Stratégies d'optimisation de requêtes SQL dans un écosystème Hadoop( Télécharger le fichier original )par Sébastien Frackowiak Université de Technologie de COmpiègne - Master 2 2017 |

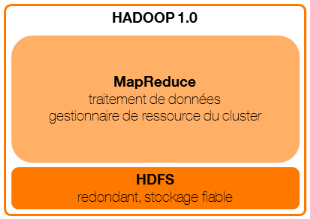
3.3 Le composant de traitement (MapReduce)3.3.1 Architecture Hadoop v1Dansla première version de Hadoop (2011),MapReduce est le composant de traitement et repose sur un cluster scalable et distribué. Il est composé d'un noeud principal exécutant le service « jobtracker » (maître) et de plusieurs noeuds exécutant un service « tasktracker » (esclave).Chaque tasktracker contient un nombre fini de « slots », ressources disponibleset spécialisées pour exécuter des tâches soit « map » (lecture et prétraitement des données) soit « reduce » (agrégation des résultats du « map »). Le jobtracker : - reçoit les demandes de jobs à exécuter, - localiseles DataNodes où se trouvent les données à traiter en interrogeant le NameNode, - localise les tasktrackers avec des slots disponibles et les plus proches des données ( annexe), - soumet les tâches« map » ou « reduce » aux tasktrackers, - coordonne l'exécution de chaque tâche. Les tasktrackers : - exécutent les tâches« map » ou « reduce » (dans le slot attribué), - communiquent périodiquement la progression des tâches qu'ils exécutent au jobtracker. En cas d'erreur, le jobtracker est ainsi capable de resoumettre une tâche sur un tasktracker différent. A ce stade du chapitre, il est à noter que les composants HDFS et MapReducereposent sur le même cluster de noeuds physiques. Ainsi, leNameNode et le tasktracker (tous deux gérant leur cluster logique respectif) s'exécutent généralement sur des noeuds physiques qui leur sont dédiés (soit un pour deux, soit un chacun) et unDataNodepartage généralement un noeud physique avec un tasktracker.
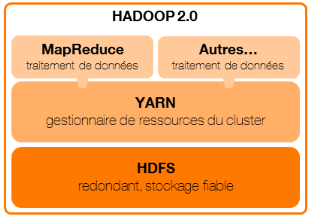
Figure 1 : architecture Hadoop 1.0 Dans cette première version, la spécialisation des slots « map » ou « reduce » rendait problématique l'allocation des ressources. Ainsi, si tous les slots « map » étaient attribués, il était impossible d'utiliser un slot « reduce » pour effectuer une tâche « map », et le traitement était donc mis en attente. C'est notamment ce point que la version 2 a corrigé. 3.3.2 Architecture Hadoop v2La seconde version de Hadoop (2012)dissocie la fonction de gestionnaire de ressources de MapReduce et propose un cadre généraliste au-dessus (API) permettant le développement d'applications de traitement distribué. YARN (YetAnother Resource Negotiator) est le gestionnaire de ressource du cluster et est composé d'un noeud principal exécutant le service « ResourceManager » (maître) et de plusieurs noeuds exécutant un service « NodeManager » (esclave). Chaque NodeManagerpeut contenirun nombre indéfini de « containers », c'est-à-dire, des ressources disponibles pour exécuter tout type de tâches. MapReduce devientainsi une application YARN, tout comme d'autres applications de traitement distribué telles que Tez et Spark. Ces applications sont des frameworks, ce qui veut dire qu'elles ne spécifient que la logique de traitement distribué et non le traitement en lui-même.Dorénavant, lorsque nous parlerons d'applications MapReduce, Tezou Spark, nous parlerons tacitement d'applications implémentant ces frameworks et décrivant un traitement précis. Quelle que soit l'application YARN, le fonctionnement sera le même : Le ResourceManager : - reçoit les demandes d'applications à exécuter, - crée un « ApplicationMaster »sur un NodeManager par application, - attribue à l'ApplicationMaster, les NodeManagers disposant d'assez de ressources disponibles pour créer les containers demandés, - priorise les demandes de ressources (file d'attente en mode FIFO par exemple). Les ApplicationMasters : - estiment la quantité de ressources requiseau regard de laconnaissance de l'application qu'ils exécutent, - effectuent les demandes de containers au ResourceManager en précisant leur localisation idéale (par exemple, au plus proche des données), - démarrent les containers sur les NodeManagers attribués par le ResourceManager Les NodeManagers : - contiennent les containers démarrés par l'ApplicationMaster, - exécutent les tâches(au sens générique du terme) demandées par leur ApplicationMaster (dans le container attribué), - communiquent périodiquement la progression des jobs qu'ils exécutent à l'ApplicationMaster. En cas d'erreur, ce dernierpeut ainsi demander d'autres containers au ResourceManager et leur affecter le job. L'avantage par rapport à Hadoop v1 est la capacité à proposer plusieurs frameworks de traitement distribué (ne répondant pas tous aux mêmes besoins), sur un même gestionnaire de ressource. En outre, l'introduction de l'ApplicationMaster permet de décentraliser la coordination de l'exécution de chaque tâche et ainsi de ne pas surcharger le ResourceManager. Enfin, la gestion par container permet d'être plus flexible dans l'attribution des ressources, du fait de leur non spécificité.
Figure 2 : architecture Hadoop 2.0 |
|