CHAPITRE 3 : METHODOLOGIE DE L'ETUDE
Section 1 : Saisonnalité et Stationnarité
A- Saisonnalité.
Dans le cas d'une série affectée d'un mouvement
saisonnier, il convient de retirer cette propriété
préalablement à tout traitement statistique.
Traitant de données mensuelles, les
corrélogrammes doivent laisser apparaître un pic remarquable pour
k = 12, qui est précisément égal à la
périodicité des données, et ses multiples afin que le
comportement saisonnier soit admis.
B- Stationnarité
Avant le traitement d une série chronologique, il convient
de déterminer si elle stationnaire ou pas.
1- Définition de la
Stationnarité d'un processus
La stationnarité d'un processus peut être
définie au sens strict ou au sens faible du terme.
a- Stationnarité Stricte (stationnarité de
premier ordre)
Un processus est dit strictement stationnaire si V ti ET avec
t1 < t2 <...< tn et h ET avec ti +h E T, Vi, i = 1, ..., n,
les deux suites suivantes (xt1, ... xtn) et
(xt1+h, ..., xtn+h) ont la même loi de
probabilité. Cela signifie que V (x1, ... xn), V (t1,..., tn) et V h
:
P [xt1< x1 , .. .,xtn < xn ] = P
[xt1+h< x1, ..., xtn+h < xn].
En d'autres termes, un processus est strictement stationnaire
si pour tout changement de l'origine du temps, ses moments
caractéristiques (espérance mathématique, variance et
covariance) sont invariants c 'est-à-dire indépendants du
temps.
Cette hypothèse est très contraignante. Aussi,
en pratique quand on raisonne sur une série on a recours à une
conception plus large de la stationnarité et empiriquement
vérifiable : la stationnarité faible.
b- Stationnarité faible (stationnarité de
second ordre)
Le processus Xt, t ET est dit faiblement stationnaire
si les 3 propriétés suivantes sont remplies :
E[Xt] = E[Xt +k] = m (constante) V tE T.
L'espérance mathématique du processus existe et est invariant
dans le temps.
V[Xt] = a2 (constante) V tE T. La variance
espérée (car on raisonne sur des probabilités) est stable
dans le temps.
Cov[Xt, Xt+O] = yx[O] V tE T, VO E T. La
covariance (en fait l' autocovariance car elle est calculée entre les
variables du processus et les mêmes variables décalées
d'une ou plusieurs périodes) est indépendante du temps.
yx[O] représente la fonction d'autocovariance du
processus.
En résumé, Xt faiblement stationnaire si
:
|
E[Xt] = E[Xt +k] = m (constante) V tET V[Xt] = 2 (constante) V
tET
Cov[Xt, Xt+O] = yx[O] V tET, VO ET
|
Une série chronologique est stationnaire si elle est la
réalisation d'un processus stationnaire.
La détection de la stationnarité d'une
série s'effectue généralement à l'aide des tests de
stationnarité. Mais elle peut s'appréhender en première
approximation par l'allure de la fonction d'autocorrélation et sa
représentation graphique : le corrélogramme.
> La fonction d'autocorrélation
Cette fonction d'autocorrélation donne une indication
sur le degré de liaison c'est-à-dire la dépendance
temporelle qui existe entre les différentes valeurs de la série.
Sur un processus stochastique, elle se note :
Pk
Pk est la valeur théorique pour tout k du coefficient
d'autocorrélation du processus stochastique. Mais en économie,
nous ne disposons pas du processus mais plutôt d'une série. On
calculera donc les coefficients d'autocorrélation à partir de la
série. Par conséquent, on obtiendra une fonction
d'autocorrélation sur la chronique qui sera une estimation de la
fonction d'autocorrélation théorique (du processus
lui-même).
