Table de Matières
Remerciement 2
Avant- Propos 3
Résumé 4
Summary 5
Table de Matières 6
Introduction 9
I. Les entrepôts de données pour l'aide à la
décision 9
II. Problématique et objectif du mémoire 11
2.1. Conception d'un système pour le décisionnel
12
2.2. Gestion de l'évolution des entrepôts 12
2.3. Difficulté à spécifier et formaliser
les exigences décisionnelles 12
2.4. Objectif du mémoire 13
Chapitre I : Etat de l'art sur les systèmes
décisionnels 14
1. Entrepôts de données multidimensionnelles et
aspects temporels 14
1.1. Entrepôts de données 14
1.2. Architecture d'un entrepôt de données 14
1.3. Différence entre Entrepôts et les bases de
données 15
1.4. Modélisation multidimensionnelle 16
1.4.1. Niveaux Conceptuels 17
1.4.1.1. Tables de faits 17
1.4.1.2. Tables de Dimensions 18
1.4.1.3. Hiérarchie 18
1.4.1.4. Granularité 19
Ndioba Syll et Abdrahmane Aw Page7
1.4.2. Niveaux Logiques 20
1.4.2.1. Schéma en étoile 20
1.4.2.2. Schéma en flocon de neige 21
1.4.2.3. Schéma en Constellation 22
1.5. Serveurs OLAP (On-Line Analytical Processing) 23
1.5.1. ROLAP (Relational OLAP) 24
1.5.2. MOLAP (Multidimensional OLAP) 24
1.5.3. HOLAP (Hybrid OLAP) 25
Chapitre II : Conception et mise en place de notre entrepôt
de données 26
2.1. Le cycle de développement 26
2.2. Choix du modèle multidimensionnel 27
2.3. Processus ETL 28
2.3.1. Définition d'un outil ETL 28
2.3.2. La phase d'alimentation 29
2.4. Etude de quelques solutions décisionnelles 29
2.4.1. Spago BI 30
2.4.2. Pentaho 30
2.4.3. Birt 31
2.4.4. Talend Master Management (TMDM) 31
2.4.5. Le serveur Mondrian 32
2.4.6. JPivot 32
2.5. Choix de la solution 32
2.5.1. Présentation de Pentaho 32
2.5.2 Prise en main de Pentaho 35
Ndioba Syll et Abdrahmane Aw Page8
Chapitre lll: Implémentation 37
3.1. Intégration des données avec Pentaho Data
Integration 37
3.2. Alimentation Datamart 44
3.3. Création de rapport avec Pentaho Report Designer
51
3.4. Analyse des données avec la plateforme BI Lite
cube 55
Conclusion 58
ANNEXE 59
Liste des Figures 59
Biographie 61
Ndioba Syll et Abdrahmane Aw Page9
Introduction
Au moment où les technologies se développent, la
concurrence internationale accrue, les méthodes de communication de plus
en plus perfectionnées, les besoins sociaux de plus en plus nombreux,
les structures des entreprises, les hommes (mentalités) doivent
être capables de s'adapter aux changements. Une nouvelle approche est
nécessaire : l'analyse systémique.
Dans les systèmes d'information modernes depuis
quelques années, un troisième objectif a été
défini : il s'agit de produire une information de connaissance, une
information intelligente (qui n'était pas stockée au paravent
mais qui est le produit du brassage, du croisement de plusieurs informations
d'origines diverses) qui permet la prise de décision, on parle alors du
système d'information décisionnel ou analytique. Ainsi les
entrepôts de données intègrent les informations en
provenance de différentes sources, souvent réparties et
hétérogènes et qui ont pour objectif de fournir une vue
globale de l'information aux analystes et aux décideurs. Ces
applications d'aide à la décision sont de type OLAP (On-line
Analytical Processing ou Analyse en ligne). La construction et la mise en
oeuvre d'un entrepôt de données représentent une
tâche complexe qui se compose de plusieurs étapes. La
première consiste à l'analyse des sources de données et
à l'identification des besoins des utilisateurs. La deuxième
correspond à l'organisation des données à
l'intérieur de l'entrepôt. Finalement, la troisième
consiste à établir divers outils d'interrogation (d'analyse, de
fouille de données ou d'interrogation). Chaque étape
présente des problématiques spécifiques. Ainsi, par
exemple, lors de la première étape, la difficulté
principale consiste en l'intégration des données, de
manière à qu'elles soient de qualité pour leur stockage.
