III.1.3.2. Généralités sur les
modèles de frontière
La mesure de l'efficience est initialement apparue dans les
travaux de Koopmans (1951)12 relatifs à l'analyse de la
production. Debreu (1951), fût le premier à proposer la mesure de
l'efficience technique appelée « Coefficient d'utilisation des
ressources » qui permet le calcul de la réduction proportionnelle
maximale possible de tous les entrants permettant de conserver le niveau
d'offre présent. Toutefois, c'est à Farrell (1957) qu'on doit la
définition précise de l'efficience, en dissociant ce qui est
d'origine technique de ce qui est dû à un mauvais choix par
rapport au prix des intrants, qui partant des propriétés de la
dualité mathématique, donne une interprétation en termes
de choix alternatifs. L'innovation de Farrell (1957) réside dans la
proposition d'une méthode d'estimation des frontières
d'efficacité à partir de l'observation de situations
réelles de production. Ainsi, les premières mesures de
l'efficience technique des moyens de production sont traditionnellement
attribuées à Farrell (1957)13. Au fil des
années, les définitions et les méthodes d'estimation des
scores d'efficience ont connu une certaine évolution, passant des
mesures directes, qui sont relativement pauvres,
à des mesures indirectes établies
à partir de techniques plus élaborées.
S'agissant de la première catégorie de mesures
(mesures directes), Deux approches sont
considérés; l'approche orientée vers l'input,
définie comme la possibilité de produire à partir d'une
quantité minimale d'input une quantité donnée d'output et
l'approche orientée vers l'output, définie comme la
possibilité de produire à partir d'un input donné le
maximum d'output. Selon le premier type, l'efficience est mesurée par le
montant des ressources allouées au domaine d'intervention
concerné, tel que la santé. Ainsi, on considère qu'un pays
est plus efficient s'il consacre une part de son PIB plus élevée
au secteur en question qu'un autre pays. L'approche -output considère
que ce sont les réalisations d'objectifs et non les inputs qui mesurent
le mieux l'efficience et l'effort fourni par les pouvoirs publics. Selon cette
approche, les pays qui atteignent les niveaux de santé les plus
élevés sont jugés les plus performants ; abstraction faite
de l'importance des ressources qu'ils consacrent à ces fins. Toutefois,
Selon Saoussen Ben Romdhane (2006), ces deux approches ne sont pas
satisfaisantes pour éclairer la question d'efficience puisque
12 Koopmans, T.C. 1951. «An Analysis of
Production as an Efficient Combination of Activities,» in TC Koopmans, ed,
Activity Analysis of Production and Allocation, Cowles Commission for Research
in Economics, Monograph No. 13, New York: Wiley.
13 Farrell M.J. (1957): « The measurement of
productive efficiency », Journal of the Royal Statistical Society Series,
A General120 (3), p253-281.
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 25
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
ni l'une ni l'autre ne rend compte du phénomène
de gaspillage de ressources publiques. En effet, selon Saoussen Ben Romdhane,
un gouvernement peut consacrer une part très importante de son budget
à la santé sans que les performances ne soient bonnes en raison
d'une mauvaise gouvernance se caractérisant notamment par une corruption
très répandue. Inversement, des niveaux élevés
d'indicateurs sociaux pourraient être le résultat de
dépenses publiques excessives et donc de beaucoup de gaspillage de
ressources qui auraient pu être utilisées dans les secteurs
productifs.
Au regard de ces limites, plusieurs autres techniques de
mesures dites indirectes se sont développées, mettant en
rapport les inputs et les outputs et rendant compte de l'écart entre
l'output potentiel permis par des quantités d'inputs données et
le niveau d'output effectivement atteint avec ces mêmes quantités.
Deux grandes méthodes permettent dans la littérature
économique d'évaluer l'efficience des services publics :
les méthodes paramétriques et les méthodes non
paramétriques. Toutefois, ces deux approches
dépendent de la façon dont les différents auteurs ont
estimé la fonction de production.
