4.4 Formation des RGB
La composition colorée représente la plate
forme de notre travail. A l'occasion une fonction intégrée dans
le programme permet de regrouper les canaux appelés pour la formation de
la composition souhaitée.
Chaque RGB est caractérisée par sa dynamique et
la correction gamma comme décrit au chapitre 2. Ainsi la valeur en
niveau de gris (de 0 à 255) d'une composante R, G ou B d'un pixel
donné est calculée par la formule suivante :
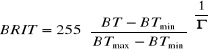
Avec
BT la valeur d'enregistrement.
BTmin : la valeur minimale de la dynamique ou de
température.
BTmax : la valeur maximale de la dynamique ou de
température.
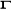 : représente la correction gamma. : représente la correction gamma.
D'autre correction seront intégrée à
l'occasion telle que la correction gamma 2.
4.5 La segmentation
proposée : k.moyens
Lorsque nous voulons développer un système de
segmentation, nous sommes souvent confrontés au problème de la
sélection des meilleurs attributs pour cette segmentation. Pour cela,
nous avons utilisé deux critères de sélection : la
complexité et la taille en mémoire.
La réduction du nombre de couleurs d'une image couleur
est un problème de quantification classique.
L'algorithme k-means est l'algorithme de clustering
le plus connu et le plus utilisé, du fait de sa simplicité de
mise en oeuvre. Il partitionne les données d'une image en K clusters.
Contrairement à d'autres méthodes dites hiérarchiques, qui
créent une structure en « arbre de clusters » pour
décrire les groupements, k-means ne crée qu'un seul
niveau de clusters. L'algorithme renvoie une partition des données, dans
laquelle les objets à l'intérieur de chaque cluster sont aussi
proches que possible les uns des autres et aussi loin que possible des objets
des autres clusters. Chaque cluster de la partition est défini par ses
objets et son centroïde.
Le k-means est un algorithme itératif qui
minimise la somme des distances entre chaque objet et le centroïde de son
cluster. La position initiale des centroïdes conditionne le
résultat final, de sorte que les centroïdes doivent être
initialement placés le plus loin possible les uns des autres de
façon à optimiser l'algorithme. K-means change les
objets de cluster jusqu'à ce que la somme ne puisse plus diminuer. Le
résultat est un ensemble de clusters compacts et clairement
séparés, sous réserve qu'on ait choisi la bonne valeur K
du nombre de clusters.
La méthode proposée consiste à calculer
la distance euclidienne entre le pixel à traiter et les centres des
classes. La difficulté de cet algorithme réside essentiellement
dans la définition des classes et l'initialisation des centres.
| 

