6.2.2 Traitement et analyse des données
Cette phase de l'étude a comporté les étapes
suivantes:
a. Classement et recodage
Les 56 questionnaires remplis et contrôlés
étaient classés dans l'ordre du questionnaire par
établissement, après contrôle d'exhaustivité, et
puis recodés de 1 à 56 pour effectuer la saisie.
b. Saisie
Nous avons élaboré les masques de saisie
à partir du logiciel EPIDATA ver3.1. Lequel logiciel permet de saisir,
analyser et organiser toutes les données quantitatives ou qualitatives,
qui ont été consignées sur questionnaire papier.
Nous avons effectué la saisie des données sur deux
microordinateurs.
Le taux d'erreur est réduit à zéro, du fait
de la saisie contrôlée, et ce grace aux fonctions de
contrôle de cohérence dont dispose EPIDATA
Figure 06 : Interface de EPIDATA

c. Apurement
Cette opération, utilisant toujours le programme
EpiData avait lieu en même temps que la saisie. . La simplicité de
sa programmation, a permis de mieux adapter les programmes informatiques pour
que l'on puisse avoir un fichier de données apuré et de meilleure
qualité.
d. Tabulation
Afin de structurer l'analyse des données , des tableaux
d'analyse ont été établis pour faciliter l'exploitation
des données issues des questionnaires malgré les
difficultés rencontrés principalement celles liées aux
formulation générales utilisées pour les questions
ouvertes.
e. Analyse
La stratégie utilisée pour mettre en oeuvre les
méthodes d'analyse est de respecter la situation d'incertitude de
départ et de ne pas imposer une méthode qui force les
résultats dans un sens ou un autre mais qui laisse émerger
d'éventuelles surprises. A cette fin le processus d'analyse sera
caractérisé par l'utilisation du concept de variable
d'intérêt : toute enquête est faite quand on est face
à un phénomène dont on veut rendre compte et cette
focalisation détermine une ou plusieurs "variables
d'intérêt" dont on veut rendre compte. On proposera donc une
première méthode qui consiste à repérer quelles
sont les questions de l'enquête qui sont le plus liées à
cette variable d'intérêt.
Une fois repérées les variables qui sont
liées au phénomène étudié, on utilisera une
méthode, l'analyse des correspondances, qui permettra de faire une
analyse globale du phénomène, c'est-à-dire qui
positionnera les différentes modalités de la variable
d'intérêt dans un univers de modalités suffisamment riche
pour que des hypothèses de travail puissent en être issues, mais
suffisamment limité pour que l'analyse ne soit pas submergée par
trop de données. Une fois cette vue d'ensemble établie, l'analyse
se focalisera sur des points précis qui demandent une investigation
complémentaire car l'analyse précédente, comme une carte
qui englobe un vaste territoire, est peu précise et trop incertaine. De
l'analyse globale, on passe à l'analyse locale, et de l'hypothèse
de travail à sa verification.
Quand on fait une enquête, quelque soit le nombre
d'individus, on veut légitimement avoir une description de la population
enquêtée et puisque l'effectif est faible, on ne pourra que
constater l'état de la population.
Il faut bien distinguer la description des données
d'une part, des résultats qui peuvent être
généralisés à l'ensemble de la population
étudiée d'autre part. Pour pouvoir généraliser on
utilisera des tests statistiques, essentiellement celui du khi-deux que l'on
supposera connu : on se souviendra que le khi-deux étant sensible aux
effectifs, dès qu'une population d'enquêtés devient
importante, il devient rare que le khi-deux d'un tableau croisé ne soit
pas significatif.
Sélection des questions pertinentes
Ce que nous voulons repérer, ce sont les questions qui
sont pertinentes par rapport à la variable d'intérêt de
notre enquête. Nous allons donc croiser systématiquement cette
variable d'intérêt avec toutes les autres questions de
l'enquête mais ne sélectionner que celles qui sont le plus en
attraction avec elle.
Utilisation de l'analyse en composantes
principales
L'analyse en composantes principales (A.C.P.) est une
méthode mathématique d'analyse graphique de données qui
consiste à rechercher les directions de l'espace qui représentent
le mieux les corrélations entre n variables aléatoires
(relation linéaire entre elles).
Simplement dit, une A.C.P. permet de trouver des similitudes de
comportement d'achat entre les classes des données observées.
Même si l'A.C.P. est majoritairement utilisée pour
visualiser des données, il ne faut pas oublier que c'est aussi un moyen
:
· De décorréler ces données. Dans la
nouvelle base, constituée des nouveaux axes, les points ont une
corrélation nulle (nous le démontrerons).
· De classifier ces données en amas (clusters)
corrélés (dans l'industrie c'est surtout cette possibilité
qui est intéressante!).
Lorsque nous ne considérons que deux effets, il est
usuel de caractériser leurs effets conjoints via le coefficient de
corrélation. Lorsque l'on se place en dimension deux, les points
disponibles (l'échantillon de points tirés suivant la loi
conjointe) peuvent être représentés sur un plan. Le
résultat d'une A.C.P. sur ce plan est de déterminer les deux axes
qui expliquent le mieux la dispersion des points disponibles.
Lorsqu'il y a plus de deux effets, par exemple trois effets,
il y a trois coefficients de corrélations à prendre en compte. La
question qui a donné naissance à l'A.C.P. est : comment avoir une
intuition rapide des effets conjoints?
En dimension plus grande que deux, une A.C.P. va toujours
déterminer les axes qui expliquent le mieux la dispersion du nuage des
points disponibles.
L'objectif de l'A.C.P. est de décrire graphiquement un
tableau de données d'individus avec leurs variables quantitatives de
grande taille.
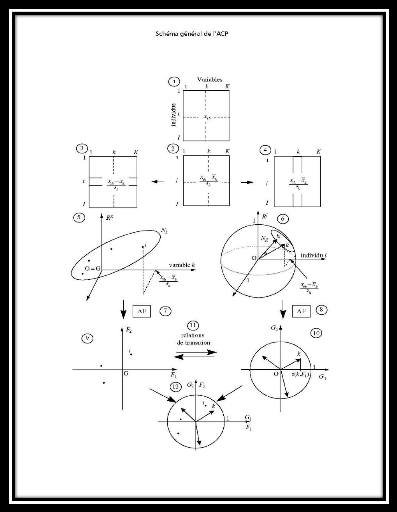
Figure 07 : Schéma général de l'ACP
| 