III.1.3.2.1. Les méthodes
paramétriques
Les méthodes paramétriques consistent à
la spécification d'une forme fonctionnelle pour la frontière
d'efficience (déterministe ou stochastique) et à
l'estimation des paramètres à l'aide des méthodes
économétriques usuelles. Ces spécifications
paramétriques de la frontière de production tiennent compte des
éventuelles aberrances et des erreurs de mesure en supposant que le
terme d'erreur a deux composantes, l'une représentant les erreurs
aléatoires et l'autre l'inefficience technique. Ainsi l'approche
paramétrique peut être regroupée en deux grandes
catégories selon que la frontière est déterministe
(méthode DFA : Deterministic Frontier
Approach) ou stochastique (méthode SFA
: Stochastic Frontier Approach). La frontière de production est
dite déterministe si tout écart observé est uniquement
dû à l'inefficacité. Si par contre, en plus de la
défaillance technique, l'on prend en compte un autre terme
aléatoire qui englobe les erreurs éventuelles de mesure, les
erreurs de la mauvaise spécification du modèle, l'omission de
certaines variables explicatives et la considération des
évènements (politique, cours mondiaux, prix des intrants, etc.)
qui peuvent influencer la production, la frontière devient alors
stochastique. Théoriquement, le recours à la méthode SFA
qui permet d'isoler le terme d'erreur purement aléatoire de celui
reflétant l'inefficacité technique de l'entreprise et devrait par
conséquent conduire à une mesure plus précise de son
efficacité technique. L'utilisation des méthodes DFA, qui
attribuent tout écart affiché par rapport à la
frontière à l'inefficacité technique, serait donc une
surestimation des niveaux d'inefficacité technique (Amara, N. et Romain,
2000).
Toutefois les deux méthodes se basent sur un modèle
économétrique du type :
Yit= a + bXit + Vi t + Ui
(3.1)
Yit désigne l'output de l'individu
i au temps t. a et b
les paramètres à estimer du modèle.
Xit un vecteur d'entrées,
Vit le terme d'erreur de moyenne nulle et
Ui une variable aléatoire représentant
l'inefficience technique spécifique à l'individu
i. Ce modèle suppose
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 26
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
que le terme d'erreur Ui est non
négatif. L'efficience technique (ET) peut être
calculée comme le ratio de la valeur attendue de l'output observé
pour l'individu i par rapport à la valeur attendue de
l'output du même individu lorsque Ui= 0. Soit
:
|
ETi=
|
E(Yit
Ui; Xit)
(3.2)
E(Yit
Ui=0; Xit)
|
Dans l'équation (3.2) le dénominateur
représente la frontière de production, puisque le terme
d'inefficience Ui est nul.
Les coefficients du modèle (3.1) peuvent être
estimés en utilisant des méthodes du maximum de vraisemblance. Le
modèle suppose entre outre que V et U
peuvent être séparés. Pour une estimation robuste,
le modèle fait également certaines hypothèses quant
à la distribution de U. Étant donné que
les U doivent être non négatifs, on suppose
généralement qu'ils sont distribués selon une loi
semi-normale et normale tronquée. Mais la frontière de production
estimée de cette façon n'englobe pas forcément toutes les
observations. Alors que la valeur attendue de l'output doit se situer sur ou
sous l'enveloppe, la valeur réelle de cet output peut se situer bien
au-dessus si l'erreur aléatoire pour cette observation est suffisamment
grande. Par ailleurs, bien que ces modèles tiennent compte des
aléas autres que l'inefficience, l'une des faiblesses de ces
modèles économétriques paramétriques est qu'ils
souffrent généralement de problèmes de
spécification. Cela est lié au fait qu'elles nécessitent
des hypothèses concernant les formes fonctionnelles et la distribution
des erreurs. Dans bien des cas, ces hypothèses ont la conséquence
d'introduire des biais dans l'analyse des résultats obtenus. Bien qu'il
existe des tests de spécification qui permettent de sélectionner
le modèle approprié, la probabilité d'avoir un
modèle inapproprié n'est jamais nulle, compte tenu du seuil de
signification imposé.
