Etude prévisionnelle de la consommation nationale du gaz en Algériepar Maher GUENNOUN Université des Sciences et de la Technologie Houari Boumediene - Ingénieur d'état en Recherche Opérationnelle 2004 |

Chapitre 7APPLICATION DE LA MODELISATION MULTIVARIEESuite a líapplication de la méthodologie de Box & Jenkins sur les di§érentes séries de consommation celles-ci sont rendues stationnaires, nous pouvons donc appliquer la modéli- sation multivarié I AR. 7.1 Etude multivariee des series de consommation (O Et, DPt, O It) Dans la suite de notre étude nous considérons le vecteur M t 6 (O ESAt, DLDP SAt, LO G O It) et L t 6 (R 1t, R 2 t, R 3 t) vecteur résiduel associée a M t de matrice de variance-covariance z 7.1.1 IdentiÖcation du modèle VAR(P) A líinstar de la méthodologie de Box & Jenkins líidentifcation est une étape cruciale, pour mener a bien cette démarche on a recours aux critéres díinformations AI O, SO et le maximum de vraisemblance (LI ) pour déterminer le nombre de décalages p. A cette fn, nous avons estimé divers modéles I AR pour des ordres de retards p allant de 1 a 14. Pour chaque modéle, nous avons calculé les critéres díinformations précédemment cités. Le tableau TAB.I I.1 reporte les résultats obtenus. On constate que deux des trois critéres nous conduisent a retenir un modéle I AR(14). 106 TAB * 2 .!
Líastérisque indique líordre p a retenir. Les comparaison des modéles suivant les critéres AI O et LI nous pousse a choisir le modéle I AR(14) 7.1.2 Estimation du modèle VAR(14) a-Estimation du modèle 2 & / (! # ) avec constante Le modéle I AR(14) avec constante síécrit sous la forme suivante M t 6 # O ) # 1M tt1 ) ....... ) # p M tt14 ) L t oü # O 6 (aO , aO , aO ) représente líestimation de la consatante et # p (p 6 1, ..., 14) sont des 1 2 3 0 a1 2 3 1 1p a1p a1p a 2 p matrices carrées díordre 3 tel que # p 6 6 1 a 1 3 p les coecents cients estimés. 2 3 a a 2 p 2 p a a 2 3 3 p 3 p j (i, j 6 1, 2, 3 ) représentent 7 les ai p X Donc on doit estimer 9 paramétres pour z? et 13 2 paramétres a estimer pour # p . On e§ectue líestimation en utilisant le logiciel EVIEWS, nous obtenons le tableau qui sera présenté comme suit : Le tableau contient 3 colonnes au nombre des variables du modèle I AR. Ce tableau peut être décomposé en 3 blocs, chaque bloc est associé a une série Chaque bloc contient p 6 14 lignes La ligne i (i 6 1...14) díun bloc précis correspond a la série associée a líinstant t i. Chaque ligne contient les coecents cients au retard i (donnés en haut), ainsi que les t- statistic associées (données en bas entre crochets).