Pour chaque décalage k introduit entre les observations de
la série, cette fonction d' autocorrélation estimée sera
:
Covariance entre t
Variance de la
série Y t ö0
p à
k =
-k) calculée
et (t
sur la
série Y t
=
ök

1
ö V()
Y
0 e
p
à 0 =
= =
ö V()
Y
0 e
Pour une série stationnaire, pour tout décalage
k>0, les coefficients d'autocorrélation estimés sur la
série doivent être compris entre -1 et 1. Cela signifie que la
série se comporte comme un phénomène d'oubli en ce sens
qu'une certaine valeur de la série peut être
influencée par une valeur précédente mais cette influence
décroît en fonction du temps c'est-à-dire au fur et
à mesure que cette valeur est éloignée dans le temps. Mais
dans la pratique, il convient de faire les tests de stationnarité.
2- Tests de stationnarité: tests de
Dickey-Fuller Augmentés
Il existe différents tests de vérification de la
stationnarité d'une variable chronologique mais notre étude
retient ceux de Dickey-Fuller Augmentés qui sont les plus
utilisés. Ces tests permettent de mettre en évidence le
caractère stationnaire ou non d'une chronique par la
détermination d'une tendance déterministe ou stochastique mais
aussi la bonne manière de la stationnariser. Pour ce faire, deux types
de processus sont distingués :
- les processus TS (Trend Stationary) qui représentent
une non-stationnarité de type déterministe ;
- les processus DS (Differency Stationary) pour les processus
non stationnaires aléatoires.
a- Les processus TS
Selon la terminologie proposée par Nelson et Plosser
(1982), (xt, t ? Z)
est un processus TS s'il peut s'écrire sous la forme :
xt = f(t) + zt
où f(t) est une fonction du temps et zt est
un processus stochastique stationnaire. Dans ce cas, le processus xt
s'écrit comme la somme d'une fonction déterministe temps et d'une
composante stochastique stationnaire, éventuellement de type ARMA.
Dès lors, il est évident que le processus ne satisfait plus la
définition de la stationnarité du second ordre. En effet, on
montre immédiatement que :
E( xt) = f(t) + z
où z = E(zt), dépend du temps, ce qui
viole l'une des conditions de la définition d'un processus
stationnaire.
b- Les processus DS
Un processus non stationnaire (xt, t ? Z) est un
processus DS (Differency Stationary) d'ordre d, où d désigne
l'ordre d'intégration, si le processus filtré défini par
(1 - L)d xt, où Li xt =
xt-i, est stationnaire. On dit aussi que (xt, t ? Z) est
un processus intégré d'ordre d, noté I(d).
c- Stratégie de tests de Dickey-Fuller
augmentés (ADF)
Les tests d'ADF sont fondés sur l'estimation par les
moindres carrés ordinaires des trois modèles suivants:
p
|
(4) Axt =
xt-1 + ~= 19 j x
t
D -
j
|
j
|
+ JI + It
+ Et
|
p
(5) Axt = xt-1 + ~=
9+ JI + Et
jx t j
D-
j 1
+ Et
j
p
(6) Axt = xt-1 +
~= 19jx t D-
j
Le principe général de la
stratégie de test est le suivant : il s'agit de partir du modèle
le plus général, d'appliquer le test de racine unitaire en
utilisant les seuils correspondants à ce modèle, puis, de
vérifier par un test approprié que le modèle retenu
était le »bon». En effet, si le modèle n'était
pas le »bon», les seuils utilisés pour le test de racine
unitaire ne sont pas valables. On risque alors de commettre une erreur de
diagnostic quant à la stationnarité de la série. Il
convient dans ce cas de recommencer le test de racine unitaire dans un autre
modèle, plus contraint. Et ainsi de suite jusqu'à trouver le
»bon» modèle, les»bons» seuils et bien entendu les
»bons» résultats.
