SECTION II : RESULTATS DES
ESTIMATIONS ECONOMETRIQUES ET ANALYSES
Pour estimer notre modèle, nous avons construit deux
modèles comme nous l'avons précisé plus haut. Dans ces
deux modèles nous avons une seule variable expliquée qui est le
nombre d'entreprises présent dans le secteur industriel au centre. C'est
ainsi que notre modèle est un modèle à effet
aléatoire par rapport au secteur industriel. Les deux modèles
définis ont la structure suivante suivant :
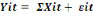
Y : est la variable expliquée
ÓX : est la somme des variables explicatives
du modèle
å : est le terme d'erreur
i : est le secteur considéré,
c'est-à-dire le secteur industriel
t : est la série temporel ou la
période d'étude (05 ans)
Les modèles sont donc présentés comme
suit :
Modèle 1 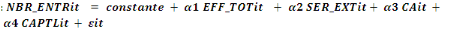 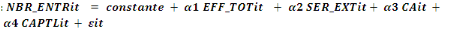 (1) (1)
Modèle 2 : 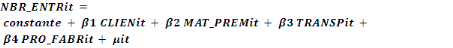  (2) (2)
Test de spécification de
Hausman
Dans un modèle de régression linéaire sur
données de panel, le test d'Hausman permet de tester la différent
entre le modèle à effet fixes et supposé
convergent sous l'hypothèse nulle et l'hypothèse
alternative ; et le modèle à effet
aléatoire, supposé convergent et efficace sous
l'hypothèse nulle mais non convergent sous l'hypothèse
alternative.
Les hypothèses du test sont donc les suivantes :
- H0 : Absences d'effet fixes
- H1 : Présence d'effet fixe
La statistique de Fisher calculé suit sous
l'hypothèse H0 une loi de Fisher. A cet effet l'hypothèse de
présence d'effets fixe ne sera pas rejetée lorsque la statistique
calculée est supérieure à la valeur critique lue sur la
table de Fisher.
La statistique du test est : 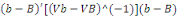 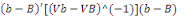 , elle suit une loi de fisher. , elle suit une loi de fisher.
Le principe du teste consiste à régresser les deux
modèles (modèle à effets fixes et modèle à
effets aléatoires) et d'étudier le comportement de résidus
afin de retenir le modèle le plus approprié.
II.1. Résultats des
estimations économétriques
Nous allons présenter et interpréter les
principaux résultats obtenus lors de l'estimation du modèle de
Berger et Nitsch [2008], qui met en exergue l'influence des
certaines variables sur le niveau d'attractivité des régions.
Il est important de rappeler que nous n'avons pas
trouvé nécessaire de vérifier la stationnarité des
variables sur données de panel. Car ; la composante temporelle
n'est que de 5 ans (2008-2012). Les estimations ont été faites
par la méthode des Moindres Carrées Ordinaires (MCO) avec
écart-types robustes sur la période, Ceci par la méthode
de White ; afin de corriger l'hétéroscédasticité
des erreurs et rendre les écart-types ainsi minimales. Car, il est
conseillé dans le cas où le panel est non cylindré
d'utiliser l'option robuste de manière à tenir compte de
l'hétéroscédasticité des erreurs, puisque la
variance des erreurs du modèle transformé n'est pas constante.
Modèle 1
Le modèle 1 a été estimé sans
effets fixes période ; étant donné la longueur des
séries (effets temps), mais en corrigeant
l'hétéroscédasticité. Il est globalement
significatif à 1%. On peut noter qu'excepté le niveau de commerce
illicite non compressible et le coefficient du niveau technologique et de
compétences que nécessitent les produits, toutes les variables
explicatives sont contributives, ou que tous leurs coefficients sont
significatifs à 1% au plus.
De l'estimation des modèles à effet
aléatoire et fixe, il ressort après réalisation du test de
Hausman que le meilleur modèle est le modèle à effet
aléatoire.
Le coefficient de la variable EFFECTIF_TOTAL est significatif
et positif à 1%. Aussi, l'effectif des employés dans les
entreprises du secteur industriel de l'économie Camerounaise, dans la
Région du centre contribue à accroitre le nombre d'entreprise de
cette Region. Ce qui est normal, ceci d'autant plus que le nombre
d'employé est susceptible d'augmenté avec le nombre d'entreprise
peu importe la taille de cette dernière.
