Plateformes de services intégrés pour mobiles( Télécharger le fichier original )par Djibril GUEYE Université Cheikh Anta Diop de Dakar - Diplôme d'Ingénieur de Conception 2008 |

Troisième partie : Mise en place de la solution
Cette partie est composée de deux chapitres qui portent sur : Ø Le choix des outils et technologies d'implémentation : pour la réalisation de chaque tâche, on présente les différentes possibilités et on en retient une que l'on va utiliser ; Ø L'implémentation de la plateforme : Ici nous présenterons dans les détails la réalisation des différentes tâches identifiées.
Chapitre 6 : Choix des outils et des technologies d'implémentationI. Les plateformes applicatives Une plate-forme applicative se présente sous la forme d'une suite logicielle comprenant l'ensemble des briques nécessaires au déploiement d'une application client/serveur de haut niveau à savoir : une application ou plusieurs applications serveur accessibles - généralement en mode Web - depuis des postes de travail ou des terminaux Internet. A chaque élément de la suite son rôle : · Le serveur d'applications gère le noyau de l'application avec pour objectif central de répondre aux requêtes des utilisateurs s'y connectant. · Le serveur de données stocke l'ensemble des données métier et techniques nécessaires au bon fonctionnement de l'application. · L'infrastructure de portail a pour but d'orchestrer les droits d'utilisation de l'application et de gérer la personnalisation des données et des accès fonctionnels. · Le serveur d'intégration prend en charge les éventuels flux de données ou composants à prendre en compte, en provenance d'autres serveurs d'applications ou systèmes. Dans ce domaine, deux architectures sophistiquées mènent une rude bataille. Il s'agit de J2EE (pour Java 2 Enterprise Edition) et .Net. Cependant la combinaison Apache/Mysql/PHP, adossée à un système d'exploitation, brille aussi de mille feux. Lancé par Sun en 1998, autour du langage Java, il s'articule autour d'une infrastructure standardisée, couvrant les principales couches d'une plate-forme applicative (serveur d'applications, infrastructure de portail et serveur d'intégration), ainsi que les liens avec la base de données (ou persistance). J2EE est aujourd'hui implémenté par les principaux éditeurs de serveurs d'applications du marché, parmi lesquels on compte IBM, Oracle et BEA. J2EE est portable d'un système d'exploitation à l'autre. Un point fort qui, dès l'origine, a été mis en avant par Sun comme l'une des principales valeurs ajoutées de son infrastructure. Initialement, Java a d'ailleurs été élaboré pour répondre précisément à cet enjeu. Dans la même logique, J2EE facilite également le portage d'une application Java entre serveurs d'applications, pour peu que ces derniers répondent aux spécifications définies par Sun dans ce cadre. Le modèle .Net (lire DotNet) a été lancé par Microsoft en 2001 en réponse à J2EE. Cette plate-forme, rebaptisée en 2003 Windows Server System, s'adosse à la manière de J2EE à une logique de développement et de déploiement de nouvelle génération (orientée objets). Son principal point fort : aussi structurante et riche fonctionnellement que son équivalent Java, elle n'en offrirait pas moins une approche de travail beaucoup plus simple. Basé sur C#, .Net offre un autre avantage de taille sur J2EE : son noyau permet d'exécuter des applications développées dans n'importe quel langage, à partir du moment où Microsoft a décidé de le supporter. C'est notamment le cas avec le Python ou encore le Cobol. Cependant c'est une plateforme trop propriétaire et ne tourne que sous Windows. 3. Les environnements basés sur AMP PHP est un langage de scripts. Il est
interprété, par conséquent il ne nécessite pas
d'être compilé pour obtenir un objet, un exécutable avant
d'être utilisable (comme en C par exemple). Suivant le système d'exploitation utilisé qui assure l'attribution des ressources aux autres composants de la plateforme, on parle de LAMP, WAMP, MAMP, SAMP respectivement pour Linux, Windows, Macintosh, Solaris. 4. Interopérabilité J2EE, .NET, PHP Offrir davantage d'ouverture et de compatibilité entre systèmes informatiques est depuis longtemps un secteur en constante évolution. L'avènement des technologies Internet n'a fait qu'étendre ce vieux concept à des applications distribuées au delà d'un réseau d'entreprise. Le secteur économique des TIC (Technologies de l'Information et de la Communication) est bien évidemment à l'écoute de ce genre de problématique car fournir des services informatiques intégrables directement, et de manière transparente, au sein de SI existants intéresse nécessairement des acteurs, existants ou futurs, de ce marché. Dans l'absolu, l'interopérabilité consiste à utiliser conjointement des fonctionnalités d'applications basées sur des technologies différentes (J2EE, .NET, PHP, C++, etc.). Une des motivations peut provenir de la volonté de consommer depuis ses applications des services métier gérés par des partenaires externes (opérateurs, établissements bancaires, etc.). C'est un dialogue bilatéral entre deux systèmes. Le véritable objectif est alors de permettre cette interopérabilité le plus simplement possible, en abstrayant à la fois aux utilisateurs finaux et aux développeurs la complexité et la diversité des environnements. L'administration technique du SI ne doit cependant pas s'en trouver complexifiée outre mesure. Il est important que les équipes responsables de cette administration puissent facilement prendre le contrôle et gérer ces solutions. Prenons l'exemple de notre application de MTicketing qui a besoin de communiquer avec le SI de l'opérateur