Face aux imperfections de ces méthodes, les approches
non paramétriques ont retenu l'attention des analystes de
l'efficience.
III.1.3.2.2. Les méthodes non
paramétriques
L'approche non paramétrique distingue deux
méthodes d'analyse de l'efficience telle que la Free Disposable
Hull (FDH) ou plein emploi des ressources disponibles et la
Data Envelopment Analysis (DEA) ou analyse d'enveloppement
des données.
a. La méthode Free Disposable Hull
(FDH)
L'analyse «Free Disposable Hull» est une
approche non paramétrique d'estimation des scores d'efficience
développée principalement par Deprins, Simar, et Tulkens (1984).
Cette méthode de mesure de l'efficacité ne fait pas appel
à l'inférence statistique et elle est donc déterministe.
Elle résulte d'un algorithme de classement de données, selon
le critère de la dominance en outputs et en inputs, Deprins
(1985). Aucune hypothèse n'est formulée, excepté la forte
disposition des inputs et outputs, de
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 27
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
même qu'il n'existe pas d'information sur les rendements
d'échelle. Dans cette méthode, on construit une
«enveloppe» linéaire par morceaux qui relie les points
extrêmes sur la surface de telle sorte que toutes les données
observées se situent soit sur la frontière soit en dessous.
En reprenant Antonio Afonso et Miguel St. Aubyn (2004), on
peut prendre un exemple concret.
Tableau 3.1 : Un exemple pour illustrer
la notion d'efficience selon la FDH.
|
Résultats (output)
|
Dépenses (input)
|
|
Pays A
|
65
|
800
|
|
Pays B
|
66
|
950
|
|
Pays C
|
75
|
1000
|
|
Pays D
|
70
|
1300
|
Source : Afonso et Aubyn (2004).
D'après ce tableau, le plus bas niveau de
dépenses est réalisé par le pays A correspondant
également au plus bas niveau d'output. Par contre, le plus haut niveau
de dépenses (1300) consenti par le pays D n'a pas donné le plus
haut niveau d'output (75) qui est obtenu par le pays C qui n'a
dépensé que 1000.
Selon l'approche FDH, les pays A, B et C seront
considérés comme efficients et vont être de ce fait
situés sur la courbe de la frontière d'efficience alors que le
pays D sera le seul pays considéré comme pays inefficient et
gaspilleur de ressources dans la mesure où ce dernier bien qu'ayant le
nombre d'inputs le plus élevé, n'a pas produit le plus grand
nombre d'output. Figure (3.3).
Figure 3.3 : Représentation de la
fontière d'efficience par l'approche FDH
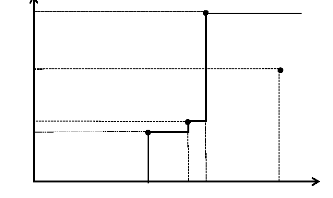
A
Y
75
D
70
B
X
800 950 1000 1300
C
66
65
Source: Afonso et Aubyn (2004).
La technique FDH n'impose pas de nombreuses restrictions
à la technologie de production, tel est son avantage principal.
Toutefois, elle présente aussi plusieurs inconvénients.
Premièrement, dans la mesure où plusieurs observations se situent
sur la
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 28
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
frontière, la technique FDH ne permet ainsi qu'un
classement partiel; puisque les observations situées sur la
frontière sont tout aussi efficientes. Deuxièmement, aucune
distinction n'est faite entre les facteurs aléatoires qui pourraient
affecter la production et l'inefficience réelle. L'analyse n'est donc
pas robuste vis-à-vis des aberrances ou des données
extrêmes. Face à ces limites, d'autres approches telles que la
Data Envelopment Analysis (DEA) ont été
développées.
b. La méthode DEA (Data
Envelopment Analysis)
La méthode DEA est une approche non paramétrique
qui permet d'évaluer la performance des organisations (appelées
decision-making units : DMU14) qui transforment des ressources
(inputs) en prestations (outputs). Elle est adaptée tant aux entreprises
du secteur privé qu'aux organisations du secteur public. Elle peut
également être appliquée à des entités comme
des villes, des régions, des pays, etc. La méthode DEA a
été développée par Farrell (1957) et
popularisée par Charnes Cooper et Rhodes (1978)15 pour
évaluer l'efficience d'un programme fédéral
américain d'allocation de ressources aux écoles (« Programme
Follow Through»), puis par Banker Charnes et Cooper, (1984)16.