Pour l'organisation, ils existent plusieurs problèmes comme : la
sélection des vues à matérialiser, le
rafraîchissement de l'entrepôt, la gestion de l'ensemble de
données (courantes et historiées), entre autres. En ce qui
concerne le processus d'interrogation, nous avons besoin des outils performants
et conviviaux pour l'accès et l'analyse de l'information.
Notre travail se focalise principalement sur les deux
dernières étapes, ainsi, pour le processus d'organisation, nous
proposons la définition d'un modèle multidimensionnel.
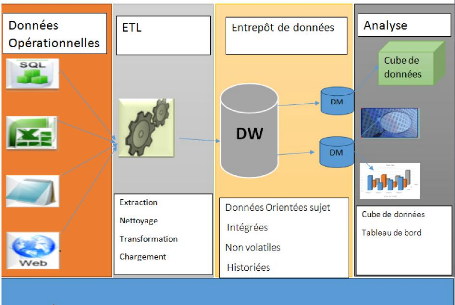
I. Les entrepôts de données pour l'aide
à la décision
L'entrepôt de données, ou le DataWarehouse, est
une collection de données orientées sujet,
intégrées, non volatiles et historiées, organisées
pour le support d'un processus d'aide à la décision. Il
centralise toutes les données de l'entreprise. Il est structuré
pour contenir une
Ndioba Syll et Abdrahmane Aw Page10
volumétrie importante de données, les volumes de
données à collecter étant de plus en plus
conséquents et ne cessant d'augmenter. Ces données sont issues de
sources hétérogènes. Elles peuvent être internes,
bases de données, fichiers, services Web, etc, externes (clients,
fournisseurs, etc.) ou encore non informatisées (lettres, notes de
service, compte-rendu de réunions, etc.).
Nous détaillons ces caractéristiques :
Orientées sujet : Les données des
entrepôts sont organisées par sujet plutôt que par
application. Par exemple, une chaine de magasins d'alimentation organise les
données de son entrepôt par rapport aux ventes qui ont
été réalisées par produit et par magasin, au cours
d'un certain temps.
Intégrées : Les données provenant des
différentes sources doivent être intégrées, avant
leur stockage dans l'entrepôt de données. L'intégration
(mise en correspondance des formats).
Non volatiles : A la différence des données
opérationnelles, celles de l'entrepôt sont permanentes et ne
peuvent pas être modifiées. Le rafraichissement de
l'entrepôt, consiste à ajouter de nouvelles données, sans
modifier ou perdre celles qui existent.
Historiées: La prise en compte de l'évolution
des données est essentielle pour la prise de décision qui,
utilise des techniques de prédiction en s'appuyant sur les
évolutions passées pour prévoir les évolutions
futures.
La construction d'un entrepôt revient à faire
correspondre les besoins des utilisateurs avec la réalité des
informations disponibles. Nous devons d'abord identifier et analyser les
sources de données, ce qui nous permet de proposer les mécanismes
adaptés selon les caractéristiques des informations. Ensuite,
nous devons organiser l'ensemble de données à l'intérieur
de l'entrepôt. Pour cela, nous devons d'abord structurer ces informations
en considérant leur granularité. Ceci nous permet d'aboutir
à la conception d'un schéma multidimensionnel qui permet de
répondre aux besoins des utilisateurs
Ndioba Syll et Abdrahmane Aw Page11
Figure 1 : Architecture générale d'un
système décisionnel
| 

