CHAPITRE IV :INFLUENCE DES
FACTEURS D'ATTRACTIVITE SUR LA LOCALISATION DES ENTREPRISES INDUSTRIELLES DANS
LES COLLECTIVITES DU CENTRE.
Introduction
La région regroupe en son sein dix départements
et de plusieurs collectivités territoriales
décentralisées. C'est donc dire que la région est
dotée de ressources (latentes et actives), qui constituent des atouts
majeurs de l'attractivité de la région. Cependant, l'un des
constats qu'on peut faire en matière de localisation et
d'attractivité des différentes localités de cette
région, est le fait que la plupart des unités de production
industrielle qui se trouve dans la région sont regroupées dans
les collectivités territoriales du département du Mfoundi
(chef-lieu : Yaoundé). D'un premier regard, l'on peut dire que
département semble être plus attractif aux yeux des
opérateurs, investisseurs, industrielles etc... Lorsqu'il s'agit
d'investir, de s'implanter, ou se localiser dans la Région du Centre.
Ainsi, l'objectif de se mémoire étant de
déterminer les facteurs territoriaux de la région du centre qui
attirent et guident les choix de localisation des entreprises industrielles,
après qu'elle est fait le choix de s'implanter dans le centre.
C'est-dire, de déterminer les variables explicatives qui rendent telle
ou telle département attractif aux activités industrielles. Et
plus particulièrement, pourquoi le Mfoundi est le plus
sollicité.
Pour trouver les variables explicatives pour le modèle
de localisation nous avons recherché les facteurs de localisation dans
les travaux des théoriciens, mais aussi dans des études
empiriques et dans des enquêtes (enquête AGUILERA-BELANGER &
al., 1999).Comme nous l'avons signalé auparavant la localisation des
activités économiques dépend d'un nombre plus ou moins
grand de facteurs. Ces facteurs ont des rôles et des poids
différents selon les secteurs. De plus, nous disposons d'un nombre
important de variables. Il est nécessaire de convertir les facteurs en
indicateurs tangibles et de réaliser une présélection des
variables. La présélection des variables a été
réalisée à partir de traitements : corrélation
entre le secteur et les variables disponibles, nous avons essayé de
repérer les variables qui ont un lien avec les secteurs qui nous
intéressent.
Dans ce chapitre, nous exposerons dans la première
section les données et le modèle qui nous permettra d'effectuer
cette étude, et dans la seconde section, après avoir
effectué une régression économétrique par la
méthode des moindres carrés ordinaires (MCO), nous
présenterons les résultats et on analysera ces
résultats.
SECTION I : PRESENTATION DES
DONNEES DU MODELE ET CACULS STATISTIQUES
I.1. Présentation des
données utilisées pour le modèles
Les données utilisées pour le travail empirique
de ce mémoire, nous ont été données par l'INS qui
l'a extrait de la base de donnée d'une série de
déclarations statistiques et fiscales (DSF) que produisent chaque
année les entreprises du secteur secondaire, qui résume quasiment
le secteur industriel dans la région du centre. Ceci pour la
période allant de 2008 à 2013, c'est-à-dire sur une
série d'observation de 06 ans.
I.1.1. Présentation
et mode de construction d'une DSF
i. Présentation
d'une DSF
Une déclaration statique et fiscale est un document
financier dont tout entreprise faisant partir du régime du réelle
a l'obligation d'élaborer, lorsqu'elle monte ces états de fin
d'exercice. C'est un document qui présente fait preuve de la situation
financière et certaines appréhensions des entreprises, quant
à leur milieu financier, administratif, situation environnementale, et
certaines difficultés auxquelles elles font face. Elle résume les
rubriques définies dans le plan comptable.
ii. Le mode de
construction de la base donnée à partir de la DSF
La base de données issue des DSF telle que construite
par L'INS, résume en colonne l'ensemble des variables conduisant
à l'analyse financière de ces entreprises. On peut distinguer en
colonne, les variables telles que : le chiffre d'affaire, l'effectif total
employé, les clients, la consommation des matières
premières etc.... En ligne, on a les noms et les codes des entreprises.
Il faut également préciser que les données des
déclarations sont observées sur une longue période
(série chronologique ou sur plusieurs années).
I.1.2 Prestation des
variables et du modèle
i. Présentation des
variables
Les données utilisées pour construire nos
variables ont été extraites de la base de données des
déclarations statistiques et fiscales dont dispose l'INS. Il faut dire
que nous avons extrait les données relatives au secteur sur lequel nous
travaillons. C'est-à-dire le secteur industriel (secondaire),
Il faut également rappeler que nous avons mis en oeuvre
deux modèles, à cause du fait que les données que nous
avons reçues ne s'étendaient que sur 04 ans. Et les variables
explicatives que nous avons définies pour les deux modèles
tendent toutes à expliquer les raisons de l'attraction du nombre
d'entreprise du secteur dans la région du centre.