MODELE 1
Modèle
aléatoire
|
Dependent Variable: NOMBRE_D_ENTREPRISE
|
|
|
Method: Panel EGLS (Cross-section random effects)
|
|
Date: 10/04/16 Time: 15:18
|
|
|
|
Sample: 2008 2012
|
|
|
|
Periods included: 5
|
|
|
|
Cross-sections included: 43
|
|
|
|
Total panel (balanced) observations: 215
|
|
|
Swamy and Arora estimator of component variances
|
|
White cross-section standard errors & covariance (d.f.
corrected)
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
C
|
-364.7758
|
2.22E-11
|
-1.64E+13
|
0.0000
|
|
EFFECTIF_TOTAL
|
0.096262
|
6.77E-15
|
1.42E+13
|
0.0000
|
|
SERVICES_EXTERIEURS
|
3.86E-10
|
2.15E-23
|
1.79E+13
|
0.0000
|
|
CHIFFRE_D_AFFAIRES
|
9.79E-10
|
2.06E-22
|
4.75E+12
|
0.0000
|
|
CAPITAL
|
-1.82E-09
|
2.35E-21
|
-7.73E+11
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
Effects Specification
|
|
|
|
|
|
S.D.
|
Rho
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section random
|
0.000000
|
0.0000
|
|
Idiosyncratic random
|
6.74E-12
|
1.0000
|
|
|
|
|
|
|
|
|
|
|
|
Weighted Statistics
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Adjusted R-squared
|
1.000000
|
S.D. dependent var
|
60.71268
|
|
S.E. of regression
|
6.03E-12
|
Sum squared resid
|
7.64E-21
|
|
F-statistic
|
5.42E+27
|
Durbin-Watson stat
|
0.635654
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Unweighted Statistics
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Sum squared resid
|
7.64E-21
|
Durbin-Watson stat
|
0.635654
|
|
|
|
|
|
|
|
|
|
|
Modèle fixe
|
Dependent Variable: NOMBRE_D_ENTREPRISE
|
|
|
Method: Panel Least Squares
|
|
|
|
Date: 10/04/16 Time: 15:18
|
|
|
|
Sample: 2008 2012
|
|
|
|
Periods included: 5
|
|
|
|
Cross-sections included: 43
|
|
|
|
Total panel (balanced) observations: 215
|
|
|
White cross-section standard errors & covariance (d.f.
corrected)
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
C
|
-364.7758
|
2.56E-11
|
-1.43E+13
|
0.0000
|
|
EFFECTIF_TOTAL
|
0.096262
|
7.34E-15
|
1.31E+13
|
0.0000
|
|
SERVICES_EXTERIEURS
|
3.86E-10
|
2.56E-23
|
1.51E+13
|
0.0000
|
|
CHIFFRE_D_AFFAIRES
|
9.79E-10
|
2.29E-22
|
4.28E+12
|
0.0000
|
|
CAPITAL
|
-1.82E-09
|
2.64E-21
|
-6.89E+11
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
Effects Specification
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section fixed (dummy variables)
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Adjusted R-squared
|
1.000000
|
S.D. dependent var
|
60.71268
|
|
S.E. of regression
|
6.74E-12
|
Akaike info criterion
|
-48.41825
|
|
Sum squared resid
|
7.63E-21
|
Schwarz criterion
|
-47.68141
|
|
Log likelihood
|
5251.962
|
Hannan-Quinn criter.
|
-48.12054
|
|
F-statistic
|
3.78E+26
|
Durbin-Watson stat
|
0.636532
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Test de Hausman (Absence d'effet fixe)
|
Correlated Random Effects - Hausman Test
|
|
|
Equation: Untitled
|
|
|
|
Test cross-section random effects
|
|
|
|
|
|
|
|
|
|
|
|
|
Test Summary
|
Chi-Sq. Statistic
|
Chi-Sq. d.f.
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section random
|
0.000000
|
4
|
1.0000
|
|
|
|
|
|
|
|
|
|
|
|
** WARNING: robust standard errors may not be consistent with
|
|
assumptions of
Hausman test variance calculation.
|
|
** WARNING: estimated cross-section random effects variance is
zero.
|
|
|
|
|
|
|
Cross-section random effects test comparisons:
|
|
|
|
|
|
|
Variable
|
Fixed
|
Random
|
Var(Diff.)