L'utilisation de la méthode DEA s'est ensuite
généralisée dans les autres organisations
publiques (hôpitaux, services sociaux,
offices de chômage,
usines électriques, unités de police, corps de l'armée,
usines de traitement des déchets, entreprises de transports publics,
entreprises forestières, bibliothèques, musées,
théâtres, etc.) et dans le secteur privé (banques,
assurances, commerces de détail, etc.).
La méthode DEA est équivalente à un
processus d'optimisation sous contrainte qui utilise la programmation
linéaire. Basée sur l'approximation intérieure de la
technologie de production d'une unité de décision, seulement deux
hypothèses sont requises : l'hypothèse de libre disposition
d'inputs et d'outputs et celle de combinaison convexe. La première
stipule que la production d'une quantité donnée d'outputs
nécessite une quantité donnée d'inputs ou une
quantité supérieure à celle-ci, alors que la seconde
indique que si la quantité d'input X1 permet de produire la
quantité d'output Y1 et que X2 permet de produire Y2, alors toute
combinaison convexe de X1 et X2 permet de produire la même combinaison
convexe de Y1 et Y2. Ces deux hypothèses suffisent à estimer la
frontière des possibilités de production des DMU
étudiées et à exprimer l'inefficience de chacune d'entre
elles, par sa position par rapport à la frontière.
14 Une DMU (Decisions Making Units) ou unité
de décision est définie de manière générale
comme une entité dont la mission principale est de convertir les inputs
en outputs et dont la performance est à évaluer. Dans notre
étude, les DMU sont composées des pays sur lesquels porte notre
échantillon.
15 Charnes, Cooper et Rhodes (1978) ont
généralisé et rendu opérationnelles les
propositions de Farrell sous l'hypothèse des rendements d'échelle
constants, en permettant l'estimation de la fonction de production par une
courbe enveloppe formée des segments de droite joignant les
entités efficientes d'où la dénomination Data Envelopment
Analysis.
16 Banker, Charnes et Cooper (1984) ont
étendu la mesure de l'efficience de Charnes, Cooper et Rhodes (CCR) aux
rendements d'échelle variables en introduisant une contrainte
additionnelle qui permet en principe de décomposer l'inefficience
technique globale obtenue à partir du modèle CCR entre
inefficience technique pure et inefficience d'échelle.
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 29
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
Le score d'efficience de chaque organisation est
calculé par rapport à une frontière d'efficience. Les
organisations qui se situent sur la frontière ont un score de 1 (ou
100%). Les organisations qui sont localisées sous la frontière
ont un score inférieur à 1 (ou 100%) et disposent par
conséquent d'une marge d'amélioration de leur performance.
Relevons qu'aucune organisation ne peut se situer au-dessus de la
frontière d'efficience car il n'est pas possible d'obtenir un score
supérieur à 100%. Les organisations situées sur la
frontière servent de référence (ou de benchmarks) aux
organisations inefficientes. Ces références sont associées
aux best practice observables. La méthode DEA est par conséquent
une technique de benchmarking.
La méthode DEA a évolué depuis les
premiers travaux de la fin des années soixante-dix. Sa pratique s'est
considérablement développée. Les applications continuent
à devenir plus sophistiquées et à une grande
échelle deux modèles de base sont utilisés en DEA,
aboutissant chacun à l'identification d'une frontière
d'efficience différente :
- Le premier modèle fait
l'hypothèse que les organisations évoluent dans une situation de
rendements d'échelle constants (modèle Charnes Cooper et Rhodes,
1978 ou modèle CCR ou modèle
CRS). Il est approprié lorsque toutes les organisations ont
atteint leur taille optimale. Relevons que l'hypothèse de ce
modèle est (très) ambitieuse. Pour opérer à leur
taille optimale, les organisations doivent évoluer dans un environnement
de concurrence parfaite, ce qui est rarement le cas. Le modèle CRS
calcule un score d'efficience appelé constant returns to scale technical
efficiency (CRSTE).
