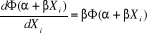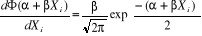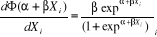Certification de gestion durable des forêts et efficacité socioéconomique des entreprises du secteur dans le bassin du Congo. Cas du Cameroun( Télécharger le fichier original )par Jonas NGOUHOUO POUFOUN Université de Yaoundé 2 - Diplôme d'études approfondies/ Master II en sciences économiques 2008 |

I.1.2 : Les modèles usuels pour les variables qualitatives.Les modèles à choix binaires (dichotomiques) sont utilisés dans les secteurs divers dès lors que la variable dépendante peut prendre deux modalités. Dans ce paragraphe, il sera question de passer en revue les trois types de modèles usuels, l'interprétation des coefficients, pour enfin choisir le modèle adéquat pour notre estimation. Hypothèse : On considère un échantillon de N individus indicés i = 1, ..,N. Pour chaque individu, on observe si un certain événement s'est réalisé et l'on note Yi la variable codée associée à un événement. On pose, i = [1, N] :
L'inadéquation du modèle linéaire conduit à modéliser, non pas la variable dépendante elle-même, mais la probabilité qu'elle prenne la valeur 1 ou 0 (qu'un événement survienne ou pas). On remarque ici le choix du codage (0, 1) qui est traditionnellement retenu pour les modèles dichotomiques. En effet, celui-ci permet définir la probabilité de survenue de l'événement comme l'espérance de la variable codée Yi, puisque :
La variable Y peut matérialiser le niveau de bien être. Et donc pour un individu i de notre échantillon, il peut être élevé ou faible. Elle peut plutôt matérialiser les équipements de sécurité sociale qui peuvent être disponibles ou non disponibles pour chaque individu. Dans un modèle à choix binaire, l'objectif est
la modélisation d'une alternative (Y=1 ou Y=0) et donc à estimer
la probabilité associée à l'événement Y=1.
Etant donné un vecteur X de variables explicatives, le risque d'avoir
des probabilités calculées négatives est
écarté en modélisant la relation X - Y sous la forme :
Où Ö (.) est une application dont les réalisations s'inscrivent obligatoirement entre 0 et 1. Quoiqu'il existe, virtuellement, une multitude fonctions répondant à ce critère, le choix de Ö (.) se porte le plus souvent sur trois types de fonctions : o la fonction de répartition de la loi normale o la fonction de répartition de la loi logistique o La fonction de répartition de la loi normale tronquée. · Cas n° 1 : modèle PROBIT Ö(.) correspond à la fonction de répartition de l'erreur åi. Elle est définie comme il suit :
Il s'agit d'une loi normale centrée réduite Cette hypothèse de travail donne naissance au modèle PROBIT · Cas n° 2 : modèle LOGIT Ö (.) correspond à la fonction de répartition de la loi logistique On suppose ici que
Les propriétés de cette équation sont les suivantes :
Cette hypothèse de travail donne naissance au modèle LOGIT. · Cas n° 3 : modèle à Variable Dépendante Limitée ou TOBIT Ces modèles sont intermédiaires aux modèles à probabilité linéaires et non linéaires. Ici, la variable dépendante est continue mais n'est pas observée sur tout l'intervalle. TOBIN (1958) a qualifié ce modèle de modèle à variables dépendantes limitées. En effet, ces modèles dérivent des modèles à variables qualitatives, dans le sens où l'on doit modéliser la probabilité que la variable dépendante appartienne à l'intervalle pour lequel elle est observable. La structure de base ce type est représentée par le modèle TOBIT. Les modèles TOBIT se réfèrent de façon générale à des modèles de régressions dans lesquels le domaine de définition de la variable dépendante est contraint sous une forme ou une autre. La variable dépendante était ainsi assujettie à une contrainte de non négativité. Ce terme a été introduit par GOLDBERGER (1964) en raison des similarités avec le modèle PROBIT. Les modèles TOBIT sont des modèles de régression censurées (censored regression models) ou modèle de régression tronquée (truncated regression models). Cette terminologie plus précise permet en effet d'introduire la distinction entre des échantillons tronqués et des échantillons censurés : 1. un modèle de régression est dit tronqué lorsque toutes les observations des variables explicatives et de la variable dépendante figurant en dehors d'un certain intervalle sont totalement perdues. 