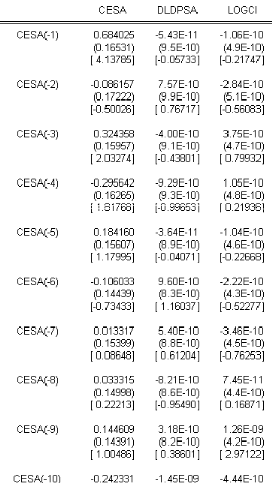
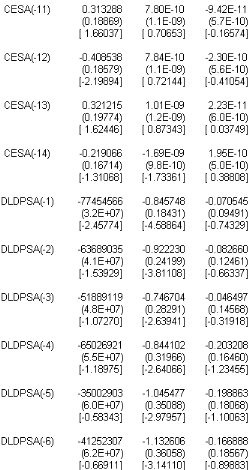
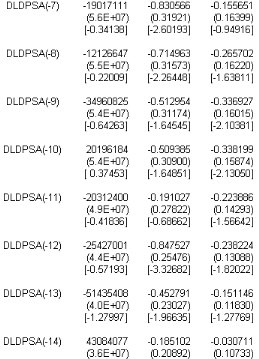
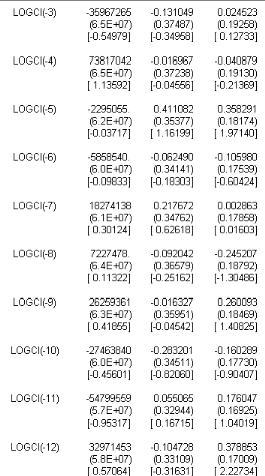
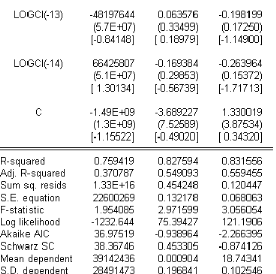
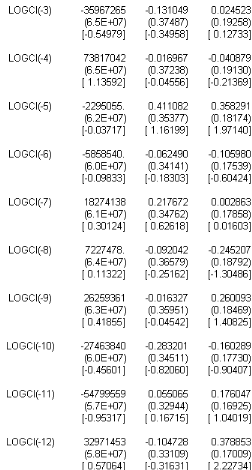
TAB.I I.2 Estimation I AR(14) avec O A la lecture du tableau TAB.I I.2 on constate que la constante est non signifcative aux seuils 1% , 5 % et 10 % puisque les t-statistic (données par les valeurs entre crochets) sont inférieures aux di§érentes valeurs critiques. De la on réestime le modèle I AR(14) sans constante. b-Estimation du modèle VAR(14) sans constante Líéquation du modèle I AR(14) sans constante síécrit : M t 6 # 1M tt1 ) ....... ) # p M tt14 ) L t Donc on doit estimer 14 matrices # p , ainsi que la matrice variance-covariance z? associée au résidu L t, nous obtenons le tableau suivant :
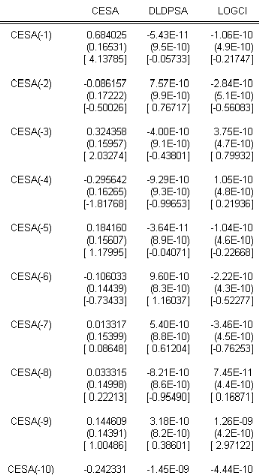
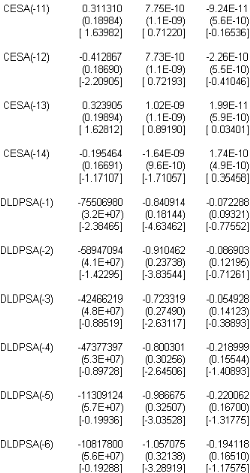
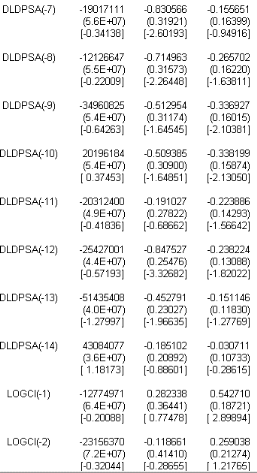
TAB.I I.3 Estimation I AR(14) sans O A partir TAB I I.3 du tableau nous obtenons líéquation suivante : 0 M t 6 6 0 .68 75 50 6980 12779471 5 .43 E 11 0 .8 4 0 .28 1.0 6E 10 0 .0 7 0 .5 4 1 7 M tt1 0 0 .08 58 8 9470 94 23 15 63 70 ) 6 7.5 7E 10 0 .91 0 .12 2.8 4E 10 0 .0 9 0 .26 0 0 .3 2 424661219 35 967265 ) 6 4E 10 0 .72 0 .13 3 .75 E 10 0 .05 0 .0 2 0 0 .3 1 65 0 26921 73 8 170 42 1 7 M tt2 1 7 M tt3 1 ) 6 9.58 E 10 0 .8 4 0 .0 2 3 .75 E 10 0 .20 0 .0 4 0 0 .18 1130 9124 2295 05 5 ) 6 4E 10 0 .99 0 .41 3 .75 E 10 0 .22 0 .3 6 7 M tt4 1 7 M tt5 0 0 .11 10 8 1780 0 58 58 5 40 ) 6 9.6E 10 1.05 70 75 0 .0 6 2.22E 10 0 .19 0 .11 0 0 .0 1 190 17111 18 27413 8 ) 6 5 .4E 10 0 .83 0 .83 3 .46E 10 0 .15 0 .00 3 1 7 M tt6 1 7 M tt7 0 0 .03 12126647 7277478 ) 6 8 .21 10 0 .71 0 .0 9 7.45 E 11 0 .26 0 .25 1 7 M tt8 0 0 .14 3 49608 25 2625 93 61 ) 6 3 .18 E 10 0 .5 2 0 .0 2 1.26E 9 0 .3 4 0 .26 1 7 M tt9 0 0 .24 20 19618 4 274638 40 ) 6 1.45 E 9 0 .5 1 0 .28 4.4E 10 0 .3 4 0 .16 1 7 M tt10 0 0 .3 1 20 3 1240 0 5 479955 9 ) 6 7.75 E 10 0 .19 0 .05 9.24E 11 0 .22 0 .18 0 0 .41 25 42700 1 5 479955 9 ) 6 7.73 E 10 0 .85 0 .11 2.26E 10 0 .24 0 .38 1 7 M tt11 1 7 M tt12 0 0 .3 2 5 143 5 408 5 485 5 771 ) 6 1.0 2E 9 0 .45 0 .05 1.99E 11 0 .15 0 .18 1 7 M tt13 0 0 .2 430 8 40 77 5 93 3 65 70 6 ) 6 1.64E 9 0 .19 0 .19 1.74E 10 0 .03 0 .26 1 7 M tt14 ) L t Bien entendu cette écriture du modèle subira un remaniement après líépreuve des tests suite a líétape de validation. Nous obtenons également la matrice de variance-covariances suivante : 0 z? 6 6 1 7
0 .13 5 0 .0 11 5 .11E ) 11 7.1.3 Validation Test sur le nombre de decalages p : Afn de valider líordre p 6 14 du modèle I AR(14), on utilise en plus des critères díinforma- tions précédents, le critère de Hannan-Quinn qui est a minimiser. Ainsi on estime un certain nombre de modèles I AR pour p allant de 1 a 14, on obtient le tableau suivant
Le résultat du test confrme líordre du décallage (p 6 14) jugé nécessaire. Test sur les residus : De la même faÁon que la méthodologie de Box & Jenkins, il convient de vérifer si les rési- dus forment un bruit blanc, une observation des corrélogrammes des résidus des trois séries síimpose.
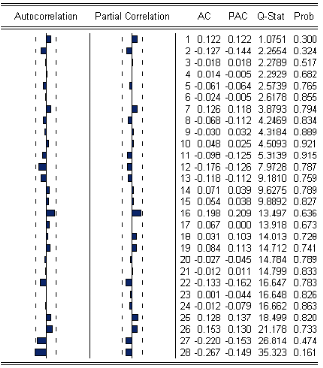
FIG.I I.4 Corrélogramme des résidus de la série O ESAt Líanalyse du corrélogramme des résidus de la série O ESAt (Fig.I I.4) montre que tous termes sont a líintérieur de líintervalle de confance, ce qui est confrmé par la Q s tat pour 0 ,05 tous les retards en particulier Q s tat 6 26.8 1 (au retard K 6 27) < x 2 (22) 6 33 .92, donc les résidus se comportent comme un bruit blanc.
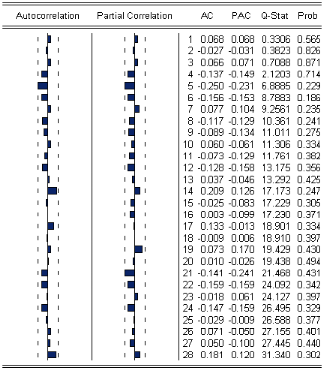
FIG.I I.5 Corrélogramme des résidus de la série DLDP SAt Líobservation du corrélogramme des résidus de la série DLDP SAt nous montre que les résidus en question forment un bruit blanc.