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
EFFECTIF_TOTAL
|
0.096262
|
0.096262
|
0.000000
|
1.0000
|
|
SERVICES_EXTERIEURS
|
0.000000
|
0.000000
|
0.000000
|
1.0000
|
|
CHIFFRE_D_AFFAIRES
|
0.000000
|
0.000000
|
0.000000
|
1.0000
|
|
CAPITAL
|
-0.000000
|
-0.000000
|
0.000000
|
1.0000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section random effects test equation:
|
|
|
Dependent Variable: NOMBRE_D_ENTREPRISE
|
|
|
Method: Panel Least Squares
|
|
|
|
Date: 10/04/16 Time: 15:18
|
|
|
|
Sample: 2008 2012
|
|
|
|
Periods included: 5
|
|
|
|
Cross-sections included: 43
|
|
|
|
Total panel (balanced) observations: 215
|
|
|
White cross-section standard errors & covariance (d.f.
corrected)
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
C
|
-364.7758
|
2.56E-11
|
-1.43E+13
|
0.0000
|
|
EFFECTIF_TOTAL
|
0.096262
|
7.34E-15
|
1.31E+13
|
0.0000
|
|
SERVICES_EXTERIEURS
|
3.86E-10
|
2.56E-23
|
1.51E+13
|
0.0000
|
|
CHIFFRE_D_AFFAIRES
|
9.79E-10
|
2.29E-22
|
4.28E+12
|
0.0000
|
|
CAPITAL
|
-1.82E-09
|
2.64E-21
|
-6.89E+11
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
Effects Specification
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section fixed (dummy variables)
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Adjusted R-squared
|
1.000000
|
S.D. dependent var
|
60.71268
|
|
S.E. of regression
|
6.74E-12
|
Akaike info criterion
|
-48.41825
|
|
Sum squared resid
|
7.63E-21
|
Schwarz criterion
|
-47.68141
|
|
Log likelihood
|
5251.962
|
Hannan-Quinn criter.
|
-48.12054
|
|
F-statistic
|
3.78E+26
|
Durbin-Watson stat
|
0.636532
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MODELE 2
Le modèle 1 a été estimé sans
effets fixes période ; étant donné la longueur des
séries (effets temps), mais en corrigeant
l'hétéroscédasticité. Il est globalement
significatif à 1%. On peut toujoursnoter ici
qu'excepter le niveau de commerce illicite non compressible et le coefficient
du niveau technologique et de compétences que nécessitent les
produits qui ne toutes les variables explicatives sont également
contributive, ou que tous leurs coefficients sont significatifs à
1% au plus.
De l'estimation des modèles à effet
aléatoire et fixe, il ressort après réalisation du test de
Hausman que le meilleur modèle est le modèle à effet
aléatoire.
Ici le coefficient des variables CLIENTS et PRODUITS_FABRIQUES
sont significatives et positif à 1%. Ainsi, l'effectif des clients dans
les entreprises des secteurs industriel de l'économie camerounaise de la
région du Centre jumelé à l'augmentation de la production
des secteurs, contribuent à accroitre le nombre d'entreprises de cette
région. Ce qui est normal, car d'autant le nombre de clients du secteur
est susceptible d'augmenter, d'autant les entreprises sont susceptibles
d'accroitre leur niveau de production pour satisfaire la demande. Ce qui a pour
conséquence d'entrainer l'augmentation du nombre d'entreprises dans la
région, peu importe la taille de ces dernières.
Modèle aléatoire
|
Dependent Variable: NOMBRE_D_ENTREPRISE
|
|
|
Method: Panel EGLS (Cross-section random effects)
|
|
Date: 10/04/16 Time: 15:27
|
|
|
|
Sample: 2008 2012
|
|
|
|
Periods included: 5
|
|
|
|
Cross-sections included: 43
|
|
|
|
Total panel (balanced) observations: 215
|
|
|
Swamy and Arora estimator of component variances
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
C
|
184.7818
|
2.48E-10
|
7.44E+11
|
0.0000
|
|
CLIENTS
|
3.33E-09
|
3.84E-21
|
8.67E+11
|
0.0000
|
|
MATIERES_PREMIERES_ET_AU
|
-5.68E-08
|
3.24E-20
|
-1.75E+12
|
0.0000
|
|
TRANSPORTS
|
4.33E-08
|
1.36E-20
|
3.18E+12
|
0.0000
|
|
PRODUITS_FABRIQUES
|
5.02E-08
|
3.54E-20
|
1.42E+12
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
Effects Specification
|
|
|
|
|
|
S.D.