et, par moment, avec les établissements bancaires. Au delà de simples appels de fonctions sur des applications de ces différents SI, des besoins de sécurité (paiement en ligne), de gestion transactionnelle (réservation) ainsi que de transmission de données « brutes » (le code barre en image) doivent être gérés. Et tout cela de la manière la plus transparente possible et avec la plus grande facilité d'administration ! II. Les plateformes de développement pour clients mobiles La bataille que se livre actuellement Sun et Microsoft au sujet des environnements de développement a un impact direct sur les plateformes embarquées proposées de part et d'autre. D'un coté, Sun propose Java 2 Micro Edition (J2ME) à travers son architecture J2SE, et de l'autre, Microsoft propose Smart Device Extensions (SDE) basé sur sa plate-forme .NET. Si jusqu'au début du millénaire, ce marché était essentiellement représenté par des acteurs très spécifiques de l'embarqué autour de multiples technologies propriétaires, il semble acquis aujourd'hui, à la lueur des évènements, que ces deux leaders mondiaux du logiciel que sont Microsoft et Sun seront à l'origine des prochaines générations de plateformes embarquées. Ce recentrage autour de Java et .NET ne sera pas sans effets. D'une part, l'utilisation de technologies standards et largement adoptées par l'industrie va tendre à réduire les risques d'enfermement technologiques et pérenniser les investissements. D'autre part, cela aura un impact indéniable en termes de réduction des coûts car les outils, les compétences et les architectures matérielles se résumeront à ces deux plateformes maîtrisées. Il va de soi que le mieux placé sur le terrain des outils de développement aura un avantage indéniable sur celui de la production. A partir de ce constat, nous avons choisi de défricher les deux solutions prédominantes du moment. Dans un premier temps, nous nous attacherons à présenter les deux architectures concurrentes, puis nous porterons notre choix sur l'une d'elles que nous présenterons plus en détail. 1. La diversité des périphériques La mise en place d'une plate-forme technique commune à tous les périphériques est une opération très délicate. Chaque appareil possède des spécificités qui obligent les applications à s'adapter à différentes caractéristiques d'affichage ou de pointage. Microsoft et Sun n'ont pas du tout la même approche concernant ce problème. Si J2ME s'attache à unifier par le biais d'APIs les différents types d'appareils, Microsoft préfère proposer un ensemble de briques logicielles dans le cadre de son système d'exploitation embarqué : Windows CE.
Figure 42 : Diversité des périphériques embarqués La liste suivante démontre la variété des terminaux ciblés par les deux plate-formes : · Téléphone cellulaire, Smartphone (Nokia, Ericsson, Alcatel, Siemens, ...) · Assistant personnel, PDA (Palm Pilot, PocketPC, ...) · Appareil d'imagerie numérique (Caméscope numérique, Appareils photo numérique, ...) · Appareil automatique industriel (Robot dans une chaîne d'usinage, Affichage embarqué dans les automobiles,...) · Application Internet/Media · Portail d'entrée automatique · Appareil de paiement, Web Pad, Windows Thin Client, ... Toute la difficulté de concevoir des technologies pour l'embarqué réside dans cette complexité inhérente à la diversité de l'offre. Nous verrons que cela aura un impact important sur la conception interne des environnements proposés de part et d'autre. 2. L'architecture Java 2 Micro Edition (J2ME)
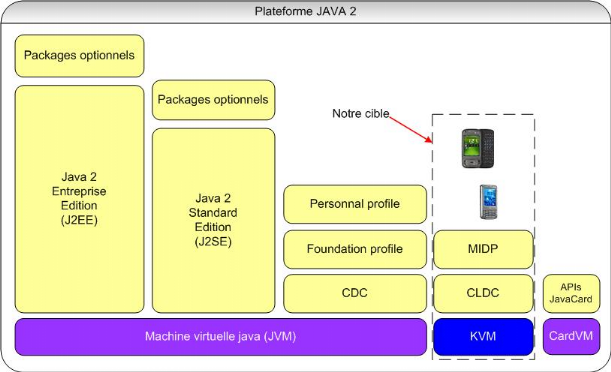
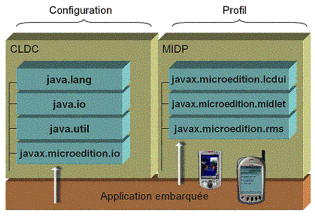
Java 2 Micro Edition ou Java ME ou Java Platform Micro Edition est l'édition de la plateforme Java à destination de l'électronique grand public. Cette architecture technique a donc pour but de fournir un socle de développement aux applications embarquées. L'intérêt étant de proposer toute la puissance d'un langage tel que Java associé aux services proposés par une version bridée du Framework J2SE : J2ME. Les terminaux n'ayant pas les mêmes capacités en termes de ressources que les ordinateurs de bureau classiques (mémoire, disque et puissance de calcul), la solution passe par la fourniture d'un environnement allégé afin de s'adapter aux différentes contraintes d'exécution. Cependant, comment faire en sorte d'intégrer la diversité de l'offre à un socle technique dont la cible n'est pas définie à priori ? La solution proposée par J2ME consiste à regrouper par catégories certaines familles de produits tout en proposant la possibilité d'implémenter des routines spécifiques à un terminal donné. L'architecture J2ME se découpe donc en plusieurs couches : 1. Les profils : Ils permettent à une certaine catégorie de terminaux d'utiliser des caractéristiques communes telles que la gestion de l'affichage, des évènements d'entrées/sorties (pointage, clavier, ...) ou des mécanismes de persistance (Base de données légère intégrée). Ces profils sont soumis à spécifications suivant le principe du JCP (Java Community Process) 2. Les configurations : Elles définissent une plateforme minimale en termes de services concernant un ou plusieurs profils donnés. 