Génération dynamique d'interfaces spécifiques dans l'exploitation des processus d'ingénierie logicielle en apprentissage( Télécharger le fichier original )par Claude Albert MOGHOMAYE Ecole Polytechnique Yaoundé CAMEROUN - DEA en Sciences de l'Ingénieur option Génie Logiciel 2004 |

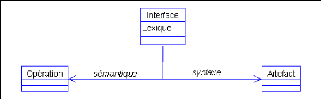
4.2 Une specification semi-formelle des interfacesLa spécification semi-formelle se résume au modèle présenté à la figure 4.1. Ce modèle présente les trois (03) niveaux de conception d'une interface. Une interface munie de son lexique est en relation avec une opération qui constitue sa sCmantique ; également en relation
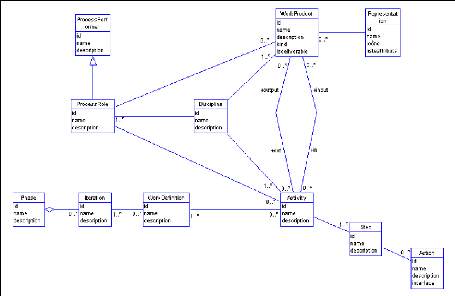
FIG. 4.1 Trois (03) niveaux de conception d'une interface avec un artefact qui constitue sa syntaxe. Les attributs des classes présentées sont les mêmes que ceux des entités correspondantes dans le modèle de ROSE. Ces différentes spécifications vont nous permettre d'élaborer le modèle de ROSE du paragraphe suivant en complément du modèle semi-formel. 4.3 Un modèle de ROSEmodelrose Le triplet (a, o, i) ? A × O × I tel que i = f(a, o) sera qualifié d'objet réutilisable sur les processus de développement dans la dimension GUI constituant ici le Process GUI. Les éléments du processus selon le métamodèle SPEM' seront dénommés objets réutilisables sur les processus dans la dimension BF dont l'ensemble constitue le Process State. Enfin, les règles sur les artefacts du processus se verront attribuer le qualificatif objet réutilisable sur les processus dans la dimension BR dont l'ensemble constitue le Process Engine. Les dénominations Process GUI, Process State et Process Engine ont été empruntées à Bob Balzer qui s'était intéressé aux perspectives futures de la technologie du Génie Logiciel en 1999 dans [Balzer 1999]. Nous définissons la base de connaissances d'un processus de développement (BCPD) comme un entrepôt d'objets réutilisables (Object Repository for Software Engineering). Dans la suite, nous allons tour à tour présenter le modèle de ROSE sous forme de DTD essentiellement (ce choix est justiflé par le fait que nos connaissances factuelles, les règles et les interfaces sont stocicées sous forme de fichier XML) que nous définissons suivant chacune des dimensions d'une base de connaissances. 'Object Management Group, http :// www.omg.org 4.3.1 Le modèle de ROSE du Process StateLe modèle de ROSE du Process State s'appuie sur une spécialisation de la structure du processus suivant le métamodèle SPEM [OMG 2002]. En effet, nous avons utilisé la spécification SPEM et y avons ajouté des éléments afin de faciliter l'exploitation, conformément à nos objectifs pour constituer le modèle de ROSE. Nous avons donc obtenu après une étude,
FIG. 4.2 - Le schéma UML du Process State le schéma de la figure 4.2, et la DTD qui suit a été obtenue en transformant ce modèle UML et en faisant les hypothèses et choix suivants : Pendant la transformation, pour une association père fils, le père contient des identifiants vers l'ensemble de ses fils et chaque fils a une référence sur son père. ~ Bien qu'un WorkProduct puisse avoir plusieurs
représentations, pour simplifier, nous - Pendant la transformation, pour une association many-to-many, il faut : soit faire un choix et privilégier un sens de l'association, soit créer un ensemble de références de chaque côté de l'association sur le côté opposé. - On privilégie l'association de Iteration vers WorkDefinition; pour obtenir l'autre sens, on pourra parcourir la liste des itérations. -- On privilégie l'association de WorkDefinition vers Activity; pour obtenir l'autre sens, on pourra parcourir la liste des WorkDefinition. -- On crée deux (02) nouveaux éléments Entree et Sortie au niveau de Activity qui représentent les WorkProducts en