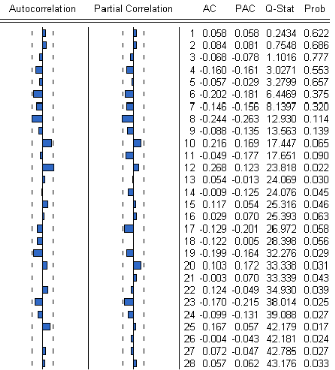
FIG.I I.6 Corrélogramme des résidus de la série LO G O It Globalement, líanalyse des trois corrélogrammes nous montre que tous les termes sont a líintérieur de líintervalle de confance de la on déduit une absence de corrélation, donc les résidus des séries une a une forment un processus bruit blanc. Etant donné que nous sommes dans líobligation díavoir un vecteur résiduel de type bruit blanc, líobservation des corrélogrammes simples ne sucents t pas, cíest ainsi quíon examinera les corrélogrammes croisés des résidus.
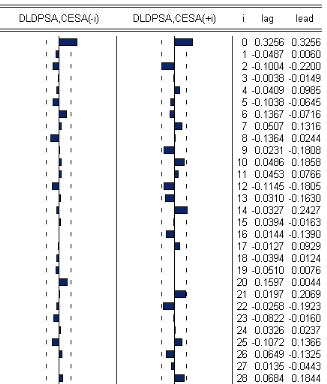
FIG.I I.7 Corrélogramme des résidus croisés entre DLDP SAt et O ESAt En observant la fgure I I.7 on remarque que tous les termes sont a líintérieur de líin- tervalle de confance ce qui traduit une absence de corrélation entre les résidus des séries DLDP SAt et O ESAt.
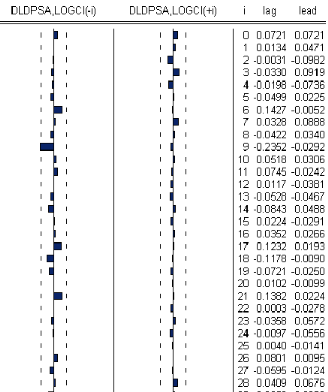
FIG.I I.8 Corrélogramme des résidus croisés entre DLDP SAt et LO G O It De la même faÁon et pour les mêmes arguments, les résidus des séries DLDP SAt et LO G O It sont non corrélées.
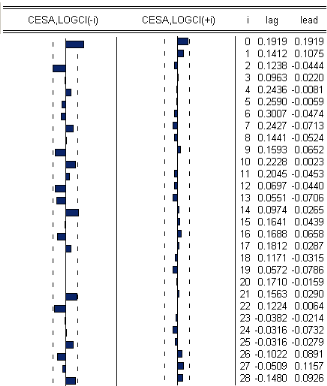
FIG.I .5 Corrélogramme des résidus croisés entre O ESAt et LO G O It A la base de líétude des corrélogrammes simples et croisés des résidus, on déduit que les résidus associés au modèle I AR(14) forment un vecteur bruit blanc. Tests sur les estimations : En tenant compte du tableau des estimations (Tab I I.3 ) et le faite quíun coecents cient est signifcativement di§érent de zéro au seuil 5 % , si la t-statistic associée est supérieure a 1.96, et en vertu des résultats des tests précédents, le modèle I AR(14) est validé et il síécrit de la faÁon suivante : 11 2 O ESAt 6 7750 6980 DLDP SAtt1 5 .43 e t I O ESAtt1 I 4e t10 I O ESAtt3 ) 7.73 e t10 O ESAtt12 ) e 1t I DLDP SAt 6 0 .8 4DLDP SAtt1 0 .91DLDP SAtt2 0 .73 DLDP SAtt3 )I 0 .8 DLDP SAtt4 0 .98 DLDP SAtt5 1.05 DLDP SAtt6 0 .83 DLDP SAtt7 0 .71DLDP SAtt8 I I 0 .85 DLDP SAtt12 0 .45 DLDP SAtt13 ) e 2 t I I LO G O It I 6 0 .3 4DLDP SA tt9 0 .3 4DLDP SA tt10 ) 1.26e t9 O ESA tt9 3 ) 0 .5 4LO G O Itt1 ) 0 .3 6LO G O Itt5 ) 0 .38 LO G O Itt12 ) e 3 t Remarque On constate que la série DLDP SAt síécrit uniquement en fonction de ses valeurs passées, ceci nous pousse a penser que líapproche multivarié níapportra en rien en terme de prévisions par rapport a líapproche univarié concernant la consommation publique. 