3. Les machines virtuelles : En fonction de la cible, la machine virtuelle pourra être allégée afin de consommer plus ou moins de ressources 4. Le système d'exploitation : L'environnement doit s'adapter au système d'exploitation existant (Windows CE, Palm Os, SavaJe, ...) Cette architecture en couches a pour but de factoriser pour des familles de produits données un ensemble d'APIs permettant à une application de s'exécuter sur plusieurs terminaux sans modification de code. Une configuration est un environnement d'exécution Java complet constitué de trois éléments : · Une machine virtuelle Java (JVM) pour exécuter le code Java. · Le code natif qui compose l'interface avec le système sous-jacent. · Un assortiment de classes Java exécutables. Pour pouvoir utiliser une configuration sur une machine donnée, elle doit remplir certaines conditions minimales définies dans les spécifications officielles. Bien qu'une configuration ne fournisse pas un environnement Java complet, l'ensemble des classes du noyau est normalement très petit et doit être enrichi d'autres classes supplémentaires fournies par les profils de J2ME ou grâce à l'implémenteur de configuration. En particulier, les configurations ne définissent aucune classe destinée à l'interface utilisateur. J2ME définit deux configurations : la CLDC et la CDC CLDC signifie Connected Limited Device Configuration. Ce qui peut être traduit par configuration limitée pour appareils connectés. Cette configuration s'adresse aux terminaux légers tels que les téléphones mobiles ou les assistants personnels. Ces périphériques étant limités en termes de ressources, l'environnement classique ne permet pas de respecter les contraintes d'occupation mémoire liées à ces appareils. J2ME définit donc un ensemble d'API spécifiques à CLDC et destinées à utiliser les particularités de chaque terminal d'une même famille (profil). La liste suivante résume l'ensemble de ses caractéristiques : · Minimum de 160Ko à 512Ko de RAM, processeur 16 ou 32 bits, vitesse 16Mhz ou plus · Alimentation limitée, prise en charge d'une batterie · Connexion réseau non permanente, sans fil. · Interface graphique limitée ou inexistante Définie par un sous-ensemble de classes Java s'exécutant dans la KVM (KiloByte Virtual Machine), la CLDC s'inscrit donc dans une logique d'économie de ressources avec une KVM de 40 à 80 Ko s'exécutant 30 à 80% moins vite qu'une JVM normale. Il n'y a aucun compilateur Just-In-Time20(*) ni même de prise en charge des nombres flottants. La KVM omet d'autres caractéristiques importantes telles que la finalisation. Cependant l'assortiment de classes exécutables du noyau ne représente qu'une toute petite fraction des classes du noyau de J2SE - classes de base des paquetages java.lang, java.io et java.util - accompagnées de quelques classes supplémentaires issues du nouveau paquetage javax.microedition.io. Quant au Multi-threading et au Ramasse miettes, ils demeurent supportés. La CLDC n'intègre pas, non plus, la gestion des interfaces graphiques, la persistance ou les particularités de chaque terminal. Ces aspects ne sont pas de sa responsabilité. La matrice suivante résume les packages et classes présents dans cette couche :
Tableau 9 : Les packages de CLDC Le package javax.microedition.io fait partie des briques non incluses dans J2SE tel qu'illustré dans la figure ci-après. Il gère les connexions distantes ou entrées/sorties réseau. CDC signifie Connected Device Configuration. Ce qui peut être traduit par configuration pour dispositifs connectés. Elle spécifie un environnement pour des terminaux connectés de forte capacité tels que les téléphones à écran, la télévision numérique, etc. Les caractéristiques de l'environnement matériel proposées par la configuration CDC sont : · Minimum de 512Ko de ROM et 256Ko de RAM, processeur 32 bits · Une connexion réseau obligatoire (sans fil ou pas) · Support des spécifications complètes de la machine virtuelle Java optimisée, compacte et nommée pour l'occasion CVM (machine virtuelle C)
Figure 43 : Etendue des responsabilités de CDC et CLDC dans Java Cette configuration s'inscrit donc dans le cadre d'une architecture Java presque complète. C'est la raison pour laquelle elle requière plus de mémoire que la CLDC et un processeur plus rapide. La CDC est en fait un sur-ensemble de la CLDC. Un profil ajoute à une configuration des classes spécifiques d'un domaine afin de combler l'absence d'une fonctionnalité et pour supporter les utilisations spécifiques d'un dispositif. Par exemple, la plupart des profils définissent des classes d'interfaces utilisateurs qui permettent de construire des applications interactives. Pour pouvoir utiliser un profil, la machine doit satisfaire à toutes les exigences minimales de la configuration sous-jacente ainsi qu'à toutes les exigences rendues obligatoires par les spécifications officielles du profil qui se surajoutent. Il existe plusieurs profils qui en sont à des stades de développement variables. Le Mobile Information Device Profile (MIDP = profil pour dispositifs informatiques mobiles), premier profil publié, est basé sur la CLDC et conçu pour les applications tournant sur téléphones mobiles et les bips interactifs disposant d'un petit écran, d'une connexion HTTP sans fil et d'une mémoire limitée. Un autre profil plus évolué basé sur la CLDC, le Personal Digital Assistant Profile (PDAP = profil pour assistant numérique personnel), prolonge le MIDP en lui ajoutant de nouvelles classes et caractéristiques permettant de couvrir la gamme des appareils de poche plus puissants. En ce qui concerne les profils de type CDC, le Foundation Profile (FP = profil fondamental) prolonge la CDC en lui ajoutant des classes de J2SE, le Personal Basis Profile (PBP = profil personnel de base) prolonge le FP grâce à l'ajout de classes peu encombrantes d'interfaces utilisateurs dérivées de l'Abstract Window Toolkit (AWT = outil qui permet de générer les fenêtres de dialogue de l'interface utilisateur) et d'un nouveau modèle d'application, et le Personal Profile prolonge le PBP avec le support d'applets et des classes d'interfaces utilisateurs plus encombrantes.
