parle de one-to-one).
? Au fait que le monde va de plus en plus vite : le
critère de délai de livraison ou de disponibilité de
l'information7 jours sur 7, 24h sur 24 associé à la
mondialisation et la personnalisation du besoin client, démultiplie la
complexité de l'écosystème de l'organisation.
Cette logique, facile à comprendre dans un cadre
commercial, s'applique dans tous les domaines de l'entreprise. La prise de
décision ne peut plus être centrale, celle-ci doit être
déléguée. Du fait, dans une entreprise moderne, tout cadre
devient un décideur de terrain et dispose d'une autonomie relative.
C'est cette explosion du nombre de décideurs qui pose un gros
problème à :
? L'informatique, qui se voit démultiplier le nombre de
demandes de rapports et d'extraction de données.
? La direction, qui a besoin d'outils pour manager ses
décideurs : de la cohérence est nécessaire afin que les
décisions prises à tous les niveaux de l'entreprise, le soient en
accord avec la stratégie d'entreprise.
1.2.1.1. Les facteurs d'amélioration de la
prise de décision
Généralement, on présente les trois facteurs
de prise de décision comme étant :
o La connaissance et l'analyse du passé ;
o La représentation du présent ;
o L'anticipation du futur.
Les informations permettant d'appréhender ces facteurs
peuvent être de deux natures différentes :
a) Les informations quantitatives : ce
sont toutes les données chiffrées telles que les montants,
quantités, pourcentages, délais...
b) Les informations qualitatives :
ce sont toutes les informations non quantifiables telles qu'un
commentaire accompagnant un rapport, des mécontentements, un sentiment,
une directive, une nouvelle procédure...
Ces facteurs n'ont pas le même sens suivant le type de
décideur. Leurs horizons fonctionnels et temporels sont trop
différents pour être traités de manière uniforme.
Les décideurs stratégiques ont besoin d'une vision à
360° de leur organisation. S'ils ont besoin d'une évaluation
régulière de leur politique, ils travaillent surtout sur
l'anticipation de l'avenir. Ils ont besoin de projections chiffrées
internes et externes à l'organisation (données quantitatives),
mais aussi de beaucoup de données qualitatives remontant du terrain :
commentaires, comptes rendus. La conviction repose sur des chiffres, mais aussi
sur
8
l'appréhension et la compréhension d'un contexte
et d'un climat interne ou externe à l'organisation.
Les décideurs tactiques sont souvent les plus grands
demandeurs d'outils décisionnels, car ils sont comprimés entre
des décideurs stratégiques, qui leur demandent des
évaluations de leur politique, et des décideurs de terrain,
parfois très nombreux, qu'il faut cadrer et suivre. Ces décideurs
tactiques ont besoin d'une parfaite compréhension du passé,
travaillent peu avec le présent, mais se doivent de travailler avec des
prévisions pour recadrer leur politique. Les données
chiffrées sont bien évidemment essentielles, encore faut-il que
les différents systèmes s'accordent entre eux. Les
décideurs opérationnels travaillent surtout avec le
présent : il leur faut des données opérationnelles brutes
instantanées. L'analyse du passé relève surtout d'un suivi
opérationnel pour vérifier l'adéquation avec les
objectifs. L'anticipation de l'avenir relève de la fourniture de
données opérationnelles en amont du service.
1.2.1.2. L'informatique
décisionnelle
L'informatique décisionnelle couvre toutes les
solutions informatisées pour améliorer la prise de
décision des décideurs dans l'organisation. Dans ses
débuts, l'informatique décisionnelle s'est contentée tout
d'abord de dupliquer les bases de données des systèmes de
gestion, afin d'isoler les requêtes d'analyse de données des
requêtes opérationnelles. Les requêtes d'analyse
étant souvent très lourdes, l'objectif était surtout de
préserver les performances des systèmes opérationnels.
Ensuite cette base de données dédiée aux requêtes et
à l'analyse a progressivement muté et s'est organisée.
Partant du constat qu'il est difficile de croiser des
données contenues dans des bases de données distinctes, le plus
simple a été de regrouper ces données éparses. Le
concept de la base unique pour centraliser les données de l'entreprise
est plus que jamais d'actualité. Il s'agit du concept d'entrepôt
de données (ou Data Ware house). S'il est plus simple d'analyser ces
données une fois qu'elles sont dans l'entrepôt de données,
il n'en reste pas moins qu'il faut tout de même remplir l'entrepôt
de données l'extraction et le croisement des données des
différents systèmes opérationnels puis le chargement dans
l'entrepôt de données, ont fait émerger des outils
dédiés à cette tâche, avec des concepts
métiers qui leur sont propres : les outils d'ETL (Extract Transform
Load).
