II. L'observation d'internautes en recherche
d'informations
Deux protocoles d'observation sont définis : un pour
l'observation des adultes, un autre concernant les enfants. Certains enfants
étant très jeunes et sans expérience, un protocole
spécifique, plus léger est préférable.
Le protocole des adultes
Il est composé de cinq recherches (deux libres et trois
imposées) : Recherches imposées :
1 Un texte : les paroles de la chanson « All Blues »
2 La distance entre Toulouse et Rodez
3 Une partition de musique : la partition de l'hymne national
roumain
Recherches libres : L'adulte doit fournir deux sujets sur
lesquels il devra, autant que possible rechercher une réponse à
une question ou un document dans un format particulier.
Le protocole des enfants
Le protocole des enfants est composé de deux recherches
(une libre et une imposée) : Recherche imposée : La durée
de vie d'un dauphin.
Recherche libre : L'enfant doit fournir un sujet de recherche
sur lequel il devra, autant que possible, trouver une réponse à
une question ou un document dans un format particulier.
Mesures
Pour chacune des observations des marqueurs sont choisis. Ces
marqueurs ont essentiellement pour but de mesurer le sentiment global de
l'utilisateur et de nous permettre de rattacher ce sentiment à des
éléments mesurables. On recherche ainsi, par le typage des
difficultés rencontrées et des comportements, à mieux
comprendre quelles situations peuvent créer un sentiment d'échec
ou de stress.
II. L'observation d'internautes en recherche d'informations 11
Avant-propos
Cinq valeurs sont mesurées pour toutes les
observations.
|
Valeur mesurée pour
chaque
recherche
|
Règles
|
|
Le temps complet de l'observation
|
Ce temps comptabilisera seulement le temps (format h : min :
sec) de recherche effective pendant l'observation. Les temps de
présentation de la recherche et d'auto-notation ne sont donc pas
comptabilisés (En cas de dépassement notable (100%) du temps
maximal donné par l'utilisateur, l'observateur lui propose de mettre un
terme à la séance).
|
|
Le nombre de sites visités
|
On comptabilise le nombre de fois où l'internaute
clique sur un lien dans le moteur de recherche ou clique sur un lien dans un
site envoyant sur un autre site. Si le site à déjà
été visité préalablement il est quand même
comptabilisé.
|
|
Le nombre de requêtes
|
On comptabilise le nombre de fois où l'internaute
envoie une requête au moteur de recherche. Les requêtes
renvoyées plusieurs fois sont comptabilisées plusieurs fois.
|
|
Le nombre de pages consultées dans les moteurs de
recherche
|
On comptabilise le nombre de fois où l'internaute
demande à afficher les sites retournés par le moteur de
recherche.
|
|
Si l'information, le document ou la réponse à la
question recherchée ont été trouvés
|
Valeurs possibles :
? oui,
? certains éléments ++,
? certains éléments --,
? non.
|
Quatre marqueurs sont enregistrés pour chaque
requête effectuée pendant l'observation.
|
Marqueurs enregistrés pour
chaque
requête
|
Explication
|
|
Les mots clés utilisés
|
La requête est archivée à l'identique, les
fautes d'orthographe et les caractères spéciaux sont
conservés.
|
|
Le nombre de mots clés utilisés
|
Chaque mot est comptabilisé. Les expressions entre
guillemets sont comptabilisées comme mots-clés.
|
|
Le nombre de sites « retournés »
|
On note le nombre de sites théoriques retournés
par le moteur de recherche. C'est en fait le nombre de sites affiché
comme le nombre de sites trouvés sur internet pour cette
requête.
|
|
Le caractère multi-langue des mots clés
utilisés
|
Si une requête contient des mots de langues
différentes elle est notée comme une requête
multi-langues.
|
Pour chacune des observations (résolues ou pas) le
sujet s'exprimera sur 5 caractéristiques subjectives qu'il notera de 0
à 10 : 0 signifiant « très mauvais », 10 «
excellent ».
|
Objet de l'auto-notation
|
Explication
|
|
Capacité à comprendre l'information
|
Ressenti sur la clarté des documents parcourus.
|
|
Intérêt des sites rencontrés
|
Ressenti sur la qualité informative des documents.
|
|
Longueur subjective de la recherche
|
Ressenti du temps passé sur Internet.
|
|
Ressenti général
|
Ressenti sur le plaisir éprouvé à surfer sur
le Web.
|
En cas de blocage ou de découragement, si le temps
maximum donné par l'utilisateur n'est pas dépassé,
l'intervention d'une tierce personne est possible de façon à ne
pas arrêter l'expérience. Ces interventions qui ont le plus
souvent pour but de guider l'utilisateur (replacer un utilisateur dans un
moteur de recherche, lui apprendre la notion de lien hyper texte,
répondre à une question technique, ...) sont toutes
notifiées.
II. L'observation d'internautes en recherche d'informations 12
Avant-propos
Résultats et exploitation
Les difficultés rencontrées par les utilisateurs
se situent au niveau de chacune des tâches élémentaires qui
composent la tâche globale de recherche d'information sur le Web. Ces
difficultés sont principalement de quatre ordres :
? Trouver les mots-clés efficaces
? Faire un choix dans une liste longue et
hétérogène
? Extraire de l'information des sites web proposés
? Gérer le temps (temps réel de recherche et de
perception)
Ces difficultés sont détaillées dans les
sections qui suivent.