Le Mobile Information Device Profile (MIDP) définit un environnement d'exécution pour une classe d'appareils référencés sous le nom d'appareils mobiles d'informations (MID = mobile information devices). Cela correspond aux appareils dotés des caractéristiques minimales suivantes : · Suffisamment de mémoire pour exécuter les applications du MIDP · Un écran numérique adressable d'au moins 96 pixels de largeur sur 56 pixels de hauteur, qu'il soit monochrome ou couleur. · Des pavés numériques, un clavier ou un écran tactile. · La capacité d'établir une liaison sans fils bidirectionnelle. Il contient des méthodes permettant de gérer l'affichage, la saisie utilisateur et la gestion de la persistance (base de données). Il existe aujourd'hui deux implémentations majeures de profils MIDP : l'une, plus spécifique, destinée aux Assistants de type Palm Pilot (PalmOs) et l'autre, totalement générique, proposée par Sun comme implémentation de référence (RI). Voici un tableau présentant les API liés à ce profil :
Tableau 10 : Les packages de MIDP L'API lcdui est chargée de gérer l'ensemble des contrôles graphiques proposés par ce profil. Quant à la gestion des événements, elle suit le modèle des listeners du J2SE avec un CommandListener appelé en cas d'activation d'un contrôle. Pour finir, rms fournit les routines nécessaires à la prise en charge d'une zone physique de stockage. Toute application MIDP est appelée MIDlet et doit dériver de la classe javax.microedition.midlet. Midlet. Les Midlets sont l'élément principal d'une application Java embarquée.
Figure 45 : MIDlet, CLDC et MIDP Pour bien saisir leur mode de fonctionnement, il suffit de prendre comme analogie les Applets ou les Servlets. Le cycle de vie d'une Applet est géré par un conteneur, en l'occurrence le Navigateur Web, dont le rôle est d'interagir avec celle-ci sous la forme de méthodes de notifications prédéfinies (init(),paint(),destroyed(),...). Une servlet possède les mêmes caractéristiques qu'une Applet excepté le fait que le conteneur est un moteur de servlet (Tomcat, WebSphere, WebLogic, ...). Quant aux Midlets, ils représentent le pendant des Applets et des Servlets pour J2ME avec comme conteneur le téléphone mobile ou l'assistant personnel. Ainsi, en cas de mise à jour d'une application embarquée, un simple téléchargement de code Midlet est nécessaire à partir d'un quelconque serveur. De cette manière, un programme développé pour un profil donné est en mesure de s'exécuter sur tous les périphériques correspondant à cette famille. C'est aussi une manière de découpler le socle technique des applicatifs puisque le seul lien existant entre les logiciels embarqués et le terminal est l'API J2ME. Une MIDlet connaît trois états dans son cycle de vie : en pause, active et détruite. Une fois créée par le système d'exploitation du téléphone, son état devient "en pause". Puis le système invoque la méthode startApp() qui change l'état en actif. Le retour au premier état a lieu lors de l'invocation de la méthode pauseApp(). Enfin, à tout moment l'exécution de la méthode destroyApp() conduit à l'état détruit. Nous constatons ainsi que la méthode startApp() peut se voir appelée plusieurs fois au cours du cycle de vie de l'application. Le constructeur de la MIDlet fera donc office de méthode main() pour toutes les tâches ne devant s'opérer qu'une seule fois.
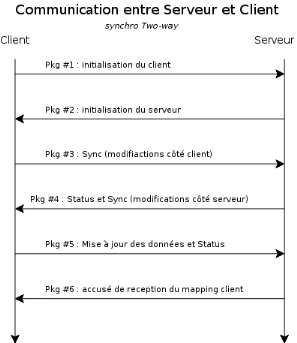
Figure 46 : Cycle de vie d'une Midlet 3. L'Architecture Microsoft Windows Embedded A travers le temps, l'approche de Microsoft concernant le monde de l'embarqué a considérablement évolué. De Microsoft Embedded Visual Tools (eVB et C++), nous sommes passé à la plate-forme .NET et les différents langages qui l'accompagnent (C#, VB.NET, ...). Même s'il est vrai que l'engouement autour de cet univers des terminaux légers est allé croissant dès lors que les PDA et autres téléphones mobiles ont fait leur apparition, il n'en demeure pas moins que ce segment de marché a toujours été délaissé par le géant éditeur de logiciels. Aujourd'hui, l'offre de Microsoft est essentiellement basée sur son système d'exploitation embarqué : Windows CE. Microsoft Embedded propose une approche plus orientée « système » de l'embarqué. Un constructeur désireux d'intégrer un environnement Windows dans un terminal donné, devra extraire les briques logicielles d'une version standard en fonction des caractéristiques du récepteur. Par exemple, dans le cas d'un périphérique sans fil, les composants embedded « wireless » accompagnés des drivers adéquats seront proposés à l'intégrateur. Lorsque le terminal nécessite une base de données embarquée, il suffira de générer une image du Système d'exploitation prenant en compte cette contrainte. Bref, Microsoft propose une panoplie de composants systèmes en tout genre et adaptés à tout type de besoin, charge ensuite à l'intégrateur de définir sa propre configuration. Cette approche comparée à Java est donc sensiblement différente. Avec l'avènement du Framework .NET, la partie embarquée de l'offre de Microsoft a subi quelques évolutions majeures. Ainsi, le .NET Compact Framework (.NET CF) a fait son apparition au sein de l'architecture avec une philosophie proche de J2ME pour Java : Un ensemble d'API allégés permettant de répondre aux exigences des périphériques en termes de ressources. Mais .NET CF se destine aux plateformes Windows CE. J2ME et Microsoft embedded Architecture ont une approche totalement différente dans leur manière d'aborder le développement embarqué. Si Java privilégie l'aspect Multi-périphériques et Multi-OS, Microsoft préfère concentrer ses efforts sur Windows CE, son système d'exploitation maison. Malgré tous ces efforts, force est de constater que la technologie Microsoft ne parvient pas à rivaliser avec