4. Estimation du modèle
La régression pas à pas
descendante :
Cette technique consiste à enlever une par une les
variables non significatives afin de mieux spécifier le modèle.
Après chaque retrait de variable non explicative nous effectuerons une
régression linéaire sur le logiciel RATS afin d'étudier la
nouvelle significativité des variables qui composent le modèle.
Nous utiliserons également les critères de comparaison de
modèle que sont le s, le critère de akaike et le 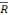 2. Nous pourrons
également commenter le R2 qui est un critère de
qualité du modèle. La régression pas à pas
descendante s'oppose à la régression pas à pas ascendante
qui n'est autre que le processus inverse : nous ajoutons les variables une
à une afin de tester leur significativité et le modèle.
Bien évidemment, nous devons suivre l'hypothèse imposée
par le test de co-intégration de Engle-Granger et prendre le
modèle en différence première. 2. Nous pourrons
également commenter le R2 qui est un critère de
qualité du modèle. La régression pas à pas
descendante s'oppose à la régression pas à pas ascendante
qui n'est autre que le processus inverse : nous ajoutons les variables une
à une afin de tester leur significativité et le modèle.
Bien évidemment, nous devons suivre l'hypothèse imposée
par le test de co-intégration de Engle-Granger et prendre le
modèle en différence première.
La significativité des variables est calculée
grâce au test de significativité de
Student :
Le test de Student est un test d'égalité d'un
coefficient à une valeur donnée. Ce test nous permet de savoir si
une variable doit rester ou non dans le modèle
(H0) ai = 0 La variable n'est pas significative au
modèle, nous pouvons l'enlever
(Ha) ai 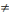 0 La variable est
significative au modèle, nous pouvons la conserver 0 La variable est
significative au modèle, nous pouvons la conserver
 i - ai i - ai
T = ------------- ~ TT - K
s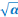 ii ii
Règle de decision:
Si le T calculé  T tabulé alors nous
acceptons l'hypothèse nulle que la variable n'est pas significative au
modèle. Par convention nous prendrons un T tabulé pour = 5% avec
un degré de liberté infini. Ainsi le T tabulé
s'élève à 1,96 ; donc si le T-Stat calculé par
le logiciel RATS < à 1 ,96 alors nous déciderons (H0). T tabulé alors nous
acceptons l'hypothèse nulle que la variable n'est pas significative au
modèle. Par convention nous prendrons un T tabulé pour = 5% avec
un degré de liberté infini. Ainsi le T tabulé
s'élève à 1,96 ; donc si le T-Stat calculé par
le logiciel RATS < à 1 ,96 alors nous déciderons (H0).
Observons ce que nous avons obtenu dans l'analyse :
Tout d'abord regardons le modèle initial,
Centered R**2 0.355859
R Bar **2 0.338049
Durbin-Watson Statistic 1.524607
s du modèle 0.22870
Nous observons un R2 et un 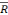 2 relativement
faibles, ceci peut s'expliquer du fait que nous étudions un
modèle en différence première. Le Durbin-Watson
étant éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est relativement
faible ce qui peut nous faire penser que le modèle n'est pas trop
mauvais mais il peut être amélioré. 2 relativement
faibles, ceci peut s'expliquer du fait que nous étudions un
modèle en différence première. Le Durbin-Watson
étant éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est relativement
faible ce qui peut nous faire penser que le modèle n'est pas trop
mauvais mais il peut être amélioré.
Etudions la significativité des variables,
Variable
|
T-Stat
|
Constant
|
-1.62850
|
DTAUX_3_MOIS
|
7.15520
|
DCPI
|
1.54236
|
DDEFICIT
|
-0.59095
|
DPRODUCTION_INDUSTRIELLE
|
0.22550
|
DMSCI_SUEDE
|
-1.89758
|
DTAUX_LONG_US
|
8.39100
|
|
Nous ne regarderons pas le T-Stat de la constante.