Difficultés pour trouver des mots-clés
efficaces
Avec un nombre moyen de 7 millions de sites Web trouvés
par recherche, nous pouvons certifier que les 3,44 mots-clés
employés dans les requêtes ne sont pas assez efficaces pour
filtrer le Web. Les utilisateurs ont des difficultés pour employer
davantage de mots-clés et pour choisir ces mots. Lorsqu'ils le font,
cela devient même contre-productif : le taux de satisfaction
décroît. Cet état de fait provient d'un problème de
compétences des utilisateurs sur la nature même de la recherche.
En effet, en général les utilisateurs ne connaissent pas assez le
sujet pour enrichir la demande. Ceci provient également d'un
mélange entre atonie et manque de compétence sur le
fonctionnement du moteur de recherche. Le moteur de recherche est un outil avec
lequel l'interaction est limitée. On l'interroge et comme par magie, la
réponse est retournée. D'autre part, l'utilisateur ne manie pas
de mots dans une langue inconnue, par exemple, pour rechercher de l'information
sur la musique roumaine, personne n'a employé de mots-clés
roumains (même si des outils de traduction étaient connus). Un
seul des utilisateurs observés (Jean), a utilisé des mots de la
chanson anglaise à retrouver. Bilingue, il a su mélanger le
français et l'anglais. Ainsi on peut remarquer que l'utilisateur choisit
les mots-clés de sa requête en fonction de sa connaissance du
sujet et de sa connaissance du moteur de recherche utilisé. Il faut
également prendre en considération que les mots-clés
peuvent être mal orthographiés. De fait, les jeunes utilisent de
plus en plus le langage SMS. On a pu observer lors des expérimentations
que les enfants trouvaient (par erreur ?) l'information en formulant leurs
requêtes en langage SMS.
Difficultés pour faire un choix dans une liste
longue et hétérogène
La liste des informations retournées par un moteur de
recherche en réponse à une requête comprend un certain
nombre d'éléments. Avec Google, par exemple, comme le montre la
figure AVP.1, chaque item de la liste retournée intègre :
? Le titre du site. Mais comme tous les sites n'ont
pas un titre, dans ce cas, les moteurs, comme Google, utilisent d'autres
métadonnées (metatags) telles que
II. L'observation d'internautes en recherche d'informations 13
Avant-propos
le titre de la page, l'auteur, l'URL,... pour construire une
sorte de titre. De plus, lorsque ce titre est trop long, il est
tronqué.
· Un extrait (« snippet »). Il s'agit
en fait de bouts de phrases (quelques mots), entourant les mots-clés,
extraits du site. L'extrait constitué en assemblant ces bouts de phrases
n'a globalement pas de sens.
· L' URL (Uniform Resource Locator) de la page ou
du site.
On peut facilement imaginer un débutant
déstabilisé face à une telle liste. Par exemple, Annie, 70
ans, a soumis à Google la requête suivante « Natura 2000
marais de Gabarret » où « Natura 2000 » est une
organisation écologiste française et Gabarret est un petit
village français. Elle a obtenu la réponse suivante...
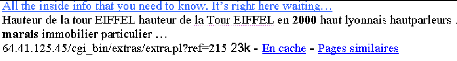
Figure AVP. 1 : Snippet et Information d'un site
retourné par Google dans une liste de résultats.
Le titre est en anglais, l'extrait est en français et
parle de la Tour Eiffel, l'URL est une adresse IP (Internet Protocol).
Difficultés pour extraire de l'information des
sites web proposés
A partir d'une page HTML : il est difficile
pour les utilisateurs d'extraire l'information présente dans la page.
Tous les utilisateurs peuvent « rater » des informations sur une
page. Ceci pour plusieurs raisons :
· ils cessent de lire la page avant que l'information
« pertinente », ou du moins intéressante, ait
été atteinte, la page leur paraît trop longue ;
· ils ne lisent que la partie affichée de la page
(effet fenêtre) ;
· la page est trop chargée, comme par exemple par
une présence excessive de publicité ;
· Ils confondent pages retournées et moteur de
recherche. Ils utilisent une fonction de recherche sur un site (Quid,
Amazon...) au lieu d'utiliser le moteur de recherche choisi ;
· ils « tournent en rond sur un document », le
scénario est alors le suivant : l'utilisateur fait défiler un
document, il trouve un lien qui pointe en réalité sur ce
même document clique et recommence l'opération (cela peut se
produite quatre ou cinq fois sans que l'utilisateur ne remarque que le document
parcouru est toujours le même) ;
II. L'observation d'internautes en recherche d'informations 14
Avant-propos
? ils cessent de lire si la page ou une partie de cette page
est dans une langue inconnue.
À partir d'un fichier : l'information
à extraire peut se trouver dans un fichier et non dans une page Web. Il
faut alors savoir exploiter ce fichier, qu'il s'agisse d'une image (comme pour
les partitions musicales par exemple) ou de tout autre type de fichier. Par
exemple, Jean recherchait une partition de musique ; il a trouvé un
fichier MIDI (son). Mais il ne savait pas qu'il était possible
d'extraire la partition à partir d'un fichier MIDI (Musical Instrument
Digital Interface) et a abandonné déçu.
Difficultés pour gérer le temps de
recherche et sa perception
La majorité des utilisateurs a déclaré
que le temps passé sur une recherche n'excédait pas 15 minutes.
Or il se trouve que le temps moyen calculé pour une recherche, est de 18
minutes et 45 secondes. De plus, 50% des recherches ont largement
dépassé les 15 minutes (Annie cherchera 1 heure 5 minutes et 30
secondes la partition de l'hymne national roumain). Si le temps consacré
à la recherche est moins important que le succès ou
l'échec dans l'attribution de la note générale moyenne,
au-delà de 15 minutes, l'appréciation fait
systématiquement apparaître une certaine déception
(seulement 5,5/10).
| 

