II. Un exemple à trois variables
explicatives
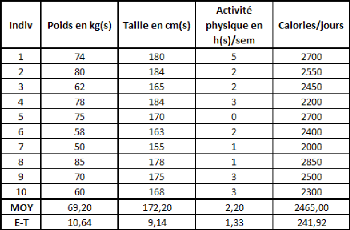
Reprenons le même exemple mais en ajoutant deux
séries fictives supplémentaires (qui seront utilisées
comme variables explicatives supplémentaires) :
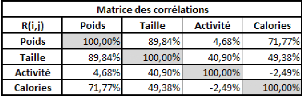
La matrice des corrélations correspondantes est la
suivante :
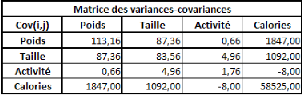
Et la matrice des variances-covariances :
Ces séries supplémentaires ont volontairement
été créées de manière à diminuer les
résidus, c'est-à-dire à améliorer le pouvoir
explicatif du modèle, même si une part aléatoire a
été volontairement conservée. Les 5 séries
étant purement fictives, il sera inutile d'appliquer quelque
modèle que ce soit, qui soit fondé sur ces séries,
à la réalité.
Effectuons tout d'abord une régression linéaire
simple sur ce modèle. Avec Eviews 5.0, on obtient :
- En travaillant sur les données non-centrées et
non-réduites et avec intégration
d'une constante :
Poids = 1.039*Taille
-- 2.5*Activité +
0.012*Calories -- 133.426. Les 4 coefficients sont
jugés significatifs au seuil de 1%, ce qui est plutôt
étrange quand on regarde la corrélation Poids/Activité
(corrélation apparemment très faible). Le signe du coefficient
« Activité » est également surprenant, à priori,
étant donné qu'il est opposé à celui du coefficient
de corrélation Poids/Activité.
On obtient un coefficient de détermination de la
régression de 98,08%.
- En travaillant sur les données
centrées-réduites :
Poidscr = 0.893*Taillecr --
0.296*Activitécr + 0.255*Caloriescr
Le coefficient de détermination est toujours de 98,08%.
Les 3 coefficients sont jugés significatifs au seuil de 1%.
- Si on travaille sur les données
initiales sans constante, on obtient la relation :
Poids = 0.221*Taille - 0.603*Activité + 0.013*Calories.
Cette fois, le coefficient de corrélation n'est plus que de 58,81%, et
aucun coefficient n'est significatif au seuil de 1% (le coefficient
associé à la variable Activité n'est pas non plus
significatif au seuil de 5%, ce qui n'est toutefois pas le cas des autres). On
comprend donc ici tout l'intérêt d'intégrer une constante
dans la régression ou de centrer les données (la réduction
n'importe pas).
Effectuons à présent une régression PLS
univariée sur le modèle en question : II.1.
Régression PLS à 1 étape
- Modèle normal :
Poids = 0.694*Taille + 0.249*Activité +
0.021*Calories -- 102.603 - Modèle centré-réduit
:
Poidscr = 0.597*Taillecr +
0.031*Activitécr + 0.477*Caloriescr
Le coefficient de détermination (R2) de la
régression de Y sur t1 est de 87,97%. On ne peut donc pas dire qu'il
soit identique à celui de la régression multiple, puisqu'il lui
est inférieur.
A la vue de ce premier modèle, on peut dors et
déjà tirer quelques conclusions, et on peut se poser plusieurs
questions :
- Le coefficient de régression est inférieur
à celui de la régression linéaire simple. La
régression PLS serait-elle une méthode moins efficace que la
régression linéaire simple ?
- Les coefficients affectés aux différentes
variables ne sont pas du tout les mêmes d'un modèle à
l'autre. Parfois même, on observe un changement de signe : c'est le cas
pour la variable Activité. La régression PLS serait-elle plus
« objective » que ne l'est la régression linéaire
simple ?
- On constate cette fois que la variable Activité observe
un coefficient de signe similaire à son coefficient de
corrélation avec la variable poids.
- Les deux derniers points découlent directement du
fait que les variables étant centrées, et n'ayant retenu qu'une
seule étape, les coefficients sont directement proportionnels aux
coefficients de corrélation des différentes variables
explicatives par rapport à la variable Poids.
