Conclusion
Utiliser la matrice fW a la place de
àW, nous a permis d'améliorer la
qualité de l'estimation des valeurs propres de la matrice des
produits scalaires théoriques W et cela en
réduisant le biais. De plus, le calcul de fW
s'effectue plus rapidement que celui de
àW, dans l'exemple précédent, nous
avons réalisé un calcul de 900 intégrales de
moins en estimant W par fW.
L'inconvénient de cette approche d'estimation
réside dans le fait qu'elle est approuvable seulement dans le
cas particulier oi les tailles d'échantillons sont identiques.
2.4 ACP de densites estimees parametriquement
2.4.1 Cas de donnees gaussiennes multidimensionnelles
L'auteur s'est intéressé aux données
ternaires (individus× variables× instants),
qui sont des tableaux (nt × p) indexés par
t. A chaque instant t, t ? {1,...,L}
on dispose d'un échantillon de taille nt d'un vecteur
aléatoire gaussien a p dimensions, de vecteur
moyen ut et de matrice de variance Ót. En
pratique cela revient a observer les mêmes variables
quantitatives, mais pas nécessairement sur les mêmes
individus.
Pour une description globale de ce type de
données, on applique alors la méthode décrite
précédemment, en procédant comme suit.
On associe a chaque tableau une densité de
probabilité, on obtient alors un nuage de L
densités ft, t ? {1,...,L}, et comme ces
densités sont inconnues, elles sont alors remplacées par leurs
estimations obtenus en estimant les paramêtres ut et
Ót par la méthode du maximum de vraisemblance.
Soit xt = n1t Eint 1 xt,i
et st = n1t Eint1(xt,i
- xt) (xt,i - xt), xt,i ? Rp les
estimations du maximum de vraissemblance de ut et Ót
respectivement.
Les fonctions f(nt)
t définies par:
?x ? Rp, ft
(nt)(x) =1
(2ð)p2
2 (x-xt)'
.c1(x-xt) (2.48)

1 |st|1 2 e

sont appelées les estimations
paramétriques des ft, t ?
{1,2..,L}. Elles constituent alors un nuage
de L densités de probabilité dans H =
L2(Rp). L'ACP de ces L
densités conduit a diagonaliser la matrice de terme
général [3]:
Wt,s < ft
(nt), f(ns) > =
1 1 2 (xt-xs)'
(st+ss)-1(xt-xs)
(2ð)p 2 |st +
ss|1 2 e- (2.49)
1
Considérons maintenant un échantillon
Xt,1,...,Xt,nt de la variable aléatoire parente
Xt,
t ? {1,...,L}, et soit
f(nt)
t , les estimateurs des densités parentes
ft obtenus en estimant ces
paramétres par la méthode du maximum de
vraisemblances. La convergence de l'ACP estimée
définie précédement vers l'ACP théorique
est donnée par le théorême suivant:
Théorème 2.4.1 (Boumaza, 1999)
Soient á etâ deux reels positifs,
supposons qu'il existe deux suites
(nt(n))n>1 et
(ns(n))n>1 telles que:
|
uim
n-400
|
nt(n)
n
|
= á et uim
n-400
|
ns(n)
n
|
= â
|
nous avons alors les deux rCsultats
asymptotiques suivant:
1) <f(nt)
t ,f(ns)
s > converge presque surement
vers <ft,fs> quand n tend vers
l'infini.
2) vn <f(nt)
t ,f(ns)
s > est asymptotiquement
normal.
Exemple:
Pour illuster la convergence de la méthode
définie précédemment nous avons procédé
dans
)
le cas des densités gaussiennes ft,
t E {1,...,30} de paramétres ut = (
t ( t 0 )
, Ót =
t 0 t
a une ACP de densités.
Premièrement en utilisant les densités
théoriques, deuxièmement en utilisant les estimations
par la méthode paramétrique et cela pour deux tailles
d'échantillons différentes: n = 10 et n =
40.
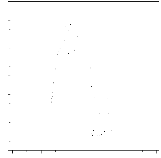
Les graphiques de la figure
7, représentant les densités sur le premier plan principal de
l'ACP normée théorique et estimée
paramétriquement, montrent que, pour une taille
d'échantillon petite ( n = 10), la forme du nuage
estimé est proche de celle du nuage réel. En
augmentant la taille d'échantillon ( n=40) cette forme se
rapproche de plus en plus vers la forme réelle.
0.9 0.7 0.5 0.3 0.1 0.1
CHAPITRE 2. ESTIMATION DE L'ACP DE DENSITES DE PROBABILITE 43
ACP normée théorique
23%
t t 0
, Ót =
t 0 t
ut =

1
2
3
4
5
6
7
9
8
10111213
30
14
15
292 8
16
2 7
17
23
24 2 6.25
18
19
20
21
22
0.600 -0.160 0.280 0.720 1.160 1.600
33%
- 0.3 0.5
- 0.7
19% ACP normée estimée, n = 10 22% ACP
normée estimée, n = 40
1.1
0.9
0.7
0.5
0.3
0.1
- 0.1
0.3
- 0.5
1
23
4
5
6
98
11
10
12
16
15
13
14
17
2930
2 8
18
19
.
2 72425
21
20 22
23
26

0.9
0.7
0.5
0.3
0.1
0.1
- 0.3
0.5
- 0.7
1
2
3
4
5
6
7
8.011
12
13 14
30
15
16
22982 72 6
25
18
17
23
19
22
21
24
20
0.600 -0.160 0.280 0.720 1.160 1.600
-0.600 -0.160 0.280 0.720 1.160
27% 1.600 31%
| 