Le déroulement de la stratégie de test est
reporté sur la figure suivante. On commence par tester la racine
unitaire à partir du modèle le plus général,
à savoir le modèle 4. On compare la réalisation de la
statistique de Student t~=0 aux seuils tabulés par Dickey et Fuller ou
McKinnon pour le modèle 4. Si la réalisation de t~=0
est supérieure au seuil, on accepte l'hypothèse nulle de
nonstationnarité. Une fois que le diagnostic est établi, on
cherche à vérifier si la spécification du modèle 4,
incluant une constante et un trend, était une spécification
compatible avec les données. On teste alors la nullité du
coefficient 3 de la tendance. De deux choses l'une :
· Soit on a rejeté au préalable
l'hypothèse de racine unitaire ; dans ce cas, on
teste la nullité de 3 par un simple test de Student
avec des seuils standards (test symétrique, donc seuil de 1.96 à
5%). Si l'on rejette l'hypothèse 3 = 0, cela signifie que le
modèle 4 est le »bon» modèle pour tester la racine
unitaire, puisque la présence d'une tendance n'est pas rejetée.
Dans ce cas, on conclut que la racine unitaire est rejetée, la
série est TS, du fait de la présence de la tendance. En revanche,
si l'on accepte l'hypothèse 3 = 0, le modèle n'est pas
adapté puisque la présence d'une tendance est rejetée. On
doit refaire le test de racine unitaire à partir du modèle 5, qui
ne comprend qu'une constante.
· Soit, au contraire, on avait au préalable,
accepté l'hypothèse de racine unitaire,
et dans ce cas, on doit construire un test de Fischer de
l'hypothèse jointe p = 0 et 3 = 0. On teste ainsi la nullité de
la tendance, conditionnellement à la présence d'une racine
unitaire:
H4 0 : (p; 3; p) = (p; 0; 0) contre H4
1.
La statistique de ce test se construit de façon standard
par la relation :
F4 = ((SCR4,c - SCR4) /2)/(SCR44 / (N - p - 3))
où SCR4,c est la somme des carrés des
résidus du modèle 4 contraint sous H4 0 :
+ p. + 8t
j
p
~xt = ~= 1è
j x t
Ä -
j
et SCR4 est la somme des carrés des résidus du
modèle 4 non contraint ; N et p étant respectivement le nombre
d'observations pris en compte et le nombre de retards. Si la réalisation
de F4 est supérieure à la valeur lue dans la table de Dickey et
Fuller à un seuil a%, on rejette l'hypothèse H4 0.
Dans ce cas, le modèle 4 est le »bon» modèle, le taux
de croissance est TS :
p
~xt = ~= è + p. + 3t +
8t
jxtj Ä -
j 1
En revanche, si l'on accepte H4 0, le coefficient
de la tendance est nul, le modèle 4 n'est pas le »bon»
modèle, on doit donc effectuer à nouveau le test de
non-stationnarité dans le modèle 5. Si l'on a accepté la
nullité du coefficient 3 de la tendance, on doit alors effectuer
à nouveau les tests de non-stationnarité à partir cette
fois-ci du modèle 5 incluant uniquement une constante. On compare alors
la réalisation de la statistique de Student t~=0 aux seuils
tabulés par Dickey et Fuller ou McKinnon pour le modèle 5. Si la
réalisation de t~=0 est supérieure au seuil on accepte
l'hypothèse nulle de non-stationnarité. Une fois que le
diagnostic est établi, on cherche à vérifier si la
spécification du modèle 5, incluant une constante, est une
spécification compatible avec les données. On teste alors la
nullité de la constante p.. De deux choses l'une :
· Soit on a rejeté au préalable
l'hypothèse de racine unitaire, dans ce cas on teste
la nullité de p. par un simple test de Student avec des
seuils standard (test symétrique, donc seuil de 1.96 à 5%). Si
l'on rejette l'hypothèse p. = 0, cela signifie que le modèle 5
est le »bon» modèle pour tester la racine unitaire, puisque la
présence d'une constante n'est pas rejetée. Dans ce cas, on
conclut que la racine unitaire est rejetée, la série est
stationnaire I(0) + p.. En revanche, si l'on accepte l'hypothèse p. = 0,
le modèle 5 n'est pas adapté puisque la présence
d'une constante est rejetée. On doit refaire le test de
racine unitaire à partir du modèle 6,qui ne comprend ni constante
ni trend.