- Le second modèle fait
l'hypothèse que les organisations évoluent dans une situation de
rendements d'échelle variables (modèle Banker, Charnes et Cooper,
1984 ou modèle BCC ou modèle
VRS). Il est approprié lorsque les organisations
n'opèrent pas à leur taille optimale. Cette hypothèse est
privilégiée dans les cas de concurrence imparfaite ou de
marchés régulés. Le modèle VRS calcule un score
d'efficience appelé variable returns to scale technical
efficiency(VRSTE).
Par ailleurs que l'on soit dans un modèle CRS ou VRS,
la méthode DEA distingue deux types d'orientations :
l'orientation input et l'orientation
output. Dans le modèle en input, l'objectif est de
produire les outputs observés avec un niveau de ressources minimum. En
revanche, dans une orientation output, l'attraction n'est plus centrée
sur la minimisation des ressources en inputs, l'objectif étant de
maximiser la production d'outputs tout pour un niveau donné de
ressources.
La frontière d'efficience est différente selon
un modèle CRS ou VRS. Cependant, à l'intérieur de chacun
de ces modèles, la frontière ne sera pas affectée par une
orientation input ou output. Autrement dit, dans un modèle CRS ou VRS la
frontière d'efficience sera exactement la même à
orientation input ou output ; les organisations situées sur la
frontière dans le cas d'une orientation input seront également
situées sur la frontière dans le cas d'une orientation output. En
outre, dans un modèle CRS, les scores d'efficience technique sont les
mêmes selon une orientation input ou output. Mais ces scores sont
différents selon l'orientation retenue dans un modèle VRS.
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 30
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
Coelli et Perelman (1996, 1999) relèvent cependant que,
dans de nombreuses situations, le choix de l'orientation du modèle
(input ou output) n'impactera les scores d'efficience technique que de
manière mineure dans un modèle VRS.
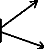
Le graphique ci-dessous résume de façon
synthétique ces deux modèles de base.
Figure 3.4 : Classification des
modèles DEA
|
Orienté inputs
|
|
CCR-INPUT
|
|
|
|
|
Rendements d'échelle constants
Orienté outputs
CCR-OUTPUT
|
Orienté inputs
|
BCC-INPUT
|
|
Rendements d'échelle variables
|
|
|
|
BCC-OUTPUT
|
|
Orienté outputs
|
Source: Auteur
b-1) Frontière d'efficience CRS
Pour comprendre le fonctionnement « mécanique
» de la méthode DEA de manière intuitive, reprenons comme
António Afonso et Miguel St. Aubyn (2004) l'exemple du tableau
précédent (tableau 3.1).
Y
75
70
66
65
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
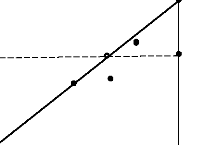
Figure 3.5 : Frontière
d'efficience DEA sous l'hypothèse des rendements d'échelle
constants
DCRS-I
D
DCRS-o
C
S
A
B
T
Frontière d'efficience CRS
800 950 1000 X
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 31
Source: Afonso et Aubyn (2004).
La Figure (3.5) représente la frontière
d'efficience sous hypothèse de rendements d'échelle constants
(frontière d'efficience CRS). La frontière d'efficience CRS part
de l'origine et passe par le pays A. Ce pays est l'observation avec la pente la
plus raide parmi les quatre pays. Autrement dit, il présente le ratio de
productivité « outputs par input» le plus élevé
(65 / 800 = 0,0815). Le pays A est sur la frontière d'efficience ; il
est efficient à 100%. Les pays B,C,D sont situés sous la
frontière. Leurs scores d'efficience respectifs sont inférieurs
à 100%. La méthode DEA considère que le l'ensemble des
possibilités de production est limité par la frontière.