Comparons les deux modèles (non-centrés,
non-réduits, avec constante) en utilisant leurs prévisions des
valeurs de la variable expliquée (Poids) :
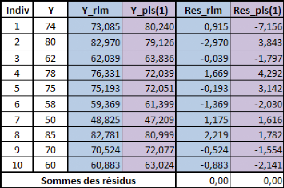
Y correspond à la variable Poids (variable
expliquée)pour les 10 individus.
Y_rlm correspond à la prédiction de la variable
Poids pour les mêmes individus par le modèle de régression
linéaire simple, Res_rlm correspond aux résidus de cette
régression.
Y_pls(1) correspond à la prédiction de la
variable Poids pour les mêmes individus par le modèle de
régression PLS1 à une étape, la colonne Res_pls(1)
correspondant aux résidus.
SCT (somme des carré totale, c'est la somme des
carrés des écarts à la moyenne de Y) = 1131.6 SCR_rlm
(somme des carrés résidus pour la régression
linéaire multiple) = 21.715 SCR_pls(1) (somme des carrés
résidus pour la régression PLS à une étape) =
114.402
Partie 2 : Utilisation de la régression PLS sur des
cas limites Plusieurs remarques :
- La somme des résidus (sans les élever au
carré) de la régression multiple est égale à 0, car
les résidus s'annulent, et c'est également le cas de la
régression PLS à une étape.
- La somme du carré des résidus de la
régression PLS(1)6 est très nettement
supérieure à celle de la régression linéaire
simple. Cela ne nous apprend rien, puisque le coefficient de la
régression PLS(1) était nettement inférieur à celui
de la régression multiple.
- La prévision de la régression PLS(1) n'est
meilleure que dans le cas du 8ème individu. -
Généralement, les erreurs de prévisions vont dans le
même sens, exception faite des individus 1, 2 et 5.
- Les écarts de prévisions (entre les deux
méthodes) les plus marqués (en valeur absolue) concernant les
individus 1, 2, 4 et 5, plus particulièrement l'individu n°1 et
l'individu n°2. L'individu n°1 est très mal prédit par
le modèle PLS(1).
Ceci étant dit, passons à la régression PLS
à 2 étapes. II.2. Régression PLS à 2
étapes
- Modèle normal :
Poids = 0.844*Taille + -2.225*Activité +
0.019*Calories -- 119.039 - Modèle centré-réduit
:
Poidscr= 0.725*Taillecr
+ -0.277*Activitécr +
0.442*Caloriescr
Le coefficient de la régression passe de 87,97%
à 95,52%. La part de la variance expliquée par t1 est de 87,97%
(normal, puisque t1 n'a pas changé) et celle expliquée par t2 est
de 7,55% (on l'obtient directement par différence, les composantes
étant indépendantes).
Plusieurs conclusions s'imposent :
- Les coefficients sont tous modifiés, tous de
manière assez importante, exception faite du coefficient lié
à la variable Calories.
- Les coefficients se rapprochent tous de leur valeur en
régression linéaire multiple. Exemple : dans le modèle
normal, le coefficient lié à la variable Taille passe de 0.694
à 0.844 et se rapproche ainsi fortement du coefficient de la
régression linéaire (1.039). La différence la plus
flagrante concerne le coefficient lié à la variable
Activité. Il était de 0.249 dans le modèle normal PLS(1),
il est maintenant de -2.225 dans le modèle normal
6 Les notations PLS(1), PLS(2), ... PLS(p) seront
couramment utilisées pour désigner respectivement les
modèles PLS à 1, 2, ..., p étape(s). Il est important de
ne pas les confondre avec les notations PLS1 et PLS2, désignant
respectivement des modèles de régression PLS univariée et
multivariée.
PLS(2). Il s'est considérablement rapproché de la
valeur du modèle de régression linéaire (-2.5).
- Ce dernier coefficient, justement, a changé de signe,
et n'est donc plus du même signe que le coefficient de corrélation
Poids/Activité. Son ordre de grandeur est également
significativement modifié. Il était très faible, notamment
s'agissant du modèle centré-réduit. Il possède
à présent un ordre de grandeur qui se chiffre en dixième,
à l'instar des coefficients des autres variables. Pourtant, si on
regarde les coefficients de corrélation, le coefficient de la variable
Activité devrait rester insignifiant en comparaison aux autres. Comment
ceci peut-il s'interpréter ?
- La qualité de la régression s'est nettement
améliorée, tendant subitement vers celle de la régression
linéaire simple, bien qu'elle lui reste inférieure.