Sur le modèle complet en différence
première nous constatons que le DTAUX_3_MOIS et le TAUX_LONG_US sont
significatif du modèle tandis que le DCPI, le DDEFICIT, la
PRODUCTION_INDUSTRIELLE et le DMSCI_SUEDE ne sont pas significatifs.
Nous décidons d'évincer la
PRODUCTION_INDUSTRIELLE car elle est la variable la moins significative et de
retravailler le modèle.
Ainsi nous obtenons,
Centered R**2 0.355708
R Bar **2 0.340931
Durbin-Watson Statistic 1.523645
s du modele 0.22820
Nous observons que le R2 et le 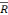 2 se sont
faiblement améliorés, le modèle est très
légèrement meilleur. Le Durbin-Watson étant
éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est plus faible que
précédemment ce qui peut nous faire penser que le modèle
est meilleur. 2 se sont
faiblement améliorés, le modèle est très
légèrement meilleur. Le Durbin-Watson étant
éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est plus faible que
précédemment ce qui peut nous faire penser que le modèle
est meilleur.
Etudions la significativité des variables,
Variable
|
T-Stat
|
Constant
|
-1.61687
|
DTAUX_3_MOIS
|
7.17727
|
DCPI
|
1.53361
|
DDEFICIT
|
-0.61973
|
DMSCI_SUEDE
|
-1.89128
|
DTAUX_LONG_US
|
8.42143
|
|
Nous ne regarderons pas le T-Stat de la constante.
Sur ce modèle en différence première
nous constatons que le DTAUX_3_MOIS et le TAUX_LONG_US sont significatif du
modèle tandis que le DCPI, le DDEFICIT et le DMSCI_SUEDE ne sont pas
significatifs.
Nous décidons d'évincer le DDEFICIT car elle
est la variable la moins significative et de retravailler le modèle.
Ainsi nous obtenons,
Centered R**2 0.354573
R Bar **2 0.342784
Durbin-Watson Statistic 1.527258
s du modele 0.22788
Nous observons que le R2 est moins bon mais que le
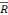 2 s'est
faiblement améliorés, le modèle est très
légèrement meilleur. Le Durbin-Watson étant
éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est plus faible que
précédemment ce qui peut nous faire penser que le modèle
est meilleur. 2 s'est
faiblement améliorés, le modèle est très
légèrement meilleur. Le Durbin-Watson étant
éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est plus faible que
précédemment ce qui peut nous faire penser que le modèle
est meilleur.
Etudions la significativité des variables,
Variable
|
T-Stat
|
Constant
|
-1.63696
|
DTAUX_3_MOIS
|
7.16570
|
DCPI
|
1.56918
|
DMSCI_SUEDE
|
-1.87712
|
DTAUX_LONG_US
|
8.47144
|
|
Nous ne regarderons pas le T-Stat de la constante.
Sur ce modèle en différence première
nous constatons que le DTAUX_3_MOIS et le TAUX_LONG_US sont significatif du
modèle tandis que le DCPI et le DMSCI_SUEDE ne sont pas significatifs.
Nous décidons d'évincer le DCPI car elle est la
variable la moins significative et de retravailler le modèle.
Ainsi nous obtenons,
Centered R**2 0.347316
R Bar **2 0.338416
Durbin-Watson Statistic 1.523152
s du modele 0.22864
Nous observons que le R2 et le 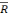 2 sont moins bon,
le modèle est donc moins bon. Le Durbin-Watson étant
éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est plus fort que
précédemment ce qui peut nous faire penser que le modèle
est moins bon. 2 sont moins bon,
le modèle est donc moins bon. Le Durbin-Watson étant
éloigné de 2 nous pouvons supposer qu'il y a de
l'auto-corrélation dans le modèle. Enfin le s est plus fort que
précédemment ce qui peut nous faire penser que le modèle
est moins bon.