Si au début, les requêtes d'analyses portaient
sur une base relationnelle (dites OLTP pour On Line Transaction Processing), le
concept de base multidimensionnelle (dites OLAP pour On Line Analytical
Processing) s'est démocratisé fin des années 90. Ce
concept de bases de données offrait des performances très
largement supérieures aux bases OLTP pour répondre à des
requêtes d'analyse. Ces bases OLAP se sont alors couplées
avantageusement avec l'utilisation de l'entrepôt de données. En
effet, elles offraient à la fois un environnement plus performant, mais
permettaient également aux utilisateurs finaux de
bénéficier d'une interface simplifiée d'accès aux
données, beaucoup plus intuitive qu'une base de données OLTP. On
parle alors de méta-modèle.
9
L'ensemble des moyens informatiques et techniques
destiné à améliorer la prise de décision est
appelé système décisionnel ou encore Système
Informatique d'Aide à la Décision (SIAD).
I.3. Historique des systèmes
décisionnels
La prise de décision est un problème essentiel
qui préoccupe les gestionnaires des entreprises. Cette prise de
décision passe par la modélisation de différents
problèmes qu'ils rencontrent dans la gestion d'où la
nécessité d'un modèle basé sur l'arbre de
décision.
De nos jours pour qu'une entreprise puisse bien marcher, elle
doit avoir besoin d'outils d'aide à la décision. Ces outils
permettront alors aux dirigeants de bien prendre des décisions. Ces
décisions concernent tous les services de cette entreprise. Le
système décisionnel englobe tous les services de l'entreprise
ainsi que leurs informations.
Les systèmes décisionnels travaillent comme des
systèmes opérationnels sur de gros volumes de données.
La décision concerne tous les départements de
l'entreprise : finances, ressources humaines, ventes, et la direction
générale. Les applications utiles dans le processus de prise de
décision sont nombreuses, et déjà présentes dans le
système d'information des entreprises.
I.4. L'informatique décisionnelle
L'informatique décisionnelle désigne les
moyens, les outils et les méthodes qui permettent de collecter,
consolider, modéliser et restituer les données,
matérielles ou immatérielles d'une entreprise, en vue d'offrir
une aide à la décision et de permettre aux dirigeants de prendre
des stratégies pour l'entreprise et d'avoir une vue d'ensemble de
l'activité traitée au sein de l'entreprise7.
En général ce type d'applications utilise un
entrepôt de données pour stocker des données provenant de
plusieurs sources hétérogènes et fait appel à des
traitements par lots pour la collecte de ces informations.
I.5. Définition d'un système
décisionnel (Business intelligence)
Un système est un ensemble de technologies
destinées à permettre aux collaborateurs d'avoir accès et
de comprendre les données de pilotage rapidement, de telle sorte qu'ils
prennent une décision meilleure a temps, résultant d'un processus
comportant le choix conscient entre plusieurs solutions en vue d'atteindre un
objectif précis.
7 P.F. Drucker, « Managing in a Time of Great Change
(The Post-Capitalist Executive) », Penguin 1995.
8 G.A. Gorry et M.S. Scott-Morton, « A framework for
management information systems », Sloane Management Review 1971,
p.15.
10
Un système décisionnel permet de répondre
aux questions suivantes :
y' Que s'est-il passé ? (tableau de bord)
;
y' Pourquoi cela s'est-il passé ?
(analyse) ;
y' Que va-t-il se passé ?
(prédiction) ;
y' Que se passe-t-il en ce moment ? (aide
opérationnelle) ;
y' Que devrait- il se passer ou que faire ?
(prise de décision ou entrepôt actif).
I.5.1 Architecture de systèmes
décisionnels8
L'architecture générale d'un système
décisionnel se décompose en trois processus : extraction et
intégration, organisation et interrogation.
Le processus d'extraction et intégration, situé
les sources de données et l'entrepôt est responsable de
l'identification des données dans les diverses sources internes et
externes dans l'extraction de l'information et de la préparation et de
la transformation (nettoyage, filtrage, etc..) des données à
l'intérieur de l'entrepôt, nous trouvons le processus
d'organisation. Il est responsable de la structuration des données par
rapport à leur niveau de granularité (agrégats).
Différents outils permettent de réaliser
l'analyse des données, pour les différents utilisateurs de
l'entreprise.