Autrement dit, il n'est pas possible pour une organisation de se situer
au-delà de la frontière, et par conséquent d'obtenir un
hypothétique score d'efficience supérieur à 100%. La
méthode DEA calcule par conséquent des scores d'efficience
relatifs et non absolus. Les organisations situées sur la
frontière sont efficientes à 100% car elles sont les plus
efficientes de l'échantillon17.
La Figure (3.5) illustre également la manière
dont la méthode DEA calcule les scores d'efficience. L'exemple du pays D
est décrit ci-dessous :
- Dans le cas d'une orientation input, le
score d'efficience de D est égal à la distance SDCRS-I
divisée par la distance SD. DCRS-I est la projection du point
D sur la frontière d'efficience (sous hypothèse de rendements
d'échelle constants-CRS-et avec une orientation input -I-). Relevons
qu'il est aisé de calculer les scores d'efficience en utilisant une
règle et en mesurant les distances directement sur le graphique. Le
score de D est de 60,5%. Cela signifie que le pays D pourrait réduire le
nombre de ses inputs de 39,5% (100 - 60,5) tout en continuant à produire
le même nombre d'outputs (66).
17 Soulignons que les organisations efficientes
à 100% pourraient, selon toute vraisemblance, encore s'améliorer
en augmentant leur productivité.
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 32
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
- Dans le cas d'une orientation output, le
score d'efficience de D est égal à la distance TD divisée
par la distance TDCRS-O. DCRS-O est la projection du point D sur la
frontière d'efficience (sous hypothèse de rendements
d'échelle constants-CRS-et avec une orientation output-O-). Le score
d'efficience de D est de 60,5%, comme dans le cas de l'orientation input. Cela
signifie que le pays D pourrait augmenter le nombre d'outputs de 39,5% (100 -
60,5) avec le même nombre d'inputs (1300).
b-2) Frontière d'efficience VRS
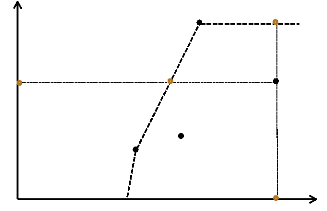
La Figure (3.6) représente la frontière
d'efficience sous hypothèse de rendements d'échelle variables
(frontière d'efficience VRS). La frontière d'efficience VRS
présente la particularité d'épouser la forme du nuage de
points, autrement dit d'envelopper toutes les observations. Les pays A et C
sont situés sur la frontière. Ils obtiennent tous un score
d'efficience de 100%. Les pays B et D sont situés sous la
frontière. Leurs scores d'efficience respectifs sont inférieurs
à 100%. La Figure (3.6) illustre également la manière dont
la méthode DEA calcule les scores d'efficience. L'exemple du pays D est
décrit ci-dessous :
Figure 3.6 : Frontière
d'efficience DEA sous l'hypothèse des rendements d'échelle
variables
D
DVRD-I
70
A
DVRD-O
C
Frontière d'efficience VRS
U
B
V
800 950 1000
X
Y
75
66
65
Source: Afonso et Aubyn (2004).
- Dans le cas d'une orientation input, le
score d'efficience de D est égal à la distance UDVRS-I
divisée par la distance UD. DVRS-I est la projection du point
D sur la frontière d'efficience (sous hypothèse de rendements
d'échelle variables-VRS-et avec une orientation input -I-). Relevons
qu'il est aisé de calculer les scores d'efficience à l'aide d'une
règle en mesurant les distances directement sur le graphique. Le score
de D est de 62%. Cela signifie que le pays D pourrait réduire le nombre
de ses inputs de 38% (100 - 62) tout en continuant à produire le
même nombre d'outputs (70).