Etudions la significativité des variables,
Variable
|
T-Stat
|
Constant
|
-1.15234
|
DTAUX_3_MOIS
|
7.02703
|
DMSCI_SUEDE
|
-2.06328
|
DTAUX_LONG_US
|
8.44460
|
|
Nous ne regarderons pas le T-Stat de la constante.
Sur ce modèle en différence première
nous constatons que toutes les variables sont significatives. Seulement, le
modèle est moins nous choisirons donc un modèle où l'on
exclut la DPRODUCTION_INDUSTRIELLE et le DDEFICIT, car il vaut mieux avoir un
modèle avec trop de variables explicatives que pas assez.
Pour confirmer, nous avons utilisé un test de
sélection automatique du meilleur modèle dans RATS. Celui-ci nous
confirme notre idée en se référant aux critères de
s et de akaike (voir les sorties RATS en annexe).
Nous avons vus des modèles avec des faibles
R2 et 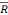 2. Ceci peut s'expliquer par le fait que nous avons prit le
modèle en différence première mais pas seulement :
cela peut être du à une instabilité des coefficients, un
oubli de variable explicative ou la présence de points aberrants. C'est
cette dernière idée que nous allons exploitée. 2. Ceci peut s'expliquer par le fait que nous avons prit le
modèle en différence première mais pas seulement :
cela peut être du à une instabilité des coefficients, un
oubli de variable explicative ou la présence de points aberrants. C'est
cette dernière idée que nous allons exploitée.
Les points aberrants :
Regardons le graphe des points aberrants,
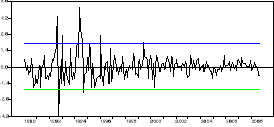
Nous constatons que la quasi-majorité des points
aberrants se trouvent dans la première moitié des années
1990. La Suède ayant connu une crise de son modèle social
à cette époque, nous pouvons comprendre ces aberrations.
Corrigeons-les : via RATS, nous définissons les
dates des points aberrants et nous les remplaçons par un dummy
(notée du). Nous constatons onze dates observées qui
sont :
Liste des points non compris entre -1.96 et +1.96 avec les
résidus divisés par s
1992:08 -1.96000 2.57705 1.96000
1992:09 -1.96000 4.22295 1.96000
1992:10 -1.96000 -3.90151 1.96000
1993:01 -1.96000 2.55136 1.96000
1994:04 -1.96000 2.12227 1.96000
1994:06 -1.96000 5.06147 1.96000
1994:07 -1.96000 3.22933 1.96000
1994:08 -1.96000 2.25449 1.96000
1994:10 -1.96000 -2.17597 1.96000
1996:02 -1.96000 2.68366 1.96000
1999:07 -1.96000 2.12541 1.96000
Ainsi nous auront onze dummies qui seront incorporés
comme étant des variables exogènes dans le modèle.
En effectuant une régression linéaire sur le
modèle avec dummies nous pouvons voir que toutes les dummies sont
significatives et donc explicatives du modèle.
Regardons le graphe du modèle corrigé,
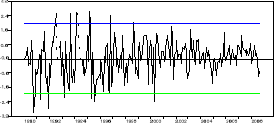
Nous constatons qu'il reste encore quelques points aberrants
mais ceux-ci n'étant pas significatifs nous ne les inclurons pas dans le
modèle.
D'ailleurs, en regardant les critères de comparaison
du modèle nous nous rendons compte que le modèle corrigé
des points aberrant est meilleur que l'ancien.
Centered R**2 0.695369
R Bar **2 0.673401
s du modèle corrigé 0.16064
Nous voyons que le R2et le 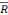 2 sont bien
meilleurs que précédemment et nous avons un s bien plus petit. En
somme, ce modèle corrigé est meilleur. 2 sont bien
meilleurs que précédemment et nous avons un s bien plus petit. En
somme, ce modèle corrigé est meilleur.
| 