J2ME, ce dernier conservant de loin la première place en termes de taux de pénétration sur le terrain des logiciels mobiles. La plupart des grands constructeurs de téléphones portables au premier rang desquels figure Nokia demeurent en effet fidèle à l'infrastructure de Sun. Principal point fort de J2ME : sa portabilité. Une caractéristique qui le rend des plus attractifs pour les fournisseurs de services embarqués, qui cherchent à rendre leurs applications indépendantes des machines sous-jacentes. De plus, il est à noter qu'il existe des machines virtuelles Java permettant d'exécuter une application J2ME sur Windows CE. Une source de données est une installation de stockage des données. Elle peut être aussi sophistiquée qu'une base de données complexe, un annuaire ou un entrepôt de données pour une grande entreprise ou aussi simple qu'un fichier avec des lignes ou des colonnes. Une source de données peut être localisée sur un serveur distant ou bien disponible en local sur une machine de bureau. Une base de données (son abréviation est BD, en anglais DB, database) est une entité dans laquelle il est possible de stocker des données de façon structurée et avec le moins de redondance possible. Ces données doivent pouvoir être utilisées par des programmes, par des utilisateurs différents. Afin de pouvoir contrôler les données ainsi que les utilisateurs, le besoin d'un système de gestion s'est vite fait ressentir. La gestion de la base de données se fait grâce à un système appelé SGBD (système de gestion de bases de données) ou en anglais DBMS (Database management system). Le SGBD est un ensemble de services (applications logicielles) permettant de gérer les bases de données, c'est-à-dire : · permettre l'accès aux données de façon simple · autoriser un accès aux informations à de multiples utilisateurs · manipuler les données présentes dans la base de données (insertion, suppression, modification) Les systèmes qui emploient le modèle relationnel pour contrôler la base de données sont nommés SGBDR (système de gestion de base de données relationnel). De manière basique, tous les SGBD disponibles sur le marché intègrent ces fonctionnalités. D'autres raisons présideront alors au choix de l'un ou de l'autre parmi eux. Notre étude portera sur deux d'entre eux disponibles en open source. Disponible sou licence GPL sous Linux, Windows, MacOSX, Unix, BSD, MySQL en est à sa version 5.0.15 (beta 5.1). Ses principaux avantages sont : · Solution très courante en hébergement public · Très bonne intégration dans l'environnement Apache/PHP · OpenSource · Facilité de déploiement et de prise en main. · Plusieurs moteurs de stockage adaptés aux différentes problématiques. Il présente cependant quelques inconvénients : · Ne supporte pas entièrement des standards SQL-92 · Support incomplet des triggers et procédures stockées · Assez peu de richesse fonctionnelle · Manque de robustesse avec de fortes volumétries · Pas d'héritage de tables · Pas de vue matérialisée · Pas d'ordonnanceur intégré · Pas de partitionnement C'est un SGBDR fonctionnant sur des systèmes de type UNIX et sur Windows. Ses avantages sont : · Open Source et gratuit · Fiable et relativement performant, tout en restant simple d'utilisation · Supporte la majorité du standard SQL-92 et possède en plus un certain nombre d'extensions (Java, Ruby, PL-SQL). · Très riche fonctionnellement, notions d'héritage de tables, multitude de modules · Simple d'utilisation et d'administration · Héritage de tables Il présente néanmoins quelques inconvénients : · Sauvegardes peu évoluées · Supporte les bases de moyenne importance · Pas de services Web · Pas de support XML · Pas d'ordonnanceur intégré · Pas de vue matérialisée · Permissions seulement au niveau de la table, pas au niveau de la colonne IV. Les solutions de synchronisation La synchronisation offre la possibilité à un terminal de se connecter à un réseau afin de mettre à jour à la fois l'information de l'appareil et l'information du réseau pour que les deux soient identiques et à jour. Devant la prolifération d'appareils mobiles et de protocoles propriétaires ainsi que la demande croissante d'accès à de l'information en situation de mobilité, les sociétés leader sur le domaine ont compris l'intérêt de créer un langage standard et universel décrivant les actions de synchronisation entre les terminaux et les applications. Elles ont formé un consortium pour sponsoriser cette initiative et pour créer ce langage. Actuellement, le consortium SyncML a été adopté et incorporé à l'Open Mobile Alliance, un regroupement de plus de 300 sociétés qui supporte plusieurs projets collaboratifs portant sur les technologies et les protocoles. SyncML ou Synchronization Markup Language est le protocole standard, basé sur XML, de synchronisation de données au travers d'une multitude de réseaux, de plates-formes et de terminaux. SyncML a été démarré en tant qu'initiative en 2000 par de grandes sociétés comme Ericsson, IBM, Palm Inc., Lotus, Matsushita Ltd. (Panasonic), Motorola, Nokia, Openwave, Starfish Software, Psion et Symbian. Leur but était la création d'un langage universel à partir de la myriade de protocoles de synchronisation propriétaires utilisés par les appareils mobiles et de fournir un ensemble complet de fonctionnalités de synchronisation pour les futurs terminaux. Le consortium a sorti la version 1.0 en décembre 2000. Ils ont développé de nouvelles fonctionnalités et résolu les problèmes découverts avec cette version, finalisant le protocole avec la version 1.1 en février 2002. Le protocole SyncML a été conçu en gardant ces objectifs à l'esprit : · Garder en cohérence deux ensembles de données · Être indépendant du transport · Être indépendant de la donnée synchronisée (PIM, email, fichier, ....) SyncML