Tableau 17 :variables du premier
modèle (1)
|
Numéro
|
Codes variables
|
Libellé de la variable
|
|
1
|
NBR_ENTR
|
Nombre d'entreprises industrielles
|
|
2
|
EFF_TOT
|
Effectif total des employés du
secteur
|
|
3
|
SERV_EXT
|
Sévices extérieurs
|
|
4
|
CA
|
Chiffre d'affaire
|
|
5
|
CAPTL
|
Capital
|
Source : Traitement de
l'auteur
Tableau 18 :variables du second modèle
(2)
|
Numéro
|
Code variables
|
Libellé de la variable
|
|
1
|
NBR_ENTR
|
Nombre d'entreprises industrielles
|
|
2
|
CLIEN
|
Clients
|
|
3
|
MAT_PREM
|
Matière première et autres
approvisionnements
|
|
4
|
TRANSP
|
Transport
|
|
PROD_FABR
|
Produits fabriqués
|
Source : Traitement de l'auteur
Dans les deux modèles, la variable expliquée est
le nombre d'entreprises du secteur industriel de la région. Car, n
observant l'évolution de ce nombre sur toute la période
d'étude, on observe qu'il y'a une certaine augmentation. C'est ainsi
qu'on voudrait déterminer et étudier les facteurs ou les
variables qui poussent celles-ci à se localiser dans le centre, afin
d'appréhender les éléments qui rendent cette région
du Centre attractive aux yeux des industries.
ii. Présentation du
modèle
On peut citer trois grands types de modèles : le
modèle des MCO, le modèle à effet fixe et le modèle
à effet aléatoire connu aussi sous le nom de modèle
à composantes d'erreur, le modèle à coefficients
aléatoires, le modèle à structure de covariance.
Le modèle des MCO :
c'est le plus simple sur le postulat que les individus qui composent
l'échantillon sont rigoureusement homogènes c'est-à-dire
ne se démarquent les uns des autres par aucune caractéristique
spécifique. Dès lors, il n'y a qu'une composante au vecteur
Zi : la constante, commune à tous les individus. Le modèle
spécifié est :
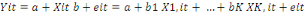
Où les coefficients sont estimés sur la base
d'un échantillon à l'intérieur duquel les données
sont « empilées » sans égard par rapport aux
individus non plus que par rapport aux dates.
En terme matriciel et pour l'individu i on a encore :
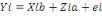 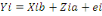 . .
Mais avec une matrice Zi à une seule colonne
dont tous les éléments sont égaux à 1 de telle
sorte que la constante a est la même pour tous les individus. A la
condition que le postulat d'homogénéité soit fondé
d'une part et que, d'autre part, les propriétés relatives
à « eit » soient vérifiées
(en particulier l'absence d'autocorrélation) l'estimateur MCO de
« b » est sans biais, convergent et de variance
minimum.
Le modèle à effets
fixes : Imagination que chaque individu présente des
caractéristiques propres susceptible d'affecter la relation
étudiée. Dans ce contexte
d'hétérogénéité des individus, une
spécification MCO sur données
« empilées » qui postule une même structure
XY quel que soit l'individu étudié induit un biais
d'omission : l'estimateur MCO des bk est biaisé et non
convergent (confère cours Econométrie III).
Deux cas de figure peuvent être envisagés :
d'une part, toutes les caractéristiques spécifiques sont
observables et quantifiables, d'autre part, certaines caractéristiques
ne le sont pas, quoiqu'on sache qu'elles existent.
Le modèle à effets aléatoires
(modèle à composantes d'erreur) : Une autre
manière d'aborder la question de
l'hétérogénéité des individus à
l'intérieur d'un échantillon en données de panel consiste
à interpréter le terme d'erreur comme étant la somme de
deux composantes (d'où la terminologie utilisée de modèle
à composantes d'erreur) :
- une première composante
« eit » similaire à celle qui apparaissait
déjà dans les modèles précités,
- une seconde, plus originale, postule que chaque individu se
démarque des autres par la réalisation d'une variable
aléatoire dont les caractéristiques (en particulière,
moyenne et variance) sont identiques d'un individu à l'autre. Ce type de
modèle est ainsi spécifié :
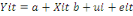 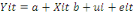 avec avec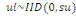 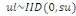 . .
Attention, contrairement à ce qui se passe dans le
cadre du modèle à effet fixe pour lequel les individus se
démarquent les uns des autres par un élément constant. La
composante qui apparait ici n'est pas une constante mais bien la
réalisation d'une variable aléatoire. Bien sûr, comme on
sait que la présence d'une corrélation entre le terme d'erreur et
variables explicatives engendrent des problèmes de biais dans
l'estimation des coefficients du modèle. L'hypothèse sous-jacente
à l'usage d'un modèle à composante d'erreur est que :
la composante aléatoire spécifique qui n'est pas
corrélé avec les variables explicatives du modèle. Cette
hypothèse sous-jacente peut être suspecte dans certaines
circonstances. Imaginons par exemple qu'il s'agit d'expliquer le salaire d'un
individu. Au rang des variables explicatives on retrouvera sans surprise de
variables représentatives de l'ancienneté dans l'entreprise mais
aussi, et de manière plus intéressante, le nombre d'années
d'études ou encore le niveau de diplôme. L'élément
spécifique aléatoire est réputé rendre compte des
influences exercées par toutes les variables omises ou non observables,
au rang desquelles figurent vraisemblablement les qualités de
l'individu, dont on peut penser qu'elles ne sont sans doute pas totalement
indépendantes du nombre d'années d'études ou du niveau de
diplôme. Il est alors difficile de soutenir que cette composante
aléatoire est sans corrélation avec les variables explicatives
retenues.
Les modèles à coefficients
aléatoires : A vrai dire le modèle à
composante d'erreur se démarque du modèle MCO en cela que ce qui
est nécessairement constant dans le modèle MCO :
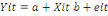 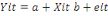 Devient aléatoire dans le modèle à composante
d'erreur : Devient aléatoire dans le modèle à composante
d'erreur :
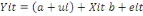
On peut généraliser ce traitement
réservé jusqu'ici à l'élément constant et
à l'ensemble de tous les coefficients du modèle qui devient
alors : 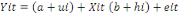 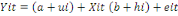
L'hypothèse qui est faite dans ce cas est que les
valeurs des coefficients peuvent différer aléatoirement d'un
individu à l'autre, quoiqu'en espérance ces coefficients soient
identiques.
| 