7.1.4 Prevision Le modèle étant validé, líexpression de la prévision pour un horizon h 6 1 a partir de líinstant présent t est donnée par : 2 ODESA(1) 6 7750 698 0 DLDP SAt 5 .43 e t11O ESAt I I 4e t10 I D I O ESAtt2 ) 7.73 e t10 O ESAtt11 I DLDP SA(1) 6 0 .8 4DLDP SAt 0 .91DLDP SAtt1 0 .73 DLDP SAtt2 0 .8 DLDP SAtt 3 0 .98 DLDP SA tt4 1.05 DLDP SA tt5 I 0 .83 DLDP SAtt6 0 .71DLDP SAtt7 I I 0 .85 DLDP SAtt11 0 .45 DLDP SAtt12 I 9 I LDO G O I (1) 6 0 .3 4DLDP SAtt8 0 .3 4DLDP SAtt9 ) 1.26e t O ESAtt8 ) 0 .5 4LO G O It ) 0 .3 6LO G O Itt 4 ) 0 .38 LO G O I tt11 Pour un horizon h 6 12, on obtient : 2 D D t11 D O ESA(12) 6 7750 6980 DLDP SA(11) 5 .43 e I O ESA(11) I 4e t I 10 ODESA(9) ) 7.73 e t10 O ESAtt1 I I DLDDP SA(12) 6 0 .8 4DLDDP SA(11) 0 .91DLDDP SA(10 ) 0 .73 DLDDP SA(9) )I 0 .8 DLDDP SA(8 ) 0 .98 DLDDP SA(7) 1.05 DLDDP SA(6) I 0 .83 DLDDP SA(5 ) 0 .71DLDDP SA(4) I I 0 .85 DLDP SAt 0 .45 DLDP SAtt1 I I LDO G O I (12) 6 0 .3 4DLDDP SA(3 ) 0 .3 4DLDDP SA(2) ) 1.26e t9 ODESA(3 ) 3I ) 0 .5 4LDO G O I (11) ) 0 .3 6LDO G O I (7) ) 0 .38 LO G O It Pour h > 12 on obtient le système díéquations suivant : 2 D D t11 D O ESA(h) 6 7750 6980 DLDP SA(h 1) 5 .43 e I O ESA(h 1) I 4e t I 10 ODESA(h 3 ) ) 7.73 e t10 O ESAt+ ht11 I I DLDDP SA(h) 6 0 .8 4DLDDP SA(h 1) 0 .91DLDDP SA(h 2) I)I 0 .73 DLDDP SA(h 3 ) 0 .8 DLDDP SA(h 4) 0 .98 DLDDP SA(h 5 ) 1.05 DLDDP SA(h 6) 0 .83 DLDDP SA(h 7) 0 .71DLDDP SA(h 8 ) I I 0 .85 DLDP SAt+ ht12 0 .45 DLDP SAt+ ht13 I I LDO G O I (12) 6 0 .3 4DLDDP SA(h 9) 0 .3 4DLDDP SA(h 8 ) I I t9 D D D ) 1.26e I O ESA(h 9) ) 0 .5 4LO G O I (h 1) ) 0 .3 6LO G O I (h 5 ) 3 ) 0 .38 LO G O It+ ht12 Les graphes des prévisions des trois séries de consommation ainsi que les tableaux asso- ciés sont données ci-dessous :
FIG.I I.9 Graphe des prévisions de la série DPt Les prévisions de la consommation publique pour un horizon díune année sont comme suit :
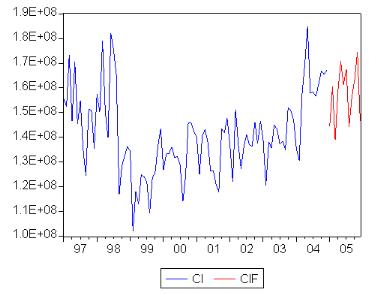
FIG.I I.10 Graphe des prévisions de la série O It Les prévisions de la consommation industrielle sont contenues dans le tableau suivant :
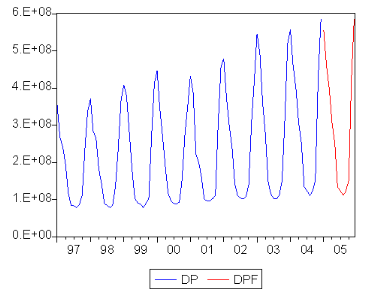
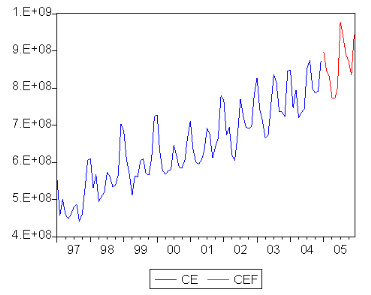
FIG.I I.11 Graphe des prévisions de la série O Et Les prévisions de la consommation des centrales électriques a partir de janvier 20 05 jusquíau mois de Décembre de la même année sont résumées dans le tableau suivant :