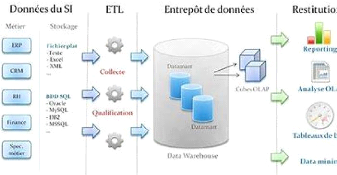
Figure 1 : Architecture Générale
d'un système décisionnel
Les sources de données sont nombreuses, variées,
distribuées et autonomes. Elles peuvent être internes (bases de
production) ou externes (Internet, bases des partenaires) à
l'entreprise.
11
L'entrepôt de données est le lieu de stockage
centralisé des informations utiles pour les décideurs. Il met en
commun les données provenant des différentes sources et conserve
leurs évolutions.
Les magasins de données sont des extraits de
l'entrepôt orientés sujet. Les données sont
organisées de manière adéquate pour permettre des analyses
rapides à des fins de prise de décision.
Les outils d'analyse permettent de manipuler les
données suivant des axes d'analyses. L'information est visualisée
au travers d'interfaces interactives et fonctionnelles dédiées
à des décideurs souvent non informaticiens (directeurs, chefs de
services,...).
I.6. Les différents éléments
constitutifs du système décisionnel I.6.1 Les sources de
données :
Les sources de données sont souvent diverses et
variées et le but est de trouver des outils et en fin de les extraire,
de les nettoyer, de les transformer et de les mettre dans l'entrepôt de
données. Ces sources de données peuvent être de fichiers de
type Excel, des bases de données opérationnelles d'une entreprise
ou fichiers plats.
I.6.2 L'entrepôt de données
:
Il est le coeur du système décisionnel et
demande une analyse profonde de la part de maitre d'ouvrage.
La conception d'un data warehouse diffère de la
conception d'une base de données relationnelles.
En effet, alors que les bases de données relationnelles
tendant le plus souvent à être normalisées, les bases des
données multidimensionnelles, elles sont normalisées en
respectant le modèle en étoile ou en flocon.9
I.6.3. Le service OLAP ou serveur
d'analyse
Le serveur OLAP est opposé à OLTP et a pour but
d'organisé les données à analyser par domaine ou par
thème et d'en ressortir des résultats pertinents pour le
décideur. Les résultats sont obtenus par différents
algorithmes de datamining (fouille de données) du serveur d'analyse. Ces
résultats peuvent amener l'organisation à prendre de très
bonnes décisions en vue d'améliorer le rendement de leurs
entreprises.
9 Bertino E., Ferrari E., Guerrini G., Merlo I., "Extending
the ODMG Object Model with Composite Objects", OOPSLA'98, Vancouver
(Canada), 1998, p.56
12
I.7. Les fonctionnalités d'un système
décisionnel
Les besoins des utilisateurs peuvent être regroupés
en quatre catégories : Simuler, analyser les données,
réduire des états de gestion, suivre et contrôler.
1°) Simuler
? Gestion de modèles de calcul (calculs automatiques
d'ensemble de données complexe en fonction de paramètre par
l'utilisateur et de règles de gestion)
Exemple d'utilisation :
élaboration de business plan ; ? Elaboration collaborative
;
EX : l'élaboration
budgétaire.
2°) Analyse de données
Fonctionnalité OLAP (établissement d'analyse
dynamique multidimensionnelle avec possibilité de trié, filtrer,
zoomer a l'intérieure de données) ;
EX : chiffre d'affaire.
Fonctionnalités avancées de datamining, ensemble
des techniques statistiques sophistiquées permettant de faire apparaitre
des corrélations, des tendances et des prévisions.
3°) Produire des Etat de
gestion
Fonctionnalités de reporting raquetteurs permettant de
produire de façon simple et rapide, des tableaux de données
incorporant des calculs plus ou moins sophistiquées.
4°) 4°) Suivre et contrôler
Elaboration de tableau de bord produit et diffusion
automatiquement à fréquence régulière de tableaux
de bord regroupent des données hétérogènes.
EX : production de tableaux de bord
graphique à destination de responsables opérationnels·
Emission d'alerte génération conditionnelle de
message sur différents supports (email, sms,...) plus ou moins complexes
en fonction de la configuration de données.
Nous avons constaté que l'ensemble de ces
fonctionnalités sont rarement mise en place dans une entreprise.
Les mises en oeuvre sont en outre souvent réalisées
par domaine fonctionnel(les ventes, achats,...). Par ailleurs, il n'existe pas
de produit couvrent l'ensemble de ces fonctionnalités.