· Soit, au contraire, on avait au préalable
accepté l'hypothèse de racine unitaire,
et dans ce cas, on doit construire un test de Fischer de
l'hypothèse jointe p = 0 et p. = 0. On teste ainsi la nullité de
la constante, conditionnellement à la présence d'une racine
unitaire:
H50 : (p.; p) = (0;0) contre H51 .
La statistique de ce test se construit de façon standard
par la relation :
F5 = ((SCR5,c - SCR5) /2)/(SCR5/ (N - p - 2))
où SCR5,c est la somme des carrés des
résidus du modèle 5 contraint sous H50 et SCR5 est la
somme des carrés des résidus du modèle5 non contraint . Si
la réalisation de F5 est supérieure à la valeur lue dans
la table de Dickey et Fuller à un seuil a, on rejette l'hypothèse
H50 au seuil a%. Dans ce cas, le modèle 5 est le
»bon» modèle et la série xt possède
une racine unitaire. En revanche, si l'on accepte H50, le
coefficient de la constante est nul, le modèle 5 n'est pas le
»bon» modèle, on doit donc effectuer à nouveau le test
de non-stationnarité dans le modèle 6. Enfin, si l'on a
accepté la nullité du coefficient p. de la constante, on doit
alors effectuer à nouveau les tests de non-stationnarité à
partir cette fois-ci du modèle 6 sans constante ni trend. On compare
alors la réalisation de la statistique de Student tp=0 aux
seuils tabulés par Dickey et Fuller ou McKinnon pour le modèle 6.
Si la réalisation de tp=0 est supérieure au seuil, on
accepte l'hypothèse nulle de non-stationnarité. Dans ce cas la
série xt possède une racine unitaire. Si
l'hypothèse nulle est rejetée, la série est stationnaire
I(0) de moyenne nulle.
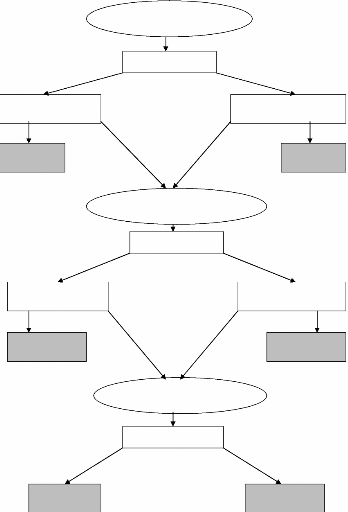
(A)Test H0 : (p = 0
Estimation du model avec
tendance et constante
Rejet de H0 Acceptation de H0 Rejet de H0
xt est un
processus TS
(B1) Test H0 : 1 = 0
Rejet de H0 Acceptation de H0
Estimation du model sans
tendance mais avec constante
Acceptation de H0
(B0) Test
H0 : (U, 1, (p) = (U, 0, 0)
Axt est un processus TS
Acceptation de H0
xt est un proces- sus: I(0) + U
(D1)Test H0 : U = 0
Rejet de H0 Acceptation de H0
Estimation du model sans tendance et sans constante
(C) Test H0 : (p = 0
(D0) Test
H0 : (U, (p) = (0, 0)
xt possède une
racine unitaire
Rejet de H0 Acceptation de H0
xt est un
processus: I(0)
xt possède une
racine unitaire
(E) Test H0 : (p = 0
Schéma de la stratégie de test de racine
unitaire
Section 2 : Processus ARMA
La forme générale d'un processus ARMA (Auto
Regressive Moving Average) est :
A(L)xt = p. + B(L)Et
où Et est un `'bruit blanc'', avec A(L) et B(L)
des polynômes de retards défini respectivement par A(L) = 1 - a1L
- a2L2 - . . . - apLp et
B(L) = 1 + 131L + 132 L2 + . . . + 13q Lq
,
a1, ..., ap et 131,..., 13q étant
des réels de même que p..
La procédure de modélisation de Box et Jenkins
(1976) comporte les étapes suivantes : dessaisonalisation et
stationnarisation, identification, estimation puis validation. IL ne nous que
les trois dernières ; les deux premières ayant été
déjà développées.