7.2 ConclusionLíétude multivariée achevée, nous pouvons tirer les enseignements suivants : 1 Le modèle I AR(14) a été retenu pour modéliser le vecteur composé des trois séries de consommation. 2 On constate que líordre du décallage retenu (p 6 14) pour la modélisation I AR(14) est assez élevé ceci nous amène a estimer 13 2 paramètres. 3 Le modèle I AR(14) validé, il a été exploité pour e§ectuer des prévisions, en examinant les équations liées aux prévisions et plus précisément celle de la série relative a la consom- mation publique, nous constatons que celle ci síécrit uniquement en fonction de ses valeurs passées. 4 Toujours concernant les prévisions, et ce qui concerne la consommation des centrales élec- triques, nous remarquons que durant le premier semestre de líannée 20 05 une consommation assez élevée est prévue, ce qui est visible sur le graphe des prévisions associé (Fig I I.11). A cette étape bien précise nous sommes en possession de deux groupes de résultats associés a deux approches di§érentes pour un objectif commun a savoir e§ectuer des prévisions. Pour choisir les meilleurs résultats une comparaison sera entreprise par la suite pour ne pas perdre de vue le but de notre étude. Comparaison La comparaison des résultats prévisionnels obtenues par les deux méthodes a savoir la métho- dologie de Box & Jenkins et la modélisation I AR est basée sur la somme des carrées résidus (RM SE) entre les observations prévues et les réalisations des séries de consommation. Les prévisions díune méthode sont jugées plus fables son RM SE est la plus faible par rap- port a celle de líautre méthode. h Le calcul du RM SE est donné par la formule suivante : RM SE(e ) 6 D 1 z (Xt XX t) Remarque n tl 1 Faute de données réelles pour le premier semestre de líannée 20 05 , le RM SE a été calculé a partir des valeurs prévues pour líannée 20 0 4 obtenues a partir du modèle réestimé pour la circonstance. Le tableau suivant donne le RM SE calculée a partir de la modélisation I AR pour la consom- mation industrielle :
Pour ce qui est de la méthodologie de Box & Jenkins, nous obtenons les résultats suivants :
Ainsi, la comparaison entre les deux méthodes utilisées síe§ectuera a partir du tableau sui- vant :
Remarque : RM 8E1 et RM 8E2 sont associées a la méthodologie de Box & Jenkins et la modèlisation I AR respectivement. Pour la consommation publique RM 8E1 > RM 8E2. Pour la consommation industrielle RM 8E1 < RM 8E2. Pour la consommation des centrales électriques RM 8E1 < RM 8E2. Nous concluons que les prévisions obtenues par la modélisation I AR sont plus fables que celles obtenues par la méthodologie de Box & Jenkins pour la consommation industrielle et celle des centrales électriques, par contre pour la consommation publique la méthodologie de Box & Jenkins donne de meilleurs résultats. |
|