comprend des commandes client et serveur définies par des DTD. Voici quelques éléments de vocabulaire : · Client - le terminal mobile, son application et sa base de données locale. · Serveur - un système distant communiquant avec la base de données du système ou de l'application. · Modifications - les données dans les champs d'une base de données qui sont modifiées. · Synchronisation - le client et le serveur échangent des messages SyncML avec des commandes. · Package - Balises XML conformes à la DTD de SyncML décrivant les requêtes ou actions qui doivent être effectuées par un client ou un serveur SyncML. Un package est un ensemble d'actions à effectuer. · Message - La plus petite unité de balise SyncML. Les grands packages sont découpés en messages séparés. · Mapping - Utilisation d'un identifiant intermédiaire pour lier deux informations. Exemple: Disons que 'vert' c'est '5', et '5' c'est bien. Qu'est-ce qui est bien ? Si vous répondez 'vert', vous êtes tombé juste. vous avez réalisé un mapping ! Un message est un ensemble de commandes SyncML transmises (en une seule fois) vers le client ou le serveur. La taille maximale d'un message est définie par la Meta données MaxMessageSize. Si un message à transmettre dépasse cette taille on le découpe en plusieurs messages. On parle alors de Multiple Message in Package. Un package correspond à un ensemble de messages pour effectuer une des étapes de la synchronisation. Les packages sont les suivants: pkg1 = initialisation du client (authentification, échange des devinf, des informations sur les bases à synchroniser), pkg2 = initialisation du serveur, pkg3 = modification côté client, pkg4 = modification côté serveur, pkg5 = mis à jour des données et statuts, pkg6 = mapping des ids client et serveur. SyncML est basé sur XML mais supporte obligatoirement un protocole de transport, par exemple HTTP, OBEX21(*) ou WSP22(*). Mais SyncML ne change pas quelque soit le protocole de transport. Une session SyncML est constituée de 4 phases :
Figure 47 : Communication SyncML entre client et serveur 1. La phase d'alerte du serveur, qui est optionnelle et peut être considérée comme une phase de pré-initialisation. Son principal objectif est de permettre au serveur d'alerter le client sur une probable session à démarrer. 2. L'initialisation de la synchronisation qui est un passage obligatoire pour le client et le serveur avant d'entamer une synchronisation. La première étape est que le client et serveur parlent le même langage, en s'échangeant l'un et l'autres leurs capacités (définies par le matériel, comme la quantité de mémoire, et le protocole définit par la DTD). La seconde étape est l'identification des bases de données à synchroniser. Ensuite, les deux doivent décider du type de synchronisation. La troisième et dernière partie est l'authentification. Une fois que cette étape à été complétée avec succès, la synchronisation à proprement parler peut commencer. 3. L'échange de données : normalement le client commence par envoyer ses modifications. Le serveur les reçoit, détecte et résout les conflits avant d'envoyer ses modifications. 4. La phase de finalisation dans laquelle s'effectuent le mapping, la mise à jour des ancres et l'envoi d'accusé de réception. Le client s'identifie puis se met d'accord avec le serveur sur les principes d'échanges. L'adressage est réalisé au travers des balises <Source> et <DocURI>. Un serveur aura une URI du genre http://www.2si.syncml.com/sync et le terminal mobile client aura un numéro d'identification IMEI comme ceci 354101000208403. SyncML est basé sur l'idée que les clients et les serveurs peuvent avoir leur propre méthode pour faire correspondre les informations dans leur base de données. Aussi, les clients et les serveurs doivent avoir leur propre ensemble d'identifiants uniques. Par gain de place, certains terminaux mobiles ne peuvent accepter, en effet, des id trop longs, ils vont alors définir leur propres id, et envoyer au serveur le mapping à effectuer à l'aide de la balise <Map>. De cette manière, le mobile ne stocke que l'id qu'il a choisi (généralement assez court) et le serveur, lui, stocke les deux, ce qui lui permet de s'adresser au mobile avec l'id que le mobile connait. Le serveur conserve l'ensemble des id indéfiniment. Dans les futurs échanges, le mobile utilisera seulement l'id qu'il connait, et le serveur se chargera d'effectuer les mappings correspondants. · Les identifiants locaux uniques (LUID - Locally Unique Identifiers) sont des nombres assignés par le client à une donnée dans la base de données locale (comme un champ ou une ligne). Ce sont des nombres non réutilisables assignés à ces objets par le client SyncML. · Les identifiants globaux uniques (GUID - Globally Unique Identifiers) sont des nombres assignés à une donnée utilisés dans une base de données distante. Cet identifiant est assigné par le serveur. Le serveur va créer une table de correspondance pour lier les LUID et GUID ensemble. Données côté client
Données côté serveur
Correspondance sur le serveur
Les change logs sont une manière pour un dispositif (client ou serveur) de déterminer la liste des modifications dans la base depuis la dernière synchronisation Les ancres servent à savoir si la dernière synchronisation s'est bien passée. Au début de session, le client envoie ses ancres (last et next). Le serveur stocke la next du client. A la fin de la session (s'il n'y pas eu d'interruption), le client met à jour ses ancres (last = next et il incrémente next). Lors de la prochaine session, le client envoie son next et last. Le serveur vérifie que le last du client vaut le next qu'il a stocké précédemment. Si c'est le cas, c'est OK, on continue. Sinon ça ne va pas du tout et le serveur peut forcer une slow sync.