Identification
La méthode d'identification de Box et Jenkins (1976)
est fondée sur la comparaison des moments empiriques de la série
considérée aux moments théoriques associés aux
différentes représentations potentielles. On se concentre
généralement sur les moments d'ordre deux résumés
par la fonction d'autocorrélation et la fonction
d'autocorrélation partielle. On peut aussi utiliser des critères
de choix de modèle, couramment appelés critères
d'information.
1- Identification à partir des
corrélogrammes simple et partiel
a- Les processus AR(p)
Un processus stationnaire (xt, t ? Z) satisfait une
représentation auto
régressive d'ordre p, notée AR(p), si et seulement
si :
A(L)xt = p. + Et
A(L) étant un polynôme de retards de p ème
degré et Et i.i.d. ( 0, ~2E ).
Le corrélogramme simple d'un processus AR(p) est
caractérisé par une décroissance géométrique
de ses termes de type :
Pk = Pk
Le corrélogramme partiel a ses seuls p premiers termes
significativement différents de zéro.
b- Les processus MA(q) Un processus
(xt, t ? Z) satisfait une représentation MA d'ordre q,
notée
MA(q), si et seulement si :
xt = m + B(L)Et
B(L) étant un polynôme de retards de q ème
et Et i.i.d.(0, ~2E ).
Le corrélogramme simple d'un processus MA(q) a ses
seuls q premiers termes significativement différents de zéro
pendant que le corrélogramme partiel est caractérisé par
une décroissance géométrique de ses termes.
c- Les processus ARMA(p,q)
Plusieurs processus aléatoires stationnaires ne peuvent
être modélisés uniquement comme des MA purs ou des AR purs
car leurs caractéristiques sont souvent des combinaisons des deux types
de processus.
Il s'agit là d'un modèle ARMA d'ordre p, q
noté ARMA (p, q). Pour ce type de processus, les corrélogrammes
simples et partiels sont, par voie de conséquence, un mélange des
corrélogrammes des processus AR et MA purs. Le corrélogramme
partiel d'un ARMA(p,q) est le même que celui d'un MA à partir de
l'ordre p + 1 tandis que son corrélogramme simple est le
même que celui d'un AR à partir de l'ordre q + 1.
2- Identification sur la base des
critères de AKAIKE et SCHWARZ
On peut aussi utiliser les critères de choix de
modèle, habituellement appelés critères d'information. Les
plus couramment utilisés sont :
- le critère de Akaïke : AIC
- et le critère de Schwarz : SC =
|
= ln(SCRh) + 2
h
n n
ln() +
SCRhln
hn
n n
|
Avec h = p + q, SCRh la somme des carrés des pour le
modèle estimé et n le nombre d'observations disponibles.
On choisit alors le modèle pour lequel ces deux
critères sont minimums.
B- Validation
Il s'agit notamment de vérifier que les résidus
du modèle ARMA estimés, vérifient les
propriétés requises, à savoir qu'ils suivent un processus
de bruit blanc. Il convient également de tester la
significativité des paramètres et de s'assurer que le coefficient
de détermination est proche de l'unité.
1- Tests sur les paramètres
On teste la significativité des retards du modèle
ARMA par des tests de Student.
2- Test de bruit blanc (test de Ljung et Box)
Le test de Ljung et Box permet d'identifier les processus de
bruit blanc. Il s'agit de vérifier :
Cov(xt, xt-k) = 0 ou encore Pk = 0 ? k.
Les hypothèses sont les suivantes :
H0 : P1 = P2 = . . . = Pk = 0
H1 : Il existe au moins un Pk différent de zéro.
La statistique utilisée est le Q de Ljung et Box
défini par :
h
~= -nk
Q = n(n+2)
ñà2 k
k 1
avec h : le nombre de retards, n : le nombre d'observations,
ñàk le coefficient
d'auto corrélation empirique d'ordre k.
Q suit une loi de Chi-Deux à h degrés de
liberté. Si X2calculé < X2tabulé,
on
accepte H0 : les coefficients d'auto corrélation sont
significativement égaux à zéro.

MODEL ISATION ETANAL ~SE DES CHOCS
PARTIE II :
| 

