Stratégies d'optimisation de requêtes SQL dans un écosystème Hadoop( Télécharger le fichier original )par Sébastien Frackowiak Université de Technologie de COmpiègne - Master 2 2017 |

3.3.3 Le paradigme MapReduceDans ce mémoire, nous considérerons principalement les frameworks MapReduce et Tez (Hadoop v2). Le premier implémenteexactement le paradigme MapReduce que Google a décrit dans ces travaux de 2004 alors que le second se veut plus généraliste et plus souple (nous y reviendrons). Ainsi, l'écriture d'une application MapReduce consiste à décrire : - une classe « Map » qui génère un ensemble de couplesclé/valeur - une classe « Reduce » qui agrège les valeurs intermédiaires selon leur clé Pour illustrer le principe du paradigme MapReduce, prenons l'exemple du « Word Count », qui permet de compter les occurrences de chaque mot d'un jeu de données. Considérons un répertoire du HDFScontenant 3 fichiers qui feront l'objet d'un comptage d'occurrences.
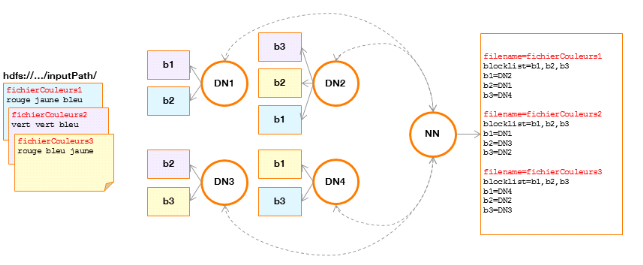
Figure 3 : répartition de trois fichiers dans un cluster HDFS Explication : Chaque fichier « fichierCouleurs » occupe1 bloc de données dupliqué 3 trois fois sur un cluster de 4 DataNodes (DN) gérés par le NameNode (NN). Leprogramme « WordCount » suivantimplémenteMapReduce : public class WordCount { public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throwsIOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throwsIOException, InterruptedException { int sum = 0; for (IntWritableval : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setNumReduceTasks(2); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } } Ce programme s'exécutera dans l'architecture Hadoop et sollicitera ses différents composants :
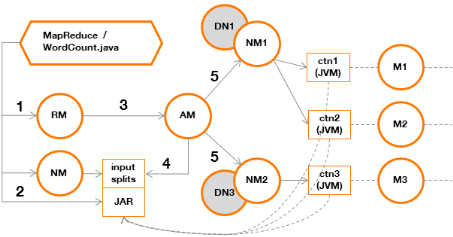
Figure 4 : phases de création des containers YARN pour l'exécution de l'application « WordCount » Explication : · Etape 1 L'application « WordCount » sollicite le ResourceManager afin de déclarer une nouvelle application YARN. · Etape 2 L'application « Wordcount » sollicite le NameNode afin d'obtenir la liste des blocs composant le ou les fichiers à traiter puis dépose les références vers ces blocs (split) dans un répertoire partagé, où sera également copié le JAR à exécuter. · Etape 3 Le ResourceManager crée un ApplicationMaster. · Etape 4 L'ApplicationMaster lit les « input splits » afin de déterminer l'emplacement des données. · Etape 5 L'ApplicationMaster crée des containers qui pourront exécuter le JAR, sur les NodeManagers les plus proches des DataNodes contenant les données (voir annexe). L'exécution du JAR contenant le programme « WordCount » et qui implémente MapReduce impliquera les phases suivantes :
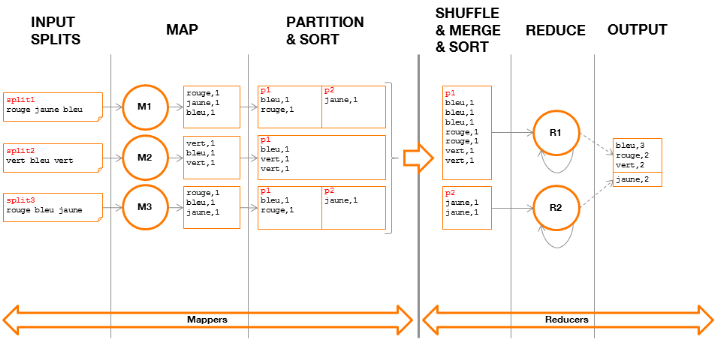
Figure 5 : phases d'exécution de l'application « WordCount » Explication : · Input Splits L'ApplicationMaster associe un split à un container. Ce dernier exécutera un et un seul Mapper sur les données pointées par le split. · Map Chaque Mapper exécutesur ses données, la méthode « Map » qui lira chaque mot séparément.Pour chaque mot lu, cette méthode générera un couple clé/valeur où la clé, correspondant au mot parcouru, sera associée à la valeur 1. Le fait de rencontrer 2 fois le mot « vert » implique que le couple {vert, 1} sera généré donc deux fois. · Partition & Sort A l'issue de la méthode « Map », chaque Mapper déversera les couples clé/valeurgénérés dans un fichier (sur le disque local du Mapper, annexe) où ils seront groupésdans des partitions suivant leur clé.Une partition contientainsi un ensemble de couples clé/valeur et, par construction,chaque clé ne peut figurer que dans une unique partition(par Mapper). Le nombre de partitions est déterminé dès le lancement de l'application en précisant le nombre de Reducers souhaité, par exemple : job.setNumReduceTasks(2) Si le nombre de Reducers n'est pas précisé, il sera fixé par défaut à 1. Par défaut, le framework MapReduce implémente le calcul de la partition pour chaque clé comme suit : (key.hashCode() &Integer.MAX_VALUE) % numReduceTasks Ce procédé permet de répartir les clés de manière équilibréelorsque leur nombre est important. · Shuffle & Merge & Sort Chaque Reducer reçoit les partitions identiques de chaque Mapper (par transfert HTTP) pour ensuiteles fusionner entre elles et leur appliquerde nouveau un tri par clé. A l'issue de cette étape, autant de fichiers que de partitions fusionnées auront été créés (sur le disque local du Reducer). Il est important de noter qu'un Reducer est ainsi garanti de traiter l'intégralité des couples clé/valeur pour une clé donnée et est donc à même d'effectuer seul le traitement de cette clé. · Reduce Chaque fichier local est traité par son Reducer qui exécutera la méthode « Reduce » pour chaque clé. Chaque valeur d'une même clé (d'une même couleur dans notre exemple),sera ainsi comptée pour obtenir le nombre d'occurrences. · Output Chaque Reducer génère un fichier comportant des couples clé/valeur et affichera sur la sortie standard son contenu. Le résultat, vu de l'utilisateur, est la concaténation de l'ensemble du contenu de ces fichiers. |
|