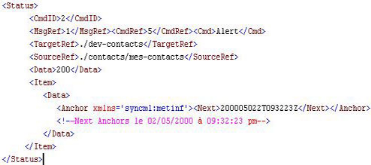
Figure 48 : Exemple d'ancre SyncML Dans sa version 1.1, le langage SyncML définit 7 types de synchronisation. La section ci-dessous définit ces différents types: 1. Two-way Sync (Synchronisation bi-directionnelle) - Le client et le serveur s'échangent des informations relatives aux données modifiées. Le client transmet les modifications en premier. 2. Slow sync (Synchronisation lente) - Le client renvoie l'intégralité de ses données. Le serveur calcule le delta (avec les siennes) et le renvoie au client. Ce type de synchronisation est généralement utilisé lors d'une première synchro, lors d'une interruption, ou lorsque l'une des deux parties le demande. 3. One-way sync, client only (Synchronisation uni-directionnelle, Client uniquement) - Le client transmet ses modifications. Le serveur les accepte puis met à jour les données sans transmettre en retour ses modifications. 4. Refresh sync from client (Synchronisation de mise à jour avec les donnés du client) - Le client transmet sa base de données entièrement au serveur. Le serveur remplace la base de données cible par celle transmise par le client. 5. One-way sync, server only (Synchronisation uni-directionnelle, Serveur uniquement) - Le serveur transmet ses modifications au client. celui ci les accepte puis met à jour ses données locales sans transmettre en retour ses modifications. 6. Refresh sync from server (Synchronisation de mise à jour avec les donnée du serveur) - Le serveur transmet l'intégralité des informations de sa base de données. La base de données du client est entièrement remplacée. 7. Server alerted sync - Le serveur télé-commande au client d'initier un des modes de synchronisation présentés ci-dessus. De cette façon, le client est contrôlé à distance par le serveur. Comme SOAP, il y a deux parties dans un message SyncML, un en-tête <SyncHdr> et un corps <SyncBody>. L'en-tête contient des méta-informations sur la requête comme la base de données cible <Target> et la base de données source <Source>, les informations d'authentification <Cred>, l'identifiant de session <SessionID>, l'identifiant du message <MsgID>, et la déclaration de la version de SyncML <VerDTD>. Le corps contient les commandes SyncML (les statuts des commandes du message précédent, et toutes les autres commandes prévues par SyncML). Un Exemple de message SyncML
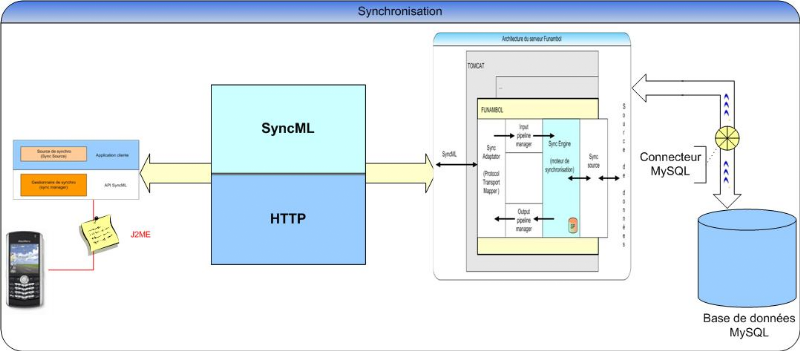
Tableau 11 : Exemple de message SyncML Notez que les lignes {1} et {18} débutent le fichier SyncML par la balise racine. Ensuite, le SyncHdr est défini par les lignes {2} et {8}. Il contient : - les lignes {3,4} qui définissent des informations concernant la version de SyncML utilisée, - la ligne {5} définit l'identifiant de session (sessionID) qui permet d'identifier de façon unique le dialogue qui est en cours entre le client et le serveur, - la ligne {6} représente l'identifiant du message (MsgID) qui permet d'identifier de façon unique cet ensemble de requêtes (toutes ces balises) qui vont être exécutées par l'application réceptrice. - la ligne {7}, on trouve la balise Cred (demande d'authentification, non détaillée ici) qui fait également partie de l'entête. - La ligne {8} est la fermeture du SyncHdr (entête). Le SyncBody (Corps du message) commence à la ligne {9}. Dans cette partie du message SyncML, on trouve : - le statut de l'application/l'appareil {10}, - la source et la cible de la requête (source/target) {12,13}, - et les actions demandées comme la synchronisation elle-même entre les lignes {11,16}. Aux lignes {14,15}, on peut voir les commandes Add et Replace qui commandent respectivement l'ajout et le remplacement de données dans la base de donnée cible. 2. Le serveur de synchronisation La synchronisation offre la possibilité à un terminal de se connecter à un réseau afin de mettre à jour à la fois l'information de l'appareil et l'information du réseau pour que les deux soient identiques et à jour. Convaincus de l'utilité de pouvoir disposer, au besoin, de données à jour sur son mobile, plusieurs éditeurs de logiciels se sont lancés dans la production d'une panacée : un serveur de synchronisation où l'information sur les mobiles serait stockée et centralisée. On distingue deux grandes catégories de sociétés positionnées sur ce segment : les pure players23(*) d'une part, les éditeurs généralistes d'autre part. Présents sur le marché depuis quelques années déjà, les premiers proposent des solutions généralement basées sur des technologies propriétaires et principalement articulées autour d'environnements de développement et d'exécution Java. Les éditeurs généralistes sont les derniers à explorer ce domaine. Dans le monde de l'open source, un produit a fait le vide derrière lui : il s'agit de Funambol. Ce serveur est l'implémentation standard, de facto, de l'OMA. Il fournit, en plus du moteur de synchronisation, des API en C++ ou J2ME, pour le développement d'applications clientes. Ces API cachent au développeur toute la complexité de SyncML. Funambol DS (Data Synchronisation) est contenu dans Tomcat et gère la communication http, la manipulation des sessions, l'échange de données avec le client et beaucoup d'autres fonctionnalités. Son architecture est construite autour du sync engine (moteur de synchronisation). Il transforme les messages SyncML reçus des clients et construit les messages destinés aux clients en guise de réponse. Le moteur de synchronisation permet au développeur de se focaliser sur la source de données à synchroniser avec l'application mobile.
