II.4. L'INTERVIEW
L'interview a permis de recueillir les informations relatives
aux éléments considérés par la population comme
cause de déclanchement du ravinement par un questionnaire
préalablement établit (voir en annexe), la date probable de
début du ravinement dans la zone, et aussi pour recueillir, aux
prés des responsables municipaux l'information relative à
l'ampleur des dégâts sur l'habitat.
II.5. PRISES DES POINTS /DONNEES GPS
.
Les données GPS ont été utilisées
pour la cartographie tandis que les données issues de l'enquête de
terrain nous ont permis de constituer une base des données à
l'aide du logiciel Excel 2007. L'estimation du modèle d'analyse a
été faite grâce au logiciel Eviews 3.0.
Par ailleurs nous nous sommes servis du SIG pour
cartographier les données recueillies avec le GPS.
II.6. LE SYSTHEME D'INFORMATION GEOGRAPHIQUE
A permis de cartographier tous les ravins
étudiés à l'aide du logiciel Arc-gis 9.2. Avant de
visualiser les données GPS recueillies sur le terrain, le logiciel
Pathfinder a permis la correction des données GPS. Ces données
enregistrées sur le DGPS sont sous forme SSF, pour la lecture dans un
SIG, Pathfinder corrige ces données en changeant le format d'affichage
c'est à partir de ce format que l'exportation peut se faire. Les
données corrigées ont été exportées par le
logiciel Arc gis 9.2 ; ce logiciel nous a permis de numériser les
différents ravins et les différentes rues des cinq quartiers de
notre site d'étude.
Ce système nous a permis de présenter les
informations localisées géographiquement, c'est à dire les
ravins étudiés en vue de calculer le volume de terres
érodées, de cartographier les ravins et de numériser tous
les documents cités précédemment.
II.7. L'OUTIL STATISTIQUE (EVIEWS)
Logiciel Eviews est un logiciel
d'économétrie, offrant toutes les fonctions nécessaires
en analyse de statistiques multi variées.
Ce logiciel permet de faire la régression du
modèle d'analyse conçu en fonction de l'objectif de
l'étude et des variables disponibles. En effet, pour rappel Eviews est
un logiciel économique spécialisé beaucoup plus en
économétrie. Nous avons conçu un modèle, où
il y a une variable dépendante (dimension du ravin) et deux variables
indépendantes (âge du ravin et couverture végétale
du ravin). Les commandes utilisées avec Evieuws se résument comme
suit :
LS DIM C AGE COUV ; LS (pour désigner la
méthode d'estimation : Moindres Carrées Ordinaires), suivi
de la variable dépendante (DIM) suivi de la constante ou de
l'ordonnée à l'origine, suivi des variables
indépendantes ;
Notons que Eviews reconnaît la lettre
« c » comme étant la constante, c'est la raison pour
laquelle losqu'on estime un modèle avec constante, on met la lettre
« c » ;
Les statistiques descriptives ont été obtenues
toujours avec Eviews par la commande : View, suivie de descriptive stat,
suivi de la commande common simple.
La première phase de cette analyse consiste à
montrer quels sont les variables qui déterminent la dimension d'un
ravin. Pour ce faire nous avons estimé plusieurs modèles
économétriques multiples et présentons dans ce travail un
seul qui nous a paru plus plausible.
Avant de passer à l'étape d'estimation, il est
toujours nécessaire de faire l'analyse exploratoire des données
c'est-à-dire l'analyse descriptive des données. Les variables
ci-après ont été retenues : le nombre des têtes
de ravins, l'âge de ravins, la longueur, la largeur, la profondeur, et le
volume de ravins.
Tête =nombre des têtes du ravin.
Age=l'âge du ravin
Long=longueur du ravin
Larg=largeur du ravin
Prof=profondeur du ravin
Vol=volume du ravin
Nous partons de l'hypothèse que la dimension d'un ravin
dépend de son âge et de sa couverture végétale.
Ceci nous amène à estimer un modèle
linéaire multiple. Estimer un modèle revient à calculer
les valeurs des paramètres à partir d'un échantillon. Un
modèle étant une expression mathématique d'une
réalité, il en existe de plusieurs types. Par ce travail nous
avons retenu un modèle linéaire multiple.
