Chapitre IX : DISCUSSION
Les réseaux de neurones développés dans
le premier chapitre de ce mémoire, avec une seule variable explicative
en entrée, ont donné de bons résultats. Ces
résultats sont expliqués et confrontés à d'autres
résultats obtenus par différents travaux dans le même
domaine. Les performances des modèles montrent que la transformation
puissance des débits (racine (Q)) observés et calculés
améliore les critères de performances utilisés. En effet,
la transformation puissance donne le même poids à tous les
débits. Elle permet donc au modèle de ne pas donner trop de poids
aux erreurs associées aux événements de crue pendant le
calage. On a remarqué aussi que les Perceptrons Multicouches
Dirigés (PMCD) étaient plus performants que les Perceptrons
Multicouches Non Dirigés(PMCND). En effet, le bouclage avec les
débits mesurés en entrée permet au Réseau de
neurones Formel de situer son état et de s'auto corriger comme
précédemment signalé. C'est ce qui explique les bons
résultats obtenus avec les modèles dirigés (PMCDs). Les
résultats obtenus dans cette étude sont aussi semblables à
ceux obtenus par Eurisouké (2006) pendant la modélisation des
crues éclairs du bassin versant du Gardon de Saint-Jean à Saumane
par les Réseaux de neurones Formels, si l'on considère les
valeurs du critère de Nash. Ces valeurs montrent que le modèle
Non Dirigé (PMCNDs) est moins performant que le modèle
Dirigé (PMCDs) avec respectivement des Nash compris entre 0,58 et 0,86.
Mais lorsqu'on analyse les débits de crue et les débits
d'étiage, on se rend compte que les résultats obtenus dans ces
présents travaux sont différents de ceux obtenus par
Eurisouké (2006). En effet, les travaux présentés ici
montrent que les débits extrêmes sont sous estimés et que
les débits d'étiage sont surestimés. Eurisouké
(2006) dans ces travaux a démontré que les débits de crues
étaient très bien estimés par les Réseaux de
neurones Formels sur le Gardon de Saint-Jean à Saumane. La
différence entre les deux résultats pourrait s'expliquer par le
fait que les données d'entrée utilisées par
Eurisouké (2006) sont plus nombreuses (Imagerie radar à la place
des données pluviographiques) que celles utilisées dans ce
présent mémoire. Les Perceptrons Multicouches peuvent donc
être plus performants lorsque les données qui participent à
leur optimisation sont plus nombreuses.
De façon générale, les débits de
crue sont sous estimés et les débits d'étiage sont
surestimés. En effet, les Réseaux de neurones Formels sont des
modèles à apprentissage, c'est-à-dire qu'ils se
familiarisent aux données pendant le calage afin d'extraire une certaine
singularité dans ces données. Au niveau des séries de
débits utilisées dans cette étude, les débits
extrêmes (crue et étiages) sont en nombre restreint par rapport
aux autres débits. Les crues par exemple s'observent une seule fois par
année (généralement en août-septembre). Il
apparaît donc que les modèles disposent de peu de débits de
cette catégorie en apprentissage pour pouvoir
extraire la singularité signalée
déjà dans la première partie de ce mémoire. La
mauvaise simulation des débits extrêmes par les réseaux de
neurones dans cette étude pourrait être aussi due à la
séparation des bases de calage et de validation (2/3 pour le calage et
1/3 pour la validation). Une sépartion aléatoire pourrait peut
être amélioré les performances de ces modèles.
Malgré la bonne représentativité des
hydrogrammes mesurés par les Perceptrons Multicouches Dirigés, il
apparaît un décalage entre les hydrogrammes mesurés et les
hydrogrammes calculés tant en calage qu'en validation. Ces
décalages sont le fait de l'incapacité des modèles
développés à reproduire certains débits aux
différentes stations d'étude. En effet, les débits
à l'exutoire d'une rivière comme le Bandama Blanc ne sont pas
seulement le fait des seules pluies tombées sur le bassin versant. Ces
débits sont aussi influencés par d'autres variables explicatives
comme la température et l'évapotranspiration potentielle par
exemple. L'intégration de ces variables comme entrée de ces
modèles sera l'objet du chapitre VII et permettra d'apprécier
leur apport dans la simulation des débits aux stations de Bada,
Marabadiassa, Tortiya et Bou. Les mauvaises performances des modèles
développés pourraient être imputées à
l'algorithme d'apprentissage (Koffi et al., 2006). En effet, les
algorithmes du 1er ordre comme la rétro propagation par
erreur du gradient (GD) sont très souvent piégés dans des
minima locaux comme l'illustre la figure 96. Ils n'arrivent
donc pas à atteindre les vrais minima de la fonction de coût.