Afin de mieux se rendre compte de l'amélioration de la
qualité de la régression,
reprenons le précédent
tableau et ajoutons-y les prédictions et les résidus du
modèle
PLS (2)
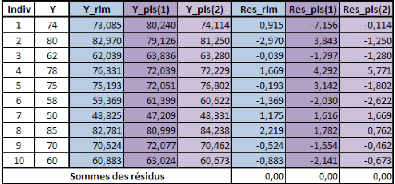
Ce que l'on peut remarquer :
- La somme des carrés des résidus
s'élève à 50.669 pour le modèle PLS(2), ce qui est
nettement inférieur à ce qu'il en était à
l'étape 1 (114.402), et qui se rapproche de ce que l'on observe
s'agissant de la régression linéaire (21.715).
- Les erreurs d'estimation les plus fortes concernent les
individus 4, et 6, plus particulièrement l'individu 4. Ces erreurs
tendent même à s'aggraver, alors que dans tous les autres cas,
elles diminuent (exception faite de l'individu 7 pour lequel la
prévision reste stable). On pourrait penser que le modèle PLS(2)
ignore « volontairement » l'individu n°4, car si on
l'enlève de l'analyse, la somme des résidus tendrait vers une
valeur plus faible.
- De plus, si on enlevait l'individu 4 de l'analyse, la somme
des résidus au carré (SCR)
plongerait de 50.669 à
17.367. La somme des résidus au carré du modèle de
régression
linéaire passerait quant à elle de 21.715
à 18.929, soit une sensibilité nettement plus
faible (ce qui est normal, l'individu 4 est nettement mieux
prédit par le modèle de régression linéaire). Le
modèle PLS(2) serait alors meilleur prédicateur des valeurs
actives que le modèle de régression linéaire. La
régression PLS pourrait-elle donc être une analyse plus pertinente
que la régression linéaire simple, exception faite de certains
individus ?
- Seul l'individu 1 fait l'objet d'une opposition du signe des
résidus. En revanche, les individus 2 et 5, qui faisaient l'objet d'un
désaccord de signe à l'étape 1, ne le font plus à
l'étape 2 (le désaccord restant néanmoins assez
prononcé en valeur absolue).
Il est très intéressant de noter que si on pratique
une régression linéaire simple en enlevant le
4ème individu de l'analyse, on obtient les résultats
suivants :
- Modèle normal avec constante :
Poids = 0.878*Taille -- 2.265*Activité + 0.017*Calories --
120.171 - Modèle centré-réduit :
Poidscr = 0.708*Taillecr -- 0.288*Activitécr +
0.381*Caloriescr
Le coefficient de détermination passe à 98.78%.
La somme du carré des résidus passerait de 21.715
à 12.74, pour seulement un individu (sur 10) ôté.
On remarque que les coefficients se rapprochent très
nettement de leur valeur calculée par le modèle PLS(2).
Ceci nous amène à une double conclusion :
- Le retrait de l'individu 4 des individus actifs
améliore sensiblement la qualité de l'analyse. Bien que
l'individu 4 était assez bien prédit par la régression
linéaire, son retrait a permit de « relâcher » la
régression, au sens où la prise en compte forcée de cet
individu atypique empêchait le modèle de prédire
correctement certains des autres individus.
Partie 2 : Utilisation de la régression PLS sur des
cas limites Le tableau suivant illustre ce phénomène :
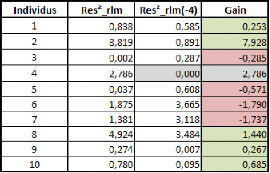
Res2 rlm représente la série des résidus
au carré de la régression linéaire pour chaque
individu.
Res2 rlm(-4) représente cette même
série pour la régression linéaire avec le
4ème individu ôté de l'analyse. La colonne «gain
» représente le gain apporté par le retrait du
4ème individu dans l'analyse en termes de résidu au
carré Il se calcule par soustraction suivante : Res2 rlm - Res2
rlm(-4).
Globalement, on observe un gain sur le critère des MCO
de 8.975 (21.715 -- 12.74). Ce gain est expliqué à 31% par la
disparition du résidu lié au 4ème individu, et
à 69% par l'amélioration des prédictions des autres
individus.
On note néanmoins que c'est l'individu 2 qui profite au
mieux de ce retrait, et que les individus 3, 5, 6 et 7 sont à
présent moins bien estimés. On peut donc penser que l'individu 2
et l'individu 4 sont dans une certaine mesure opposés car ils ne
s'analysent pas de la même manière, étant donné que
la prise en compte de l'individu 4 fausse énormément la
prédiction de l'individu 2.