|
Rho
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section random
|
0.000000
|
0.0000
|
|
Idiosyncratic random
|
1.24E-10
|
1.0000
|
|
|
|
|
|
|
|
|
|
|
|
Weighted Statistics
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Adjusted R-squared
|
1.000000
|
S.D. dependent var
|
60.71268
|
|
S.E. of regression
|
1.11E-10
|
Sum squared resid
|
2.60E-18
|
|
F-statistic
|
1.60E+25
|
Durbin-Watson stat
|
2.619085
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Unweighted Statistics
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Sum squared resid
|
2.60E-18
|
Durbin-Watson stat
|
2.619085
|
|
|
|
|
|
|
|
|
|
|
Modèle fixe
|
Dependent Variable: NOMBRE_D_ENTREPRISE
|
|
|
Method: Panel Least Squares
|
|
|
|
Date: 10/04/16 Time: 15:28
|
|
|
|
Sample: 2008 2012
|
|
|
|
Periods included: 5
|
|
|
|
Cross-sections included: 43
|
|
|
|
Total panel (balanced) observations: 215
|
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
C
|
184.7818
|
2.48E-10
|
7.44E+11
|
0.0000
|
|
CLIENTS
|
3.33E-09
|
3.84E-21
|
8.67E+11
|
0.0000
|
|
MATIERES_PREMIERES_ET_AU
|
-5.68E-08
|
3.24E-20
|
-1.75E+12
|
0.0000
|
|
TRANSPORTS
|
4.33E-08
|
1.36E-20
|
3.18E+12
|
0.0000
|
|
PRODUITS_FABRIQUES
|
5.02E-08
|
3.54E-20
|
1.42E+12
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
Effects Specification
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section fixed (dummy variables)
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Adjusted R-squared
|
1.000000
|
S.D. dependent var
|
60.71268
|
|
S.E. of regression
|
1.24E-10
|
Akaike info criterion
|
-42.58843
|
|
Sum squared resid
|
2.60E-18
|
Schwarz criterion
|
-41.85160
|
|
Log likelihood
|
4625.257
|
Hannan-Quinn criter.
|
-42.29072
|
|
F-statistic
|
1.11E+24
|
Durbin-Watson stat
|
2.619108
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Test de Hausman (Absence d'effet fixe)
|
Correlated Random Effects - Hausman Test
|
|
|
Equation: Untitled
|
|
|
|
Test cross-section random effects
|
|
|
|
|
|
|
|
|
|
|
|
|
Test Summary
|
Chi-Sq. Statistic
|
Chi-Sq. d.f.
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section random
|
0.000000
|
4
|
1.0000
|
|
|
|
|
|
|
|
|
|
|
|
* Cross-section test variance is invalid. Hausman statistic set
to zero.
|
|
** WARNING: estimated cross-section random effects variance is
zero.
|
|
|
|
|
|
|
Cross-section random effects test comparisons:
|
|
|
|
|
|
|
Variable
|
Fixed
|
Random
|
Var(Diff.)
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
CLIENTS
|
0.000000
|
0.000000
|
0.000000
|
1.0000
|
|
MATIERES_PREMIERES_ET_AU
|
-0.000000
|
-0.000000
|
0.000000
|
1.0000
|
|
TRANSPORTS
|
0.000000
|
0.000000
|
0.000000
|
1.0000
|
|
PRODUITS_FABRIQUES
|
0.000000
|
0.000000
|
0.000000
|
1.0000
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section random effects test equation:
|
|
|
Dependent Variable: NOMBRE_D_ENTREPRISE
|
|
|
Method: Panel Least Squares
|
|
|
|
Date: 10/04/16 Time: 15:28
|
|
|
|
Sample: 2008 2012
|
|
|
|
Periods included: 5
|
|
|
|
Cross-sections included: 43
|
|
|
|
Total panel (balanced) observations: 215
|
|
|
|
|
|
|
|
|
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
|
|
|
|
|
|
|
|
|
|
C
|
184.7818
|
2.48E-10
|
7.44E+11
|
0.0000
|
|
CLIENTS
|
3.33E-09
|
3.84E-21
|
8.67E+11
|
0.0000
|
|
MATIERES_PREMIERES_ET_AU
|
-5.68E-08
|
3.24E-20
|
-1.75E+12
|
0.0000
|
|
TRANSPORTS
|
4.33E-08
|
1.36E-20
|
3.18E+12
|
0.0000
|
|
PRODUITS_FABRIQUES
|
5.02E-08
|
3.54E-20
|
1.42E+12
|
0.0000
|
|
|
|
|
|
|
|
|
|
|
|
Effects Specification
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Cross-section fixed (dummy variables)
|
|
|
|
|
|
|
|
|
|
|
|
|
R-squared
|
1.000000
|
Mean dependent var
|
90.96175
|
|
Adjusted R-squared
|
1.000000
|
S.D. dependent var
|
60.71268
|
|
S.E. of regression
|
1.24E-10
|
Akaike info criterion
|
-42.58843
|
|
Sum squared resid
|
2.60E-18
|
Schwarz criterion
|
-41.85160
|
|
Log likelihood
|
4625.257
|
Hannan-Quinn criter.
|
-42.29072
|
|
F-statistic
|
1.11E+24
|
Durbin-Watson stat
|
2.619108
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
|
|
|
|
|
| 

