PLAN D'ANALYSE
Il s'agit à ce niveau décrire la méthode
d'analyse. Cette démarche d'analyse s'est orientée vers la
détermination des facteurs influençant la survenance des
accidents du travail dans les entreprises en Côte d'Ivoire parmi les
caractéristiques individuelles, socio-professionnnelles du travailleur
et certaines caractéristiques de l'entreprise. La présente
section décrit les différentes approches d'analyse
utilisées dans cette étude et le modèle utilisé.
4-1. Différentes approches
Deux types d'approche ont été
utilisés : l'approche descriptive et l'approche explicative.
L'approche descriptive a consisté en une série d'analyses
uniquement descriptives et cela en prélude à l'analyse
explicative. Il s'est agi d'analyser les différents liens ou
associations possibles entre chacune des variables indépendantes et la
variable dépendante (le nombre d'accidents). Nous avons alors
croisé la variable dépendante avec chaque variable
indépendante et effectué des tests d'association entre les
variables : le test de Fisher (Fisher's exact sous STATA), et le test de
Pearson. L'approche explicative ou analyse inférentielle a
consisté à vérifier cette association entre ces variables
afin de confirmer les tendances observées par l'analyse descriptive.
Nous avons eu, alors, recours à la modélisation
économétrique des déterminants de la survenance des
accidents du travail.
Précisons cependant que l'angle sous lequel nous
abordons cette étude n'est pas la prédiction de la survenance des
accidents du travail au sein des entreprises du secteur privé en
Côte d' Ivoire, mais plutôt une estimation de l'association entre
la survenance de ces accidents et les variables indépendantes
énumérées plus haut. Pour ce faire, nous avons
utilisé le modèle que nous présentons dans le prochain
point.
4-2. Modèles économétriques
(méthode d'estimation)
Dans la théorie, le nombre d'accidents dont un
travailleur est victime dans une période de longueur t (>o) est
distribué selon la loi de Poisson. Le nombre d'accidents
(Yi) d'un travailleur i dans une période
donnée est fonction d'un vecteur de variables exogènes
(Xi) représentant les caractéristiques
individuelles, socio-professionnelles et organisationnelles (GOURIEROUX et al.,
1984 ; CAMERON et TRIVALDI, 1986 ; DIONNE et VANASSE, 1992). La
probabilité d'avoir un accident aura la forme suivante :
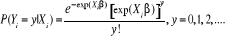 (1) (1)
Où exp (Xiâ)
=
E(Yi|Xi)
= Var
(Yi|Xi)
et où
E(Yi|Xi)
est l'espérance conditionnelle,
Var(Yi|Xi)
est la variance conditionnelle et â est un vecteur de paramètres
à estimer par la méthode du maximum de vraisemblance.
Notons cependant que la restriction « variance
égale à la moyenne » n'est pas toujours compatible
avec les données. L'hétérogénéité
n'est pas toujours captée ou saisie par la composante de la
régression (Xiâ).
GOURIEROUX et al, (1984) suggèrent d'étendre le
modèle de Poisson en ajoutant un terme aléatoire dans la
composante de régression, afin de tenir compte de l'effet de variables
non observables ou d'autres effets aléatoires. Si on suppose que exp
(åi)=ãi
suit une loi Gamma avec la fonction de densité :
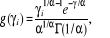 ã>0, á>0
(2) ã>0, á>0
(2)
Alors E(ãi) = 1 et
var(ãi) = á
Si l'on ajoute le terme aléatoire
åi dans l'équation (1), la
probabilité individuelle d'avoir 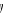 accidents devient alors : accidents devient alors :
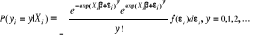 (3) (3)
Ou sous la condition définie précédemment
sur la distribution de ãi :
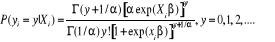 (4) (4)
Qui est la distribution Binomiale négative avec E
(Yi|Xi)
= exp (Xiâ) et Var
(Yi|Xi)
= exp[ (Xiâ)(1+á
exp(Xiâ)], á est alors
considéré comme le paramètre de sur-dispersion.