- L'analyse se rapproche de celle établie par la
régression PLS à l'étape 2. Les coefficients se
rapprochent de ceux du modèle PLS(2). Cela nous confirme, dans une
certaine mesure, que le modèle PLS(2) a négligé l'individu
n°4, et que d'une certaine manière, c'est un point positif, puisque
ce dernier faussait les prévisions des autres individus.
Néanmoins, il est important de signaler que si le
retrait de l'individu 4 fait passer le R2 de la régression
linéaire de 98.08% à 98.78%, le retrait de l'individu 2 (en
laissant l'individu 4) fait passer le R2 de la régression de
98.08% à 99,2%, ce qui serait encore plus significatif.
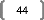
Le tableau suivant résume les différents
coefficients de corrélation (en régression linéaire)
résultant du retrait de chaque individu :
On remarque que 4 individus (les individus 3, 6, 7 et 10)
n'ont pas intérêt à être retirés en termes de
R2. Leur retrait détériorerait la qualité de la
régression. Ces 4 individus présentent très probablement
des caractéristiques « dans la moyenne » des autres. Les
retirer ne ferait que mettre encore plus en évidence le caractère
inconciliable de l'analyse des autres individus. Cela ne modifierait pas outre
mesure les coefficients, mais rendrait la qualité de la
régression plus mauvaise.
Note : Il n'est pas inconcevable que le retrait d'un
individu altère le coefficient de régression. Normalement, cela
devrait l'améliorer, car moins il y a d'individu, plus il est possible
d'ajuster les coefficients des variables afin d'expliquer les autres. C'est
particulièrement le cas lorsqu'il y a presque autant de variables
explicatives que d'individus. Néanmoins, si l'individu est bien
prédit par le modèle, son retrait risque de réduire
très peu la somme des carrés résiduels, et de
réduire fortement la somme des carrés totale. Si le terme SCR
diminue moins, en proportions, que le terme SCT, la qualité de la
régression se détériorera.
En revanche, les individus dont le retrait améliorerait
significativement la qualité de l'analyse sont les individus 2, 4 et 8.
On peut penser qu'ils sont quelques peu atypiques, et, de ce fait, «
tirent » vers eux l'analyse, influençant ainsi fortement les
coefficients.
Il serait difficile d'aller plus loin dans l'analyse, dans la
mesure où l'on ne dispose pas d'une population sur laquelle on puisse
tester les différents modèles, et ainsi s'apercevoir de la
qualité des différents individus actifs.
Passons donc à la régression PLS à 3
étapes.
Partie 2 : Utilisation de la régression PLS sur des
cas limites II.3. Régression PLS à 3
étapes
Les deux modèles sont les mêmes qu'en
régression linéaire simple :
- Poids = 1.039*Taille -- 2.5*Activité +
0.012*Calories -- 133.426 pour le modèle non centré,
non-réduit.
- Poidscr = 0.893*Taillecr -- 0.296*Activitécr +
0.255*Caloriescr pour le modèle centré réduit.
Toutes les statistiques associées sont donc similaires.
La troisième composante apporte un gain de 2.56% et porte donc le
coefficient de corrélation à 98.08%, comme dans la
régression linéaire simple.
Il est inutile de calculer les valeurs de Y ainsi que les
résidus, puisqu'ils sont nécessairement les mêmes qu'en
régression linéaire.
La seule chose que nous pouvons conclure est la convergence de
la régression linéaire simple et de la régression PLS
à 3 étapes, soit quand on retient autant d'étapes que de
variables explicatives (le maximum d'étapes possibles). Il est inutile
de tenter d'exploiter les résidus de l'étape 3 pour une
4ème étape, cela n'apporterait aucun gain, ces
résidus n'étant plus du tout corrélés, la
4ème composante serait nulle, ainsi que toutes celles qui
suivraient.
Dans ces conditions, si on considère la dernière
étape possible comme étant la version la plus aboutie de la
régression PLS, quel peut-être l'apport de la régression
PLS par rapport à la régression linéaire simple, si les
résultats sont les mêmes ?
Conclusions sur cette régression à 3 variables
explicatives :
Nous allons essayer de synthétiser tout ce que nous avons
observé au cours des 3 étapes, et nous tâcherons ensuite
d'expliquer point par point ce qui a aboutit à ces résultats.
Au cours de cette régression, nous avons observé
plusieurs choses :
- La régression linéaire simple est celle qui
obtient les meilleurs résultats en termes de coefficient de
régression et donc de SCR sur l'ensemble des individus actifs.