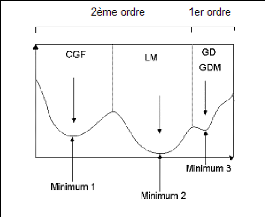
Figure 96 : Evolution des minima locaux
en fonction des algorithmes
En n'atteignant pas le minimum global escompté, les
algorithmes de 1er ordre donneraient des
débits simulés qui s'éloigneraient des
débits observés. Mais, ici les causes des
mauvaises
performances des Réseaux de neurones Formels sont ailleurs
; car, les minima locaux ont pu
être évités grâce à la
réinitialisation et à l'augmentation plusieurs fois des
différents poids suivis du recommencement perpétuel des processus
d'apprentissage. Ce qui évite normalement l'algorithme d'être
piégé dans ces minima locaux. Les mauvaises performances sont
probablement liées au nombre et à la qualité des
donnés hydroclimatiques disponibles dans cette étude. Les
critères de Nash calculés entre les débits mesurés
et les débits calculés varient en calage et en validation de 0,63
à 0,91. A ces valeurs de Nash correspond aussi une variation des
coefficients de corrélation de Pearson de 0,63 à 0,91. A ce pas
de temps mensuel, les résultats semblent satisfaisants. A ce même
pas de temps, Achite et Mania (2000) dans l'application des modèles
neuronaux à la détermination des débits de l'Oued Haddad
avec seulement les pluies en entrée, ont obtenu des coefficients de
corrélation compris entre 0,61 à 0,90, soit dans la même
gamme que ceux de cette étude.
Les résultats des simulations avec le modèle
GR2M sont généralement satisfaisants. En calage, les Nash obtenus
aux stations de Bada, Tortiya et Bou sont supérieurs à 60 %. A la
station de Marabadiassa, elle n'est que de 51 % (juste la moyenne). En
validation, tous les Nash sont supérieurs à 60 % sauf celui
déterminé à la station de Bou qui est de 21 %. Les
coefficients de corrélation (R) déterminés sont positifs
et proche de 1 à toutes les stations. En validation par exemple, ce
coefficient est de 0,81 ; 0,85 ; 0,85 et 0,63 respectivement à Bada,
Marabadiassa, Tortiya et à Bou. Cela signifie que les relations entre
les débits mesurés et les débits calculés par le
modèle GR2M sont de type linéaire à toutes les stations
hydrométriques d'étude. Les coefficients de détermination
(r2) sont tous supérieurs à 60% sauf à la
station de Bou où il est égal à 42%.
L'interprétation à donner est que, les relations entre les
débits mesurés et les débits simulés par le
modèle GR2M étant de type linéaire, les modèles
mathématiques Qs = a.