2. un modèle de régression est dit censuré lorsque l'on dispose au moins des observations des variables explicatives sur l'ensemble de l'échantillon. Nous ne développerons pas ce modèle car nos régressions ne seront ni tronquées, ni censurées. Quelque soit le type de modèle utilisé des trois évoquées précédemment, l'interprétation des coefficients est plus délicate que dans les modèles linéaires. Ce dernier cas est estimé par la méthode des Moindres Carrées Ordinaires pour lesquelles les coefficients ont les interprétations économiques immédiates en termes de propensions marginales, ou de pentes. Par contre, l'interprétation des coefficients des modèles dits à probabilités non linéaires (PROBIT, TOBIT, LOGIT, ...) ne sont pas directement interprétables. Seuls les signes des coefficients indiquent si la variable agit positivement ou alors négativement sur la probabilité pi. Cependant, il est possible de calculer les effets marginaux afin de connaître l'effet de la modification d'une variable explicative sur la probabilité pi. Puisque, Soit, dans le cas PROBIT : Dans le cas LOGIT : Alors qu'avec le modèle linéaire l'effet marginal de X sur P est constant quel que soit X (et égal à â), cet effet marginal de X sur P varie désormais en fonction du point à partir duquel il est apprécié. La significativité des coefficients est appréciée à l'aide des ratios appelés (z-statistique) car la distribution des rapports du coefficient sur son écart-type ne suit pas une loi de Student comme dans le modèle linéaire général, mais une loi normale. Cette statistique s'interprète de manière classique à partir des probabilités critiques et permet la tenue de tous les tests de significativité concernant les coefficients. Historiquement, les modèles LOGIT ont été introduits comme des approximations de modèles PROBIT permettant des calculs plus simples. Dès lors, il n'existe que peu de différences entre ces deux modèles dichotomiques. Ceci s'explique par la proximité des familles de lois logistiques et normales. Les deux fonctions de répartition sont en effet sensiblement proches. Par conséquent, les modèles PROBIT et LOGIT donnent généralement des résultats relativement similaires. De nombreuses études ont d'ailleurs été consacrées à ce sujet comme par exemple celle de MORIMUNE (1979)67(*) ou de DAVIDSON et MACKINNON (1984). La conclusion de ces travaux est que, la question du choix entre les deux modèles ne présente que peu d'importance. Toutefois, il convient d'être prudent quand à la comparaison directe des deux modèles. En conclusion de ces travaux, AMEMYA (1981) relève que les résultats des modèles PROBIT et LOGIT sont généralement similaires que ce soit en termes de probabilité ou en termes d'estimation des coefficients â si l'on tient compte des problèmes de normalisation. Bien que cette proximité soit valide, il existe certaines différences entre les modèles PROBIT et LOGIT, comme le souligne d'ailleurs AMEMYA. Pour cela, il faut être prudent dans l'utilisation des approximations pour comparer les modèles PROBIT et LOGIT de toujours raisonner en termes de probabilités pi = F(Xiâ) et non en termes d'estimation des paramètres â pour comparer ces résultats. Nous évoquerons ici deux principales différences : 1. la loi logistique tend à attribuer aux événements »extrêmes» une probabilité plus forte que la distribution normale ; 2. le modèle LOGIT facilite l'interprétation des paramètres â associés aux variables explicatives Xi Economiquement, cela implique que le choix d'une fonction logistique (modèle LOGIT) suppose une plus grande probabilité attribuée aux événements »extrêmes», comparativement au choix d'une loi normale (modèle PROBIT). Pour notre étude, notre choix portera sur le modèle PROBIT * 67 Morimune K. (1979),»Comparisons of Normal and Logistic Models in the Bivariate Dichotomous Analysis», Econometrica 47, 957-975. |
|


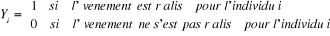

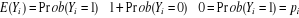
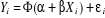
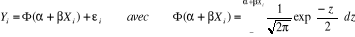
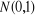 .
.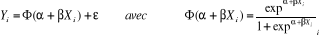
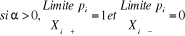
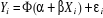 l'effet marginal d'une variation de Xi sur la
probabilité Pi que Yi soit égal à 1
est :
l'effet marginal d'une variation de Xi sur la
probabilité Pi que Yi soit égal à 1
est :