Influences circadiennes sur le jugement social( Télécharger le fichier original )par Sébastien Stuhec Université Libre de Bruxelles - Master en sciences psychologiques à finalité spécialisée neuropsychologie et développement cognitif 2011 |

II. MéthodeSélection de la population MEQ (Morning Evaluation Questionnaire) Ce questionnaire (annexe 1) a été administré afin de sélectionner la population. Celui-ci investigue les caractéristiques de sommeil personnelles, si le sujet est du matin ou du soir. En fonction du score obtenu au questionnaire le sujet est classé vespéral ou matinal. La procédure est la suivante :
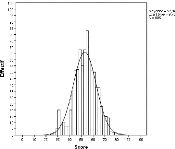
Graphique 1 : répartition du chronotype dans l'échantillon 805 personnes ont répondu au questionnaire et le chronotype se répartit de manière gaussienne (Graphique 1). L'age moyen de la population ayant répondu à ce questionnaire est de 36,83 ans et le score moyen est de 52, 94, ce qui équivaut à un score neutre, légèrement du matin. Les sujets extrêmes du matin, ayant un score supérieur ou égal à 70, représentent 3,97% de la population testée. Les sujets extrêmes du soir, ayant un score inférieur ou égal à 31, représentent 4,46% de la population testée. Sur base de ce questionnaire, 2 groupes ont été formés : un groupe composé de 24 sujets extremes du matin et un groupe composé de 24 sujets extremes du soir. En raison d'une difficulté pratique de recrutement, le score seuil pour les sujets extrêmes du soir a été augmenté à 32. L'age moyen des sujets extremes du matin qui ont été testés est de 47,08 ans contre 33,75 ans pour les sujets extremes du matin. Cette différence d'age entre les deux groupes est significative (t(1,46)=-2.99 ; p=0,04) et n'a pas pu être contrôlée de manière expérimentale. Ce facteur sera donc intégré dans les analyses statistiques. Plan expérimental Comme dit dans la section précédente, il existe deux groupes de participants : les extrêmes du matin ou « matinaux » et les extrêmes du soir ou « vespéraux ». Chaque sujet a été testé à 2 reprises : une fois au moment non-optimal (10h30 après le réveil pour les matinaux, 1h30 après le réveil pour les vespéraux), une fois au moment optimal (1h30 après le réveil pour les matinaux, 10h30 après le réveil pour les vespéraux). Les sujets sont testés 1h30 et 10h30 après leur lever afin de contrôler l'inertie de sommeil (Schmidt et al., 2009). Ces passations ont été contre-balancées, ainsi la moitié des sujets a commencé au moment optimal tandis que l'autre moitié a commencé par la passation non-optimale. La passation 1h30 après le lever a été commencée en moyenne 1h27 après le lever et la condition 10h30 post-réveil a été commencée en moyenne 10h29 après le lever. L'ordre de passation des tâches a été contrôlé afin de s'assurer que l'ordre dans lequel le sujet effectue les tâches n'a pas d'impact sur sa performance.
Tableau 1 : Contre-balancement de l'ordre de passation Ainsi chaque groupe a été réparti en 6 conditions, chaque condition correspondant à l'ordre dans lequel les sujets passent les tâches (tableau 1). En résumé, voici le plan expérimental utilisé (tableau 2).
Numéros de sujets Tableau 2 : résumé du plan expérimental Enfin, afin d'éviter un effet test-retest, il s'est écoulé 7 à 10 jours (8,3 jours en moyenne) entre les 2 passations pour chaque sujet. Expérience Le sujet effectue 4 tâches : une tâche de type Go/No-Go (inhibition), une tâche PVT (vigilance), une tâche IAT (jugement social implicite) et une échelle explicite de préjugés (jugement social explicite). Les 3 premières tâches sont contrebalancées comme expliqué dans la partie précédente et la 4ème tâche (échelle explicite) est toujours présentée en dernier. Le temps de réalisation de l'ensemble de ces tâches lors d'une passation avoisine les 45 minutes. L'ensemble des tâches informatisées a été réalisé sur un PC portable Dell Inspiron 6000 cadencé à 1,6GHz avec 1 Go RAM. Tâche Go/No-Go (inhibition) La tâche Go/No-Go utilisée est une tâche informatisée dans laquelle le sujet doit appuyer quand il voit n'importe quelle lettre à l'exception d'une (dans notre cas la lettre X) (figure 7). Cette tâche va permettre de mesurer la capacité du sujet à inhiber une réponse prépotente. La tâche dure approximativement 20 minutes. Condition go Condition no-go (appuyer lorsqu'une lettre apparait) (ne pas appuyer lorsque la lettre X apparait)
Figure 7 : illustration de la tâche GoNoGo La tâche utilisée est une traduction française de celle utilisée dans l'article de Hinshaw, Greenhill, Shafritz, Vitolo, Kotler, Jarrett et Glover, 2007 disponible sur le site internet de l'institut Sackler2. La tâche a été exécutée grâce au logiciel e-prime 2.0.8.89. Elle est composée de 5 blocs comprenant chacun 129 items dont 25 items NoGo et 104 items Go. Tâche de vigilance psychomotrice (PVT) (vigilance) Cette tâche créée par Dinges, 1985 (in Schmidt, 2009) est également une tâche informatisée dans laquelle le sujet doit répondre le plus vite possible lorsqu'il voit un compteur défiler, sans pour autant anticiper sa réponse. Les mesures prises en compte sont le temps de réaction (TR), le nombre d'erreurs d'omission (TR de plus de 500 ms), le nombre de commissions (le sujet appuie alors qu'il ne devrait pas, le temps de réaction est inférieur à 100 ms) et la variabilité intra-sujet (différence entre les temps de réaction les 10% plus rapides et les 10% moins rapides). Ces mesures vont nous permettre de vérifier si le sujet maintient sa vigilance lors des tâches proposées. Elle va nous permettre également de vérifier également si le maintien de la vigilance est équivalent au moment optimal et non optimal. Cette tâche dure 10 minutes. L'intervalle entre les stimuli est aléatoire entre 2 et 10s. Le sujet voit ainsi apparaitre approximativement 70 stimuli pendant la réalisation de la tâche. 