- En régression linéaire simple, comme en
régression PLS (à quelque étape que ce soit),
résidus positifs et négatifs se compensent parfaitement.
- La qualité, en termes de R2 et de SCR, de la
régression PLS, s'améliore d'étape en étape.
- L'ordre de grandeur des différents coefficients peut
fortement varier d'une étape à
une autre, ainsi que leur
signe. Dans un premier temps, lors du modèle PLS(1), ces
coefficients
sont strictement proportionnels aux corrélations entre la variable
expliquée
et les différentes variables explicatives. Ensuite, les
résultats se rapprochent progressivement de ceux trouvés à
l'aide de la régression linéaire.
- De manière générale, on observe une
convergence de la régression PLS vers la régression
linéaire simple lorsque le nombre d'étapes augmente, pour obtenir
des résultats égaux lorsqu'il y a autant d'étapes que de
variables.
- Selon le modèle PLS(1), la relation
Poids/Activité est positive, ce qui n'est pas le cas dans les autres
modèles.
- De manière générale, les résidus
ont tendance à aller dans le même sens s'agissant des trois
modèles calculés, exception faite de quelques individus.
- Le modèle PLS(2) voit ses coefficients se rapprocher
de ceux de la régression linéaire simple (par opposition au
modèle PLS(1)), pratiquement dans tous les domaines (coefficients,
coefficient de corrélation, résidus, ...). Le modèle
PLS(2) semble donc être une sorte de compromis entre le modèle
PLS(1) et le modèle de régression linéaire (ou
modèle PLS(3)).
- Dans un premier temps, les résidus de la
régression PLS(1) sont nettement plus élevés que ceux de
la régression linéaire. A la première étape, la
régression PLS est un beaucoup plus mauvais prédicateur (en terme
de résidus) que ne l'est la régression linéaire,
concernant tous les individus, exception faite du 2ème
individu.
- Si on enlève l'individu n°4, les
résultats de la régression PLS(2) sont nettement meilleurs et on
observe qu'ils surpassent ceux de la régression linéaire
(calculée sur les 10 individus actifs, ce n'est bien entendu plus le cas
si on enlève l'individu 4 de l'analyse, puisque la régression
linéaire est celle qui, par définition, minimise la somme des
carrés des résidus). L'individu 4 est donc probablement vu comme
un individu atypique, que la régression PLS(2) a jugé bon de
négliger.
- Nous avons vu que l'individu 4 s'oppose à l'individu
2. Si la régression PLS(2) a choisi de le négliger, ce n'est pas
le cas de la régression linéaire, qui, au contraire, laisse un
peu plus de coté l'individu 2. On a donc constaté que l'exclusion
de l'individu 2 de la régression permettait une nette
amélioration des résultats selon le critère des MCO.
Plusieurs phénomènes permettent en
réalité d'expliquer ou de résumer ces conclusions :
- Le modèle de régression linéaire est par
définition celui qui obtient le meilleur résultat par rapport
à son propre critère.
- La régression PLS est une forme de
généralisation de la régression linéaire simple ou
multiple.
- La régression PLS, dans sa première
étape, et, dans une moindre mesure, dans les quelques étapes qui
suivent (en cas de grand nombre d'étapes), prend avant tout en compte
les corrélations simples entre les variables, alors que la
régression linéaire va au-delà de ce simple
critère.
Nous allons donc nous attarder sur ces trois points.
III. La régression linéaire et
critèredesmoindrescarrésle
Bien sûr, la régression linéaire au sens
des MCO n'est pas le sujet du mémoire. Néanmoins, il est bon de
savoir qu'il est impossible d'obtenir, via un modèle linéaire, un
meilleur résultat en termes de SCR que celui obtenu par la
régression linéaire, puisque c'est le critère sur lequel
se fonde cette méthode.
On peut éventuellement trouver un meilleur
modèle, mais seulement sous une forme qui ne soit pas linéaire.
Ce n'est pas le cas de la régression PLS, qui est elle aussi un
modèle linéaire.
La régression PLS ne peut donc, en aucun cas, toute
chose égale par ailleurs, fournir un modèle qui soit un meilleur
prédicateur de l'ensemble des variables actives en termes de SCR,
que celui fourni par la régression linéaire simple ou
multiple.
Le résultat peut au mieux égaler celui obtenu
par la régression linéaire simple, notamment en utilisant le
nombre maximal d'étapes, ce qui n'est pas l'intérêt initial
de la méthode.
| 