Qm + b peuvent expliquer à eux seuls en
validation : 68%, 74%, 75%
et 42% des variabilités observées et les 32%,
26%, 25% et 58% restants représentent les erreurs de mesures et toutes
les imprécisions engendrées lors de l'optimisation du
modèle respectivement pour les stations de Bada, Marabadiassa, Tortiya
et Bou. Les mauvais résultats enregistrés à la station de
Bou sont probablement liés à la qualité des données
hydroclimatiques de cette station. En effet, dans la deuxième partie de
ce mémoire, un contrôle des données hydrométriques
avait permis de détecter des légers changements de pente
lorsqu'on compare les débits de la station de Bou à ceux des
stations de Bada et de Tortiya. Ces changements de pentes traduisent souvent
des irrégularités dans les différentes séries de
données comme c'est peut être le cas des données de la
station de Bou. On remarque que le modèle global conceptuel GR2M est
plus performant en calage qu'en validation sauf à
la station de Marabadiassa où l'on ne fait pas cette
observation. Les travaux de Tarik (2006) ont permis d'aboutir à ce
même type de résultats sur les bassins versants de Cheffia,
Lakhdaria, La Traille, Sebbaou et Tafoura en Algérie. Le modèle
GR2M est instable à Bou et à Marabadiassa. On observe une
dégradation de la performance de ce modèle à la station de
Bou et une amélioration de la performance du modèle à la
station de Marabadiassa. La station de Tortiya est la station où le
modèle GR2M est le plus performant avec des Nash en validation et en
calage supérieurs à 70%. Tout comme le modèle GR2M, les
modèles Perceptrons Multicouches Dirigés (PMCD)
développés au chapitre VII de ce mémoire présentent
de bonnes performances. En effet, l'ajout d'autres variables explicatives en
entrée du réseau et leur combinaison augmente
généralement le nombre de neurones cachés. En effet, en
ajoutant ces variables, on augmente la quantité de données
à traiter par le réseau. Or ce sont les neurones de la couche
cachée qui font le traitement. Il s'en suit que pour plus de
données à traiter, il faut au réseau plus de neurones dans
la couche cachée. Dans le cas contraire il fallait ajouter d'autres
couches cachées. Or on sait que le perceptron multicouche à une
seule couche cachée est capable de résoudre les problèmes
de modélisation hydrologique (Hornik, 1991). L'ajout des variables
explicatives (Température, évapotranspiration potentielle et
mois) et de leur combinaison a amélioré les performances des
modèles Perceptrons Multicouches Dirigés aux stations de Bada,
Marabadiassa et de Tortiya et a dégradé celles de la station de
Bou. En effet, les variables ajoutées expriment certaines pertes d'eau
au niveau du bassin versant d'étude. Ce sont des informations
complémentaires qu'on apporte aux réseaux de neurones pour leurs
permettre de simuler correctement les débits aux différentes
stations d'étude. Normalement, leurs ajouts en entrée devraient
améliorer les performances des modèles à toutes les
stations. Mais, à la station de Bou, compte tenu des
irrégularités constatées au niveau des données
hydrométriques, leur ajout a au contraire, provoqué la
dégradation des performances des modèles
développés. Parmi ces station, c'est la station de Tortiya qui
offre les meilleures performances des modèles jusqu'à 80% pour le
critère de Nash quelque soient les variables considérées
en entrée. En effet, les coefficients d'inter corrélation entres
les autres variables et le débit à la station de Tortiya sont
plus élevés que ceux calculés sur les autres stations. Les
résultats obtenus avec les modèles Perceptrons Multicouches
Dirigés étaient forts satisfaisants et sont différents de
ceux obtenus par Tarik (2006). Les résultats obtenus par cet auteur avec
le réseau de neurones à une seule couche cachée comportant
quatre neurones sont résumés dans le tableau
XXI. Cet auteur a attribué ces résultats non
satisfaisants au type d'apprentissage en block (batch training) et il a conclu
que l'utilisation des réseaux de neurones en block, soit au pas de temps
mensuel ou journalier,
n'est pas adaptée à la modélisation
pluie-débit qui est un processus se calculant en temps réel. Il
faut ajouter à cette justification le nombre réduit de
données utilisé en calage et en validation par Tarik (2006) et la
qualité des données hydroclimatiques utilisées. Les
résultats obtenus dans ce travail de recherche semblent bien meilleurs
que ceux de Tarik (2006) grâce notamment au calage qui a
été réalisé sur 18 ans et la validation sur 7 ans.
On a donc pu présenter aux réseaux une large
variété de données afin de faciliter le processus
d'apprentissage qui est aussi un apprentissage en block ; ce qui n'est pas le
cas avec les 7 et 8 ans utilisés par Tarik (2006). Bien que les deux
zones d'étude soient différentes au niveau de leurs
géologies et de leurs hydrographies, cette comparaison a
néanmoins son sens dans la mesure où les deux études
s'intéressent à la modélisation pluie-débit au pas
de temps mensuel à l'aide des Réseaux de neurones avec
l'apprentissage en block.