13
Chaque progiciel en fonction de son origine et du
positionnement que souhaite lui donner son éditeur est plus au moins
avancé sur l'un ou l'autre thème.
Il est donc crucial de déterminer
précisément ses besoins présent et future, ainsi que les
contraintes liées à son organisation ou à son
activité avant de choisir une solution.
I.8. Les apports des systèmes
décisionnels
Dans beaucoup de nos entreprises ; il est difficile
d'expliquer aux dirigeants que l'on doit parfois dépenser beaucoup
d'argent pour analyser et manipuler des données existant dans le
système d'information de l'entreprise10.
Les apports de systèmes décisionnel sont aussi
défais réels. Ils peuvent être classés en deux
catégories.
? L'amélioration de l'efficacité de la
communication et de la distribution des informations de pilotage ;
? L'amélioration du pilotage des entreprises
résultant de meilleures décisions à prendre plus
rapidement ;
Si le premier point est aisément compréhensible,
présente peu de risque de mise en oeuvre et pose peu de problème
d'évaluation ce n'est clairement pas en revanche une source de gains
significative. Il sera difficile le plus souvent de justifier les couts d'un
projet sur cette seule promesse.
La seconde catégorie a nettement plus de potentiel de
gains. Mais il faut bien reconnaitre que le risque de ne pas atteindre les
objectifs initiaux sont réels sans parler d'énormes
difficultés d'évaluation des bénéfices
escomptés.
Les bénéfices de ce type le plus souvent
cités sont les suivants :
y' Unicité des chiffres, une seule
vérité acceptée par tous ;
y' Meilleure planification ;
y' Amélioration de la prise de
décision ;
y' Amélioration de l'efficacité
des processus ;
y' Amélioration de la satisfaction des
clients et des fournisseurs ;
y' Amélioration de la satisfaction des
employés.
10 S. Kelly, « Data Warehousing - The Route to Mass
Customization », John Wiley & Sons 1996, p.13.
14
I.9. Les Enjeux De L'informatique
Décisionnelle
De nos jours, les données applicatives métier
sont stockées dans une ou plusieurs bases de données
relationnelles ou non relationnelles. Ces données sont extraites,
transformées et chargées par un outil de type ETL.
Un entrepôt de données (data warehouse) peut
prendre la forme d'un data Mart. En règle générale, le
data warehouse globalise toutes les données applicatives de l'entreprise
tandis que les data Marts, généralement alimentés à
partir des données du data warehouse sont des sous-ensembles
d'information concernant un métier particulier de l'entreprise.
I.10. Les fonctions essentielles de l'informatique
décisionnelle
Un système d'information décisionnel assure
quatre fonctions fondamentales, à savoir : la collecte,
l'intégration, la diffusion et la présentation des
données. A ces quatre fonctions s'ajoute une fonction de contrôle
du système d'information décisionnelle lui-même,
l'administration.11
a) Collecte
La collecte est l'ensemble des taches consistant à
détecter, sélectionner, extraire et à filtrer les
données brutes issues des environnements pertinents compte tenu du
périmètre du système d'information décisionnel
(SID).
Les sources de données internes ou externes
étant souvent hétérogène tant sur le plan technique
que sur le plant sémantique, cette fonction est la plus délicate
à mettre en place dans un système décisionnel complexe.
Elle s'appuie notamment sur les outils d'ETL.
Cette alimentation utilise les données sources issues
des systèmes transactionnels de production, le plus souvent sous forme
de compte rendu, d'inventaire ou compte rendu d'opération qui est le
constat au fil du temps des opérations (achats, ventes, écriture,
comptable), le film de l'activité de l'entreprise ; compte rendu
d'inventaire ou compte rendu de stock qui est l'image photo prise a un instant
donné (à une fin de période, mois, trimestre) de
l'ensemble du stock (les clients, les contrats, les commandes). La fonction de
collecte joue également au besoin un rôle de recodage. Une
donnée représentée différemment d'une source
à une autre impose le choix d'une représentation unique pour les
futures analyses.
11 Bret F., Teste O., "Construction Graphique
d'Entrepôts et de Magasins de Données", INFORSID'99, La Garde
(France), Juin 1999.
15
b) Intégration
L'intégration consiste à concentrer les
données collectées dans un espace unifié, dont le socle
informatique essentiel est l'entrepôt.
Élément central du dispositif, il permet aux
applications décisionnelles de bénéficier d'une source
d'information commune, homogène, normalisée et fiable,
susceptible de masquer la diversité de l'origine des données.