Il est à noter qu'un modèle est dit
linéaire multiple lorsqu' il comprend une variable dépendante
et plus d'une variable indépendante de degré un et le coefficient
de pondération qui relie la variable dépendante à la
Variable indépendante s'appelle paramètre (C(1), C(2), C(3)).
Mais dans le cadre de ce travail le modèle peut se formaliser comme
suit :
DIM=f(AGE,COUV) avec DIM : dimension du ravin
AGE : âge du
ravin
COUV : couverture
végétale du ravin
Le modèle peut alors s'écrire : DIM = C(1)
+ C(2)*AGE + C(3)*COUV
Après estimation du modèle, la première
étape de l'interprétation consiste à faire une analyse
empirique paramétrique (valider les paramètres estimés).
La validation des paramètres se fait par deux méthodes : la
première consiste à comparer les probabilités
calculées à la probabilité critique ou au seuil de
signification de 5% (0,05). Nous partons des hypothèses :
H0 : Pc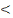 P 0,05, P 0,05,
H1 : Pc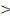 P 0,05 P 0,05
Condition
H1 c'est l'hypothèse de recherche, ici
elle exprime la significativité statistique du paramètre
estimé, tan disque H0 traduit le contraire de
l'hypothèse de recherche, donc pour notre cas c'est la non
significativité statistique du paramètre estimé. Ainsi, si
Pc est inférieure à P0, 05, on rejette l'hypothèse nulle,
cela signifie que le paramètre estimé est statistiquement
significatif. Par contre, si Pc est supérieure à P0,05, on
accepte l'hypothèse nulle, et l'acceptation de H0 veut dire
que le paramètre estimé est statistiquement significatif.
La deuxième méthode que nous permet d'examiner
la significativité statistique des paramètres estimés est
la méthode ou la règle de Pousse. Selon cette règle,
lorsque la statistique de t de student d'un paramètre estimé
dépasse « 2 », cela signifie que ce paramètre
est statistiquement significatif. si le t de student du paramètre
estimé est en dessous de deux, le paramètre n'est pas
significatif.
Après la validation des paramètres, on
fait ce qu'on appelle l'analyse empirique non paramètrique. Ici on
vérifie la significativité globale du modèle à
partir du coefficient de détermination(R2). Si le
R2 dépasse 50%, on dit que le modèle estimé est
globalement bon. En effet, le R2 traduit le pouvoir explicatif de
tous les variables indépendantes incluses dans le modèle sur la
variable dépendante. Son pourcentage exprime le degré auquel les
différentes variables explicatives considérées dans le
modèle influencent la variable dépendante.
En dehors du R2, on regarde aussi le coefficient de
Fisher. Ce coefficient traduit la fiabilité globale du modèle
estimé. La statistique de Ficher est attachée à sa
probabilité. Ainsi, si la probabilité liée à la
statistique de Ficher est inférieure à la probabilité
critique de 0,05, on conclue que le modèle estimé est globalement
fiable. Dans le cas contraire, il ne sera pas globalement fiable.
Outre les deux méthodes statistiques
évoquées ci-dessus, on examine aussi la statistique de Durbin
Watson pour détecter la présence d'autocorrélation des
erreurs. Si Durbin watson se situe autour de deux, on conclu qu'il y a absence
d'autocorrélation des erreurs. On détecte la présence
d'autocorrélation des erreurs lorsque Durbin Watson s'écart de
deux.
Une autre analyse très importante dans
l'inférence empirique non paramétrique, est la somme de
carrées des résidus. La normale est que cette somme doit
être minimisée pour que la variance des résidus pour toutes
les observations soit constante, c'est l'hypothèse de l'absence
d'hétéroscédasticité. Lorsque cette somme est
très élevée, on suppose que la variance des erreurs pour
toutes les observations n'est pas constante (donc absence
d'homoscédasticité).
N.B : Une remarque importante s'impose dès
maintenant à savoir : dans beaucoup des cas un ravin peut avoir des
ramifications qu'on appelle tête.
| 