Tableau XXI : Résumé des
performances obtenues avec Tarik (2006).
|
Station
hydrométrique
|
Cheffia
|
Lakhdaria
|
La Traille
|
Sebbaou
|
Tafia
|
|
Période de
Calage
|
(1978-1984)
|
(1980-1987)
|
(1970-1977)
|
(1980-1987)
|
(1980-1987)
|
|
Nombre
d'année
|
7 ans
|
8 ans
|
8 ans
|
8 ans
|
8 ans
|
|
Nash (%)
|
63,9
|
45,6
|
61,4
|
41,8
|
-1,0
|
|
Validation
|
Cheffia
|
Lakhdaria
|
La Traille
|
Sebbaou
|
Tafia
|
|
Période de
validation
|
(1985-1991)
|
(1988-1995)
|
(1979-1985)
|
(1988-1995)
|
(1988-1995)
|
|
Nombre
d'année
|
7 ans
|
8 ans
|
7 ans
|
8 ans
|
8 ans
|
|
Nash (%)
|
41,9
|
45,5
|
41,5
|
41,9
|
5,0
|
En plus d'être plus performants, les Réseaux de
neurones Formels (RNF) seraient économiquement plus rentables que le
modèle conceptuel global GR2M. En effet, avec seulement la pluie en
entrée, le modèle PMCD1S apparaît plus performant que le
modèle GR2M qui intègre à la fois la pluie et
l'évapotranspiration en entrée. En ajoutant
l'évapotranspiration à la pluie pour obtenir le modèle
PMCD3S, la performance du modèle s'améliore davantage. Ce qui
veut dire que pour un résultat plus satisfaisant, le
modélisateur
dépense moins avec le modèle PMCD1S qu'avec le
modèle conceptuel global GR2M. Il serait alors moins coûteux pour
l'ingénieur d'utiliser le modèle PMCD1S que le modèle
GR2M. En effet, si on considère que le coût des
températures et des pluies mensuelles avec la SODEXAM est de 600 F CFA
l'unité et que les débits mensuels sont fournis gratuitement par
la Direction de l'eau (comme c'est le cas dans cette présente
étude), pour une simulation de débit mensuel sur une
période de 10 ans et sur 10 bassins versant, le modélisateur fera
un bénéfice de 720 000 F CFA. Le détail du calcul est
présenté comme suit :
Les résultats obtenus au niveau du dernier chapitre de
ce mémoire montrent que tous les modèles de prévision
expriment plus de 70% de la variation des débits du Bandama Blanc
à Tortiya. Pour tous les modèles, les Nash calculés sont
nettement supérieurs à 70% et les coefficients de
corrélation de Pearson sont très forts, supérieurs
à 0,80, et cela quelque soit la phase de développement
considérée (calage et validation). Ces très forts
coefficients de corrélation de Pearson montrent que les débits
mesurés et les débits prédits par les modèles de
prévisions (PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p, PMCD6p) sont
liés par des relations de type linéaire. Cette étude a
également montré que les coefficients de détermination
2
R sont tous supérieurs à 75% en calage
et supérieurs à 80% en validation. L'interprétation
donnée est que, les relations entre les débits mesurés et
les débits calculés par les modèles de prévision
étant de type linéaire, les modèles mathématiques
Q p = a. Qm + b
( Qp , débit prédit et
Qm , débit mesuré) peuvent expliquer à
eux seuls :
iii) en calage, 79%, 85%, 85%, 79%, 79% et 76% des
variabilités observées et les 21%, 15%, 15%, 21%, 21% et 24%
restants représentent les erreurs de mesures et toutes les
imprécisions engendrées lors de l'optimisation respectivement des
modèles de prévision PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p et
PMCD6p ;
iv) en validation, 82%, 83%, 85%, 82%, 82% et 84% des
variabilités observées et les 18%, 17%, 15%, 18%, 18% et 16%
restants représentent les erreurs de mesures et toutes les
imprécisions engendrées lors de l'optimisation respectivement des
modèles de prévision PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p et
PMCD6p.
Malgré ces bonnes performance tant en calage qu'en
validation, il faut cependant noter que les performances obtenues en validation
sont nettement supérieures à celles obtenues en calage quel que
soit le modèle de prévision et le critère de performance
considéré. Cette situation pourrait simplement s'expliquer par le
fait que, la base d'apprentissage (18 ans)
contient plus de débits extrêmes (débits
de crue et débit d'étiage) que la base de validation (9 ans). En
effet, les études effectuées dans ce chapitre ont montré
que les débits extrêmes étaient relativement mal
calculés par les Perceptrons Multicouches de prévision. Les
débits de pointes extrêmes sont tous sous estimés.