Au passage les données sont épurées ou
transformées par un filtrage et une validation des données en vue
du maintien de la cohérence d'ensemble (les valeurs acceptées par
les filtres de la fonction de collecte mais susceptibles d'introduire des
incohérences de référentiel par rapport aux autres
données doivent être soit rejetées, soit
intégrées avec un statut spécial).
Une synchronisation (d'intégrer en même temps ou
à la même date de valeur des événements reçus
ou constatés de manière décalée ou
déphasée).
Une certification (pour rapprocher les données de
l'entrepôt des autres systèmes légaux de l'entreprise comme
la comptabilité ou les déclarations réglementaires).
C'est également dans cette fonction que sont
effectués éventuellement les calculs et les agrégations
(cumuls) communs à l'ensemble du projet. La fonction
d'intégration est généralement assurée par la
gestion de métadonnées, pour l'interopérabilité
entre toutes les ressources informatiques, des données
structurées (bases de données accédées par des
progiciels ou applications), ou des données non structurées.
c) La diffusion ou la distribution
La diffusion met les données à la disposition
des utilisateurs, selon des schémas correspondant au profil ou au
métier de chacun, sachant que l'accès direct à
l'entrepôt ne correspondrait généralement pas aux besoins
d'un décideur ou d'un analyste. L'objectif prioritaire est de segmenter
les données en contextes informationnels fortement cohérents,
simples à utiliser et correspondant à une activité
décisionnelle particulière.
Alors qu'un entrepôt de données peut
héberger de centaines ou de milliers de variables ou indicateurs, un
contexte de diffusion raisonnable n'en présente que quelques dizaines au
maximum.
Chaque contexte peut correspondre à un DataMart, bien
qu'il n'y ait pas de règles générales concernant le
stockage physique.
12 Chaudhuri S., Dayal U., "An Overview of Data
Warehousing and OLAP Technology", ACM SIGMOD Record, 26(1), 1997, p.112
16
Très souvent, un contexte de diffusion est
multidimensionnel, c'est-à-dire modélisable sous la forme d'un
hyper cube, il peut alors être mis à disposition à l'aide
d'un outil OLAP.12
Les différents contextes d'un même système
décisionnel n'ont pas tous besoin du même niveau de
détail.
De nombreux agrégats ou cumuls, n'intéressant que
certaines applications et n'ayant donc pas lieu d'être gères en
tant qu'agrégats communs par la fonction d'intégration,
relèvent donc de la diffusion.
Ces agrégats peuvent être, au choix,
stockés de manière persistante ou calculés dynamiquement
à la demande.
On peut distinguer trois questions à élucider
pour concevoir un système de reporting : À qui s'adresse le
rapport spécialisé ? (choix des indicateurs a présenter,
choix de la mise en page)
? Par quel trajet ? (circuit de diffusion type workflow pour les
personnes, circuits de transmission télécoms pour les moyens)
;
? Selon quel agenda ? (diffusion routinière ou sur
événement prédéfini).
d) Présentation
Cette quatrième fonction, la plus visible pour
l'utilisateur, régit les conditions d'accès de l'utilisateur aux
informations. Elle assure le fonctionnement du poste de travail, le
contrôle d'accès, la prise en charge des requêtes, la
visualisation des résultats sous une forme ou une autre.
Elle utilise toutes les techniques de communication possibles
comme les outils bureautiques, raquetteurs et générateurs
d'états spécialises, infrastructure web,
télécommunications mobiles, etc.
e) Administration
C'est la fonction transversale qui supervise la bonne
exécution de toutes les autres; elle pilote le processus de mise
à jour des données, la documentation sur les données et
sur les métadonnées, la sécurité, les sauvegardes,
la gestion des incidents.
17
I.11. Définition des Modèles de
Données Décisionnels
Un modèle de données s'applique
généralement à une application ou à un ensemble
d'applications dont le périmètre et la définition sont
arrêtés en amont du projet. Ceci est valable pour toute
application informatique. Mais ce principe d'applique d'une manière
particulière dans les projets décisionnels.
Consommateur de données et producteur d'informations,
un SID est nécessairement un dispositif à double face puisque
:
? Il combine des données d'origines diverses,
généralement opérationnelles ;
? Il met des données à disposition selon des
objectifs informationnels.