2 http://www.sacklerinstitute.org/cornell/assays_and_tools/ Tâche d'association implicite (IAT) (jugement social implicite) La tâche a été adaptée de la version Racism IAT sur le site de Millisecond3. La tâche est exécutée via le logiciel Inquisit 3.0.4.0. La tâche est composée de 8 items cibles á savoir 8 prénoms masculins, 4 prénoms á consonance francophone (Pascal, Grégory, Damien, Ferdinand) et 4 prénoms á consonance maghrébine (Mohamed, Ahmed, Ali, Youssef). Les prénoms francophones et maghrébins ont été associés sur base de leur fréquence dans la population belge4. Les deux types d'attributs (Bon/Mauvais) comportent chacun 8 items (Bon : merveilleux, superbe, plaisir, beau, plaisant, glorieux, charmant, magnifique / Mauvais : tragique, horrible, agonie, douloureux, terrible, épouvantable, humiliant, méchant). Lors de cette tâche, le sujet appuie chaque fois sur la touche E pour associer la catégorie de gauche. Il appuie sur I pour la catégorie de droite. Lorsqu'il commet une erreur, une croix rouge apparait en dessous de l'item pour l'inviter à corriger.
Figure 8 : 2 concepts cibles
2 concepts cibles apparaissent dans une tâche á deux choix (Maghrébin/Autre) (figure 8). Dans l'exemple ici, le sujet voit apparaitre le prénom « Pascal » au centre de l'écran, il appuie sur la touche correspondant á la catégorie « Autre » (la touche E sur le clavier). Le sujet continue á répondre avec les mêmes touches á une seconde tâche qui concerne l'attribut (Bon/Mauvais) (figure 9). Dans l'exemple, le sujet appuie sur la touche correspondant á la catégorie « Mauvais » (touche I). Figure 9 : attribut
La tâche est contre-balancée afin qu'elle ne commence pas toujours par la méme association concept-attribut. Pour l'analyse des résultats, nous porterons notre intérét sur le score D. Il s'agit d'une mesure qui divise la différence entre la moyenne des blocs tests par l'écart-type de l'ensemble des temps de réaction des deux blocs. Les résultats de Greenwald, Nosek et Banaji, 2003 indiquent que l'algorithme conventionnel de l'IAT est dépassé par la mesure D pour (a) la magnitude de la corrélation implicite-explicite, (b) la résistance à la contamination par des réponses de vitesse différente, (c) la résistance à l'effet de réduction du score IAT, (d) la sensibilité aux effets connus sur les mesures IAT et (e) la latence implicite explicite dans l'analyse factorielle confirmatoire. Cette mesure D étant plus fine et plus sensible, c'est elle que nous retiendrons pour l'analyse des résultats de l'IAT. Nous nous attendons ici à ce que le score D soit de manière générale positif, ce qui indiquerait une préférence de l'échantillon pour la population francophone. Mais surtout nous nous attendons à ce qu'au moment non-optimal de leur journée les sujets aient un score D plus positif qu'au moment non optimal. Cela indiquerait que la préférence pour la population endogène (francophone) est plus marquée au moment non-optimal de la journée. Echelle explicite de préjugés (jugement social explicite) Dans cette échelle (annexe 2), on présente au sujet des phrases ambiguës, une par une. A chacune de ses phrases, le sujet doit répondre de « pas du tout d'accord » à « tout à fait d'accord ». Par exemple : Les personnes d'origine maghrébine travaillent aussi dur pour aller de l'avant que la plupart des autres Belges.
Gette tâche va permettre de déterminer si le sujet a une propension plus importante au préjugé de manière explicite au moment non-optimal de sa journée. Gette tâche dure environ 5 minutes. La méthodologie utilisée pour l'analyse de l'échelle explicite repose sur l'article de Laïla Benraiss (2004). L'échelle est composée de 6 questions construites sous forme d'échelles de Likert à 4 positions. Il s'agit donc d'une échelle de type ordinal où chaque item ne peut prendre que 4 valeurs. Nous effectuons une étude exploratoire afin de purifier l'instrument de mesure. Le test de Bartlett teste l'hypothèse nulle de corrélation des variables. Le seuil de risque est proche de 0 (p=0,000), l'hypothèse des corrélations nulles peut être rejetée. Ici, les données sont ainsi corrélées et donc factorisables. L'indice KMO donné par le test de Kaiser, Meyer et Olkin est de 0,575. Get indice et faible et peu acceptable. L'alpha de Cronnbach permet de mesurer la fiabilité des items à mesurer ce qu'ils sont censés mesurer. Lorsque l'alpha des questions approche 1, la cohérence interne de l'échelle est bonne, lorsqu'elle approche de 0, la cohérence est faible. Un alpha acceptable est compris entre 0,6 et 0,7 (Nunnally, 1978 ; in Benraiss, 2004). L'alpha de Gronnbach ici est de 0,522, ce qui est également faible. Nous décidons dès lors de supprimer la question 5, ce qui porte l'indice KMO à 0,606 et l'alpha de Cronnbach à 0,650 qui sont des données acceptables. Un score composite est calculé sur base des items retenus. Ge score correspond à la moyenne des scores de chaque question. |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||