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 33
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
- Dans le cas d'une orientation output, le
score d'efficience de D est égal à la distance VD divisée
par la distance VDVRS-O. DVRS-O est la projection du point D sur la
frontière d'efficience (sous hypothèse de rendements
d'échelle variables -VRS-et avec une orientation output-O-). Le score de
D est de 67%. Cela signifie que le pays D pourrait augmenter le nombre de ses
résultats de 33% (100 - 67) avec le même nombre d'inputs
(1300).
b-3) Frontières d'efficience DEA et
FDH
António Afonso et Miguel St. Aubyn (2004) ont
montré que, du fait de la convexité de la frontière
imposée dans l'approche DEA, cette méthode se
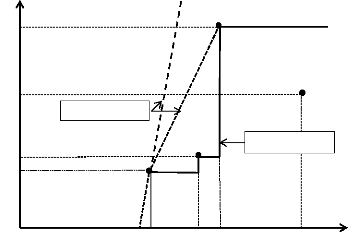
révèle plus efficace que la FDH (confère Figure 3.7).
L'estimation de la frontière d'efficience DEA révèle que
le pays B qui était efficient selon la FDH ne l'est plus sous la DEA et
donc seuls les pays A et C continuent d'être efficients.
Figure 3.7 : Comparaison
frontières d'efficience FDH et DEA
Y
C
X
800 950 1000 1300
75
Rendements d'échelle constants
Rendements d'échelle variables
D
70
Frontière DEA
Frontière FDH
66
B
65
A
Source: Afonso et Aubyn (2004).
La Figure (3.7) montre donc qu'un pays qui est jugé
efficient sous la FDH ne l'est pas toujours sous la DEA, alors qu'un pays
efficient sous la DEA le sera sous la FDH. Par construction, l'ensemble de
production défini par la FDH est donc inclus dans l'ensemble de
production DEA. Ainsi, il est possible de déduire la frontière
FDH à partir de la frontière DEA. Les principaux avantages de
l'analyse DEA, sont qu'elle n'impose que de faibles restrictions à la
représentation de la technologie de production, et qu'elle permet une
comparaison des niveaux d'efficacité entre les entités. La seule
hypothèse faite est qu'il est possible, avec les mêmes
technologies de production, de mesurer une baisse des valeurs ajoutées
tout en maintenant le niveau d'intrants et d'augmenter les apports en intrants
tout en maintenant la valeur ajoutée.
Mémoire rédigé par AJOULIGA DJOUFACK
Hermann Blondel 34
Efficience des dépenses publiques de santé et
croissance économique en zone CEMAC
En définitive, la différence fondamentale entre
l'approche paramétrique et l'approche non paramétrique
réside dans le fait que la première se base sur un modèle
statistique explicite concrétisé par l'utilisation d'une forme
fonctionnelle et d'une loi de probabilité particulière ; ce qui
n'est pas le cas dans l'approche non paramétrique. Il est alors
intéressant de se demander quel est l'effet de l'utilisation d'une forme
fonctionnelle ? En utilisant moins d'informations que dans l'approche
paramétrique, les résultats dans l'approche non
paramétrique devraient être moins précis mais il y a le
risque d'influencer les résultats en imposant une forme fonctionnelle
qui n'est pas la plus appropriée. L'arbitrage entre imposer plus de
structures et plus de flexibilité est un problème permanent dans
la mesure où plus de contraintes dans un modèle entraîne de
meilleures estimations ; et des hypothèses fortes génèrent
des résultats forts pourvu. Le choix entre les deux approches n'est donc
pas toujours facile. Bosman et Frecher (1992) recommandent de se baser sur des
informations que l'on a de la technologie disponible et des objectifs
recherchés Ces auteurs pensent que, lorsque l'on a une idée assez
nette de ce qu'est la technologie sous-jacente, cas du secteur agricole et des
branches manufacturières par exemple, l'estimation
économétrique des frontières de production
paramétrique a un sens. Par contre, lorsqu'il s'agit d'une unité
de décision dont l'activité est la production des services, une
approche non paramétrique semble d'avantage appropriée, du fait
qu'elle ne repose sur aucune hypothèse explicite concernant la
technologie et qu'elle s'applique à des activités ayant plusieurs
outputs et plusieurs inputs.
| 