? Par rapport aux sources de données qui l'alimentent,
le data warehouse est sous-tendu par un modèle fédérateur
ou intégrateur. Mais ce modèle n'est pas directement
représentatif des points de vue informationnels - éventuellement
multiples et changeants des utilisateurs du SID. Or le SID ne vaut que pour les
restitutions informationnelles qu'il offre. Le véritable modèle
de données décisionnel est donc celui qui reflète la mise
à disposition ou encore la diffusion des données, et non leur
concentration.
Cette mise à disposition se conçoit par
domaines, sachant que le périmètre d'un domaine
décisionnel ne coïncide pas avec les frontières d'une
application de production.
Un domaine applicatif concerne un utilisateur ou un ensemble
cohérent d'utilisateurs, et implique un vocabulaire commun et une
manière commune d'appréhender l'information. C'est en quelque
sorte l'univers du discours.
Quelles que soient les modalités de conduite de projet
et les éventuels raccourcis qui seront pris à certaines
étapes, le Modèle Conceptuel des Données (MCD) du domaine
d'application est un passage obligé.
Les modèles dérivés du MCD (MLD et MPD)
sont ensuite élaborés en liaison étroite avec la
technique, selon une démarche fortement tributaire des produits. Quant
au MCD lui-même, rappelons que sa structure ne dépend que de la
sémantique des données et de la vue qu'en ont les utilisateurs.
L'analyste doit par conséquent résister à deux sortes
d'influences pernicieuses qui pèsent, à divers degrés, sur
tous les projets :
? les structures opérationnelles dans lesquelles le SID
puise ses données ;
? les modalités de fonctionnement des outils de gestion
et de présentation.
Les seules bases sur lesquelles il convient de s'appuyer pour
spécifier les objectifs du SID sont les vues externes des utilisateurs.
Ces vues doivent donc être collectées et intégrées
dans le modèle.
18
Un SID comporte donc en réalité au moins deux
Modèles Conceptuels de Données. L'un des deux représente
l'intégration des sources opérationnelles à partir
desquelles s'alimente le système. Il se conçoit et se normalise
selon une démarche traditionnelle de génie logiciel50, qui n'a
pas lieu d'être développée ici. L'autre, celui que nous
examinons dans ce chapitre, correspond à la structure informationnelle
destinée à supporter les requêtes des utilisateurs. C'est
le MCD de diffusion. C'est ce dernier qui représente la structure selon
laquelle l'information doit être mise à disposition ; il constitue
la spécification fonctionnelle du SID13.
La collecte des vues est une affaire de conduite de projet,
dont nous n'ignorons pas la difficulté pratique. La qualité de
cette collecte auprès des utilisateurs est cependant un facteur critique
de succès, et on ne peut pas en faire l'économie sans prendre un
gros risque.
De point de vue de la modélisation proprement dite,
l'intégration des vues n'est pas une simple opération de
juxtaposition. Elle passe par une normalisation.
Les normes d'intégration du MCD, dans un domaine
décisionnel, reposent sur les principes fondamentaux suivants :
Compte tenu de la nature consultative et non transactionnelle
des applications, la structure des vues externes se déduit directement
des requêtes des utilisateurs, et non des connexions
opérationnelles possibles entre les entités ;
A l'intérieur d'un domaine, il existe un ou plusieurs
sous-ensembles de vues liées entre elles par certains critères de
cohérence sémantique et structurelle. C'est sur l'identification
et la validation formelle de ces sous-ensembles, appelés contextes, que
repose toute la démarche de construction du MCD ;
Une requête décisionnelle a pour objet
d'établir un rapprochement non programmé entre des entités
conceptuelles plus ou moins nombreuses. De ce fait, les résultats
attendus sont systématiquement déterminés par des
associations51. La structure des vues reflète celle des associations
possibles. Chaque vue a pour élément central une association
autour de laquelle gravitent deux ou plusieurs entités, et correspond
à une représentation des informations sous forme de tableau
à deux ou plusieurs dimensions ;
La liste exhaustive des requêtes possibles n'est jamais
figée. Celle des vues qui en découlent ne l'est donc pas non
plus. La normalisation du MCD doit permettre d'anticiper et d'intégrer
automatiquement dans chaque contexte le plus grand nombre possible de «
vues probables » d'après la structure des « vues connues
» ; Entre deux entités intervenant dans une même vue, il doit
exister un et un seul chemin de navigation sémantique, et ce chemin doit
être le plus court possible.
13 Groupe EVOLUTION. F. Bret. T. Cruanees. I. Guessarian. E.
Metais. M-C. Rousset. S. Schwer. O. Teste. G. Zurfluh, Ingénerie des
systèmes d'information , édition HERMES, 2001, p.38
19
| 