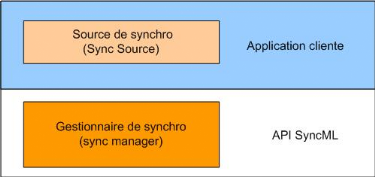
Figure 49 : Architecture du serveur Funambol La figure ci-dessus montre l'architecture du serveur Funambol composé de six éléments principaux: 1. L'adaptateur de synchronisation (sync adaptator ou transport mapper) qui reçoit les messages de SyncML HTTP et les convertit en une représentation interne qui sera envoyée avec HTTP. 2. L'input pipeline manager effectue un traitement supplémentaire du message SyncML entrant. En général il vérifie si la représentation interne est correcte pour être traitée par le moteur de synchronisation 3. L'output pipeline manager est similaire au précédent. Ses traitements se font sur les messages sortants 4. Le moteur de synchronisation est le coeur de Funambol. Il fournit la fonctionnalité applicative pour le protocole SyncML 5. Le moteur a accès à une source persistante dans laquelle il stocke les informations qu'il tient entre les sessions sur l'état de synchronisation des périphériques. 6. La source de synchronisation (sync source) est utilisée pour accéder à la source de données à laquelle un appareil mobile synchronise ses données. L'atout majeur de ce serveur, l'API pour J2ME, se présente comme suit :
Figure 50 : Architecture de l'API SyncML J2ME Une application cliente interagit principalement avec deux entités de l'API: le SyncManager et le SyncSource. Le SyncManager est le composant qui gère toute la communication. Il cache la complexité des processus de synchronisation en fournissant une interface simple à l'application cliente. Le SyncSource représente la collection d'objets stockés dans le répertoire local. Il contient la logique métier du client pour découvrir les éléments à envoyer au serveur et pour stocker ceux obtenus à partir du serveur. Le client alimente le SyncSource avec les éléments changés du côté client, tandis que le SyncManager l'alimente avec les données reçues du serveur. V. Choix des outils d'implémentation adéquats Pour chacun de nos deux services, nous aurons à faire des choix technologiques sur les différents segments de sa réalisation. Le service formant un tout, malgré son découpage en modules, un choix sur un segment peut influer sur le choix dans la réalisation d'un autre module. Ainsi dans le cas du service de sauvegarde, le choix du serveur Funambol, basé sur le critère de l'open source et la fourniture d'APIs, a conditionné l'adoption du J2ME, du reste plus portable que SDE, comme technologie de développement de l'application cliente. De plus la disponibilité d'un connecteur à une base de données MySQL ou un annuaire LDAP fait sortir ces deux sources du lot. Cependant l'objectif même de la synchronisation, qui consiste à mettre à jour à chaque transaction le client et le serveur, joue en défaveur de LDAP prévu pour être plus sollicité en lecture qu'en écriture. Le standard SyncML, supporté par HTTP, sera adopté comme langage de synchronisation car les APIs fournis par le serveur de synchronisation cachent, derrière leur utilisation, la manipulation complexe de ce langage.
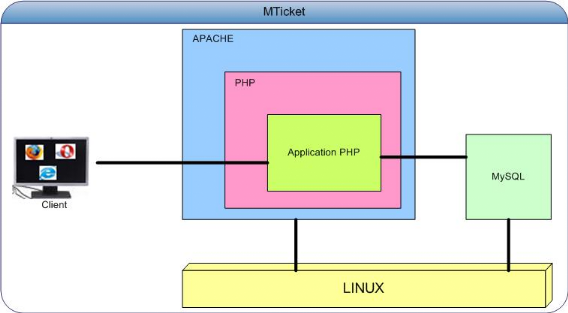
Figure 51 : Architecture applicative de SOS PIN Pour le service de billetterie dématérialisée, une plateforme LAMP est utilisée pour le serveur MTicket. Son caractère totalement open source, la quantité des données manipulées, ainsi que les accès web à réaliser justifient ce choix.
Figure 52 : Architecture applicative de MTicket Cependant nous mettrons en oeuvre les principes d'interopérabilité pour des raisons de sécurité (la génération d'un ticket par un code php rendrait cette opération visible à partir d'un navigateur) et pour assurer la communication sécurisée avec les tiers, étant donné que la réalisation de certains modules (tels que l'envoi du ticket image, le traitement d'un message USSD) est dévolue à des acteurs externes. Java sera alors utilisé pour réaliser certaines de ces tâches. Le process de validation sera quand à lui implémenté avec la plateforme .NET CF étant donné que le Workabout Pro G2 tourne sous Windows CE.
* 20 Compilation à la volée : technique visant à améliorer la performance de systèmes bytecode compilés par la traduction du bytecode en code machine natif au moment de l'exécution * 21 OBject EXchange est un protocole de l'IrDA (Infrared Data Association) proche d'une version binaire de HTTP. Initialement créé par l'IrDA pour les transports sur faisceaux infrarouges, il a été par la suite adapté à d'autres canaux à bande passante réduite, notamment Bluetooth. * 22 La couche WSP (Wireless Session Protocol) est la couche session du WAP * 23 Les entreprises qualifiées de pure players sont des entreprises exerçant uniquement leurs activités sur internet : elles ne possèdent pas de réseau de distribution physique. |
| |||||||||||||||||||||||||||||