La valeur du paramètre de sur-dispersion á va
indiquer lequel des deux modèles (le modèle Poisson et le
modèle binomial négatif) est le plus adapté. Le
Likelihood-ratio test (LR) sous STATA permet de tester l'hypothèse
nulle :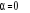 . Dans notre cas, il donne une p-value supérieure à 0,05,
on accepte alors l'hypothèse nulle. On peut par conséquent,
affirmer que á est significativement égale à 0, il n'y a
donc pas de sur-dispersion (la variance est statistiquement égale
à la moyenne). Le modèle de Poisson n'est donc pas
significativement différent de la Binomiale Négative. . Dans notre cas, il donne une p-value supérieure à 0,05,
on accepte alors l'hypothèse nulle. On peut par conséquent,
affirmer que á est significativement égale à 0, il n'y a
donc pas de sur-dispersion (la variance est statistiquement égale
à la moyenne). Le modèle de Poisson n'est donc pas
significativement différent de la Binomiale Négative.
Le graphique ci-dessous est l'histogramme du nombre de
travailleurs en fonction du nombre d'accident par travailleur sur la
période allant du premier janvier 2003 au 31 décembre 2004.
Graphique : Histogramme du nombre
d'accidents par travailleur
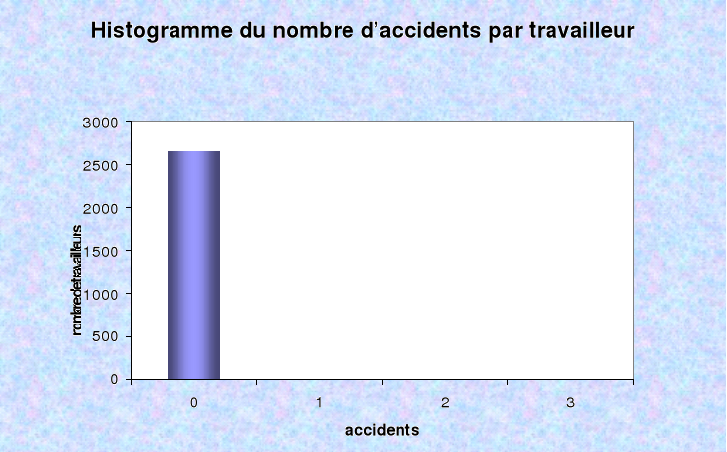
Source : DSI-CNPS
L'analyse de cet histogramme révèle qu'il
pourrait exister « un excès de zéro »
c'est-à-dire un nombre assez élevé d'individus n'ayant eu
aucun accident. Cette catégorie d'individus constitue 52,26 % du nombre
total d'individus dans l'échantillon. Le modèle de Poisson peut
être insuffisant pour expliquer tous ces zéros. Il peut alors
être intéressant d'utiliser un modèle qui prend en compte
simultanément le fait de faire un accident ou non et la fréquence
des accidents : le Zero- Inflated-Poisson model (ZIP).
Soit 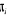 la probabilité de faire un nombre nul d'accident. Cette
probabilité est modélisée par un modèle
Logit : la probabilité de faire un nombre nul d'accident. Cette
probabilité est modélisée par un modèle
Logit :
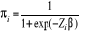 (5)
(5)
Le vecteur 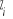 représente les caractéristiques individuelles,
socio-professionnelles et organisationnelles. représente les caractéristiques individuelles,
socio-professionnelles et organisationnelles.
La densité de la distribution ZIP s'écrit :
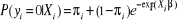
(6)
Si y > 0 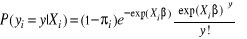
La statistique de Vuong permet de tester l'hypothèse
non emboîtée du choix du modèle Zero-Inflated-Poisson
contre le modèle de Poisson. La statistique de Vuong (calculée
à partir du logiciel STATA) donne pour valeur 20,13 et la p-value du
test est de 0,000 qui est inférieur à 0,05. On rejette
l'hypothèse nulle, et on accepte l'hypothèse alternative :
le modèle ZIP est préférable au modèle Poisson. Ce
choix est confirmé par les critères d'information :
critère d'Akaike (AIC) et BIC (voir annexe 2) : dans les deux cas
le modèle ZIP est celui qui fournit un critère minimal. La
survenue des accidents au sein des entreprises du secteur privé en
Côte d'Ivoire sera par conséquent modélisée par le
Zero-Inflated-Poisson.
L'analyse inférentielle consistera d'abord à
vérifier si les paramètres â des variables exogènes
sont significatifs, c'est-à-dire à vérifier si les
probabilités individuelles d'accidents sont fonction des
caractéristiques socio-professionnelles, individuelles et
organisationnelles évoquées plus haut. Ensuite, l'analyse des
Incidence Rate Ratios (IRR) permettra d'estimer le risque relatif lié
à chaque variable. Enfin l'examen des effets marginaux donnera la
contribution de chaque variable au processus accidentel.
| 