En effet, les modèles de prévision sous estiment
à au moins 2/3 les débits de pointes mesurés au mois de
septembre qui correspond au mois des débits de crues et les
débits d'étiages extrêmes sont quant à eux
surestimés par les modèles.
Pendant le calibrage de ces modèles de
prévision, on aura donc plus de débits mal calculés qu'en
phase de validation. Le calcul des critères de performance tel que le
critère de Nash sera donc fortement influencé par ces mauvais
débits qui auront tendance à agir sur la qualité de ce
critère. Pour améliorer les performances des modèles, les
critères de Nash sont recalculés avec cette fois ci la racine
carrée des débits et les résultats sont édifiants.
En effet, les valeurs de Nash ont été augmentées d'environ
trois unités. Cela a été possible ; car, en calculant le
critère de Nash sur les racines carrées des débits, on
accorde la même importance aux erreurs sur les forts débits. Les
critères de performance (Nash et coefficient de Pearson) en calage et en
validation sont du même ordre de grandeur quel que soit le critère
considéré. On peut donc dire que les différents
modèles de prévision (PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p,
PMCD6p) sont très robustes donc stables. Il est donc possible que ces
modèles développés puissent s'appliquer à d'autres
données qui n'ont pas participé au calage avec de très
bonnes performances. Des six modèles développés, les
modèles de prévision PMCD2p et PMCD3p donnent approximativement
les mêmes performances (critères de Nash, coefficient de
détermination et coefficient de corrélation de Pearson). Au vu
des valeurs de ces critères de performance, on se rend aussi compte que
ces modèles sont les meilleurs des modèles de prévision
développés. Les types de variables en entrée pourraient
expliquer ces résultats. En fait, le mois qui est la deuxième
variable explicative du modèle PMCD2p exprime également, sous une
autre forme, l'ETP qui est la deuxième variable explicative du
modèle PMCD3p. En effet, le codage du mois s'est effectué par
rapport aux valeurs moyennes mensuelles interannuelles des températures
qui ont aussi servi à calculer les évapotranspirations
potentielles. Les modèles PMCD2p et PMCD3p peuvent donc être
qualifiés de "modèles jumelles". Les meilleurs
résultats obtenus par ces modèles de prévisions sont le
fait que les combinaisons "pluie-ETP" et "pluie-mois" exprimeraient mieux la
dynamique du cycle de l'eau sur le bassin versant d'étude que les autres
combinaisons à savoir : pluie-température ;
pluie-température-mois et ; pluie-ETP-mois. Les modèles de
prévision reproduisent bien la dynamique des écoulements du
Bandama Blanc à la station hydrométrique de Tortiya. Et,
l'ajout des variables explicatives comme la
température, l'évapotranspiration et le mois ainsi que leurs
différentes combinaisons améliore la capacité des
modèles Perceptrons Multicouches à la prévision des
débits du Bandama Blanc à Tortiya. Cependant, quelques
décalages existent entre les hydrogrammes mesurés et
calculés à la station hydrométrique de Tortiya par les
modèles de prévision. Ces décalages pourraient être
le fait du nombre réduit de données utilisées pendant
l'apprentissage (18 mois) de ces modèles de prévision. En effet,
des études similaires ont montrées que, plus on dispose de
données pour l'apprentissage et plus les modèles arrivaient
à reproduire fidèlement les débits. Parmi ces
études, on peut citer celle de Wenrui et al., (2004) sur la
prévision des débits de la rivière Apalachicola (Floride,
USA) avec les Réseaux de neurones Artificiels. En effet, ces auteurs ont
fait la prévision des débits au pas de temps journalier, mensuel,
trimestriel et annuel avec des coefficients de corrélation de Pearson
respectives de 0,98 ; 0,95 ; 0,91 et 0,83. On remarque que plus le pas de temps
est petit, ce qui est équivalent à un nombre élevé
de données, les modèles de prévision
développés donnent de très bonnes valeurs du coefficient
de corrélation. Ces bonnes valeurs du coefficient de corrélation
de Pearson pourraient être en phase avec les hydrogrammes prédits
qui se rapprocheraient davantage des hydrogrammes mesurés.
|
|