entrée et en sortie d'une activité. On crée également deux (02) nouveaux éléments Entrant et Sortant au niveau de WorkProduct qui représentent les activités qui prennent en entrée (resp. en sortie) ce WorkProduct pour des besoins de navigation. Description devrait normalement se transformer en attribut de chacun des éléments, mais nous avons choisi de le garder comme un élément par souci d'ergonomie de nos fichiers résultants. En effet, compte tenu du fait que ce champ peut avoir une longueur de caractères assez importante, le prendre comme attribut rendrait le document touffu. -- ProcessPerformer est implémenté comme un attribut de ProcessRole. En effet, on peut retrouver la description de ProcessPerformer à partir de celle des ProcessRole correspondants. De plus, sur le schéma, le ProcessPerformer n'est en relation qu'avec le ProcessRole, d'oii ce choix. <!D O CTYPE ProcessState PUBLIC "*. dtd"> <!-- Description --> <!ELEMENT Description (#PCDATA)> <!-- Phase --> <!ELEMENT Phase (Description,Iteration *)> <!ATTLIST Phase id NMTOKEN #REQUIRED> <!ATTLIST Phase name CDATA #REQUIRED> <!ATTLIST Phase visibility NMTOKEN #REQUIRED> <!-- Iteration --> <!ELEMENT Iteration (Description, WorkDefinition*)> <!ATTLIST Iteration id NMTOKEN #REQUIRED> <!ATTLIST Iteration name CDATA #REQUIRED> <!ATTLIST Iteration visibility NMTOKEN #REQUIRED> <!-- WorkDefinition --> <!ELEMENT WorkDefinition (decription,Activity*)> <!ATTLIST WorkDefinition id NMTOKEN #REQUIRED> <!ATTLIST WorkDefinition name CDATA #REQUIRED> <!ATTLIST WorkDefinition visibility NMTOKEN #REQUIRED> <!-- Activity --> <!ELEMENT Activity (Description,ProcessRole,Entree,Sortie,Step -i-)> <!ATTLIST Activity id NMTOKEN #REQUIRED> <!ATTLIST Activity name CDATA #REQUIRED> <!ATTLIST Activity visibility NMTOKEN #REQUIRED> <!ProcessRole> <!ELEMENT ProcessRole (Description,Activity *, WorkProdtct *)> <!ATTLIST ProcessRole id NMTOKEN #REQUIRED> <!ATTLIST ProcessRole name CDATA #REQUIRED> <!ATTLIST ProcessRole visibility NMTOKEN #REQUIRED> <!ATTLIST ProcessRole processPerformer CDATA #REQUIRED> <!WorkProdtct> <!ELEMENT WorkProdtct (Description,Representation,ProcessRole,Entrant,Sortant)> <!ATTLIST WorkProd'uct id NMTOKEN #REQUIRED> <!ATTLIST WorkProd'uct name CDATA #REQUIRED> <!ATTLIST WorkProdnct visibility NMTOKEN #REQUIRED> <!ATTLIST WorkProdnct kind (report/model/gaide)> <!A TTLIST WorkProd'uct isDeliverable #PCDATA> <!-- Entrant --> <!ELEMENT Entrant (Description,Activity*)> <!Sortant> <!ELEMENT Sortant (Description,Activity*)> <!-- Entree --> <!ELEMENT Entree (Description, WorkProdtct*)> <!-- Sortie --> <!ELEMENT Sortie (Description, WorkProdtct*)> <!Step> <!ELEMENT Step (Action *)> <!ATTLIST Step id NMTOKEN #REQUIRED> <!ATTLIST Step name CDATA #REQUIRED> <!ATTLIST Step visibility NMTOKEN #REQUIRED> <!-- Action --> <!ELEMENT Action (#PCDA TA)> <!ATTLIST Action id NMTOKEN #REQUIRED> <!ATTLIST Action name CDATA #REQUIRED> <!ATTLIST Action visibility NMTOKEN #REQUIRED> <!ATTLIST Action interface #PCDATA> <!-- Discipline --> <!ELEMENT Discipline (Description,ProcessRole -/-,Activity-/-, WorkProdtct-/-)> <!ATTLIST Discipline id NMTOKEN #REQUIRED> <!ATTLIST Discipline name CDATA #REQUIRED> <!ATTLIST Discipline visibility NMTOKEN #REQUIRED> La notion d'artefact en génie logiciel fait référence à trois types de production : le rapport, le modèle (on élément de modèle) et le guide. Nous supposerons dans la suite que nous ne traitons que de ceux-là. En effet, il s'avère compliqué de définir jusqu'à la typologie des rapports, cela pourrait contraindre l'utilisateur et nécessiterait un travail assez ennuyeux pour l'expert du domaine. Pour ce qui est des guides, il suffit au moment de renseigner les connaissances sur les processus de les fournir préalablement élaborés sous des formats html, pdf ou doc. |
|