L'impact De La Corruption Sur L'IDE:Application Sur Quelques Pays MENA( Télécharger le fichier original )par Bilel Ben Nahia Faculté de Sciens Economiques et Gestion de Sfax - Master en sciences économiques 2008 |

Section 3 : Etude empirique de la relation Corruption-IDE : modèle de Rahman A., Kisunko G. et Kapoor K. (2000)Au cours de cette section on va essayer de faire une étude empirique afin de vérifier l'hypothèse selon laquelle la corruption dans le pays hôte réduit les flux de l'investissement direct étrangers. Rahman, Kisunko et Kapoor (2000) ont essayé de déterminer l'effet de la corruption sur la croissance, l'investissement domestique et l'IDE. Ils ont eu recours au modèle de Mauro (1995) et l'ont enrichit par l'étude de la relation corruption-IDE. J'ai essayé d'effectuer des modifications sur ce modèle en remplaçant la variable « the pupil-teacher ratio in secondary schools » par la variable N ATRES qui désigne les ressources naturelles du pays hôte, important déterminant de l'IDE. D'après Johnson et Dahlström (2007), cette variable est calculée à partir de ratio exportation des resources naturelles / PIB. J'ai aussi transformé le TI pour que les hautes figures correspondent à une grande quantité de corruption. Cette transformation est telle que CORRUPT = 11 - TI. On va essayer de vérifier notre hypothèse en utilisant leur modèle modifié. Donc l'équation à estimer est la suivante: IDE / PIB = â0 + â1 Log (PNB / tête) + â2 Log (Taux d'inscription aux écoles primaires) + â3 (Ratio Exportation / PIB) + â4 (Indice de la corruption) + â5 (Ouverture de l'économie) + ° Nous allons, dans ce qui suit, procéder à une validation empirique de la relation corruption-IDE. Notre analyse se caractérise par le suivi de 5 pays dans le temps, sur la période 1996-2006 ; il s'agit des données individuelles-temporelles qui nous permettent de réaliser une estimation en données de Panel. Le recours aux données de Panel nous permet d'utiliser l'information statistique sous une double dimension : individuelle et temporelle. Il s'ensuit donc un gain d'efficacité en matière de précision des estimations. On va essayer de faire notre analyse de la relation corruption-IDE en étudiant en premier lieu l'effet direct de la corruption sur l'IDE et en second lieu l'effet indirect en utilisant une variable comme canal de transmission.
· La variable dépendante (à expliquer): Le ratio IDE / PIB sur la période 1996-2006. Le fait de diviser l'IDE par le PIB pour chaque pays nous permet d'ajuster le niveau d'investissement à la taille de l'économie. · Les variables indépendantes (explicatives): - Log du revenu national brut par tête sur la période 1996-2006. Cette variable mesure le niveau de développement. - Taux d'inscription aux écoles primaires sur la période 1996-2006. Cette variable mesure la quantité du capital humain. - Ratio exportation / PIB sur la période 1996-2006. Cette variable mesure l'abondance des ressources naturelles dans le pays hôte. - L'indice de Transparency International de la corruption sur la période 1996-2006. - Ouverture de l'économie: cette variable est mesurée par le taux de l'ouverture annuel sur la période 1996-2006. Le taux de l'ouverture est calculé comme suit: (X+M) / PIB Avec X: les exportations des biens et services en dollar constant (2000) M: les importations des biens et services en dollar constant (2000) PIB: le PIB en dollar constant (2000) L'indice de Transparency International de la corruption est obtenu par Internet sur la liste de cette organisation ( www.transparency.org) Toutes les autres variables sont obtenues de World Indicators Development de la Banque Mondiale (CD-ROM 2007). Notre échantillon comporte 5 pays de la région MENA (Egypte, Israel, Jordanie, Maroc et la Tunisie). Ce sont tous des pays pour lesquels toutes les variables sont disponibles. 3.2.2- Résultats et interprétation : L'estimation de notre relation statique dépend des tests de spécifications qui correspondent en fait aux trois tests de Fisher. Il s'agit ici de déterminer la manière dont doit être spécifier notre modèle, si tant que l'hypothèse de Panel puisse être acceptée. Nous verrons que notre analyse repose alors sur la notion d'homogénéité des paramètres de notre modèle. Ces tests de spécification visent ainsi à porter un diagnostic sur l'éventuelle nécessité d'intégrer une dimension hétérogène et sur la manière dont cette hétérogénéité doit être spécifiée. Si, l'hétérogénéité est détectée seulement au niveau des constantes, ce modèle à effets individuels est estimé à partir des techniques Within ou Least squares Dummy variables (LSDV), si ces constantes sont fixes ou par les procédures Between ou Moindres carrés généralisées si, ces effets sont aléatoires. Pour savoir quel modèle, parmi les modèles à effets aléatoires et effets fixes, doit-on retenir. Nous utiliserons le test de spécification standard d'Hausman (1978). Dans cette section, nous étudierons dans un premier paragraphe les tests de spécifications, pour mieux spécifier notre modèle de base. Dans un second paragraphe, nous proposerons les techniques des estimations appropriées afin d'observer la relation statique corruption-IDE. Enfin, nous utiliserons le test de Hausman (1978), si notre modèle est spécifié à partir d'un panel avec effets fixes. 3.2.2.1- Les tests de spécifications L'estimation statique de la relation IDE-corruption pour un échantillon de ces cinq pays de la région MENA durant les années 1996-2006 nécessite dans une première étape de vérifier la spécification homogène ou hétérogène du processus générateur de données. Sur le plan économétrique, cela revient à tester l'égalité des coefficients de notre modèle théorique étudié dans la dimension individuelle. Sur le plan économique, les tests de spécification reviennent à déterminer si l'on est en droit de supposer que la relation IDE-corruption est parfaitement identique pour tous ces pays, ou au contraire, s'il existe des spécificités propres à chaque pays. Notre modèle théorique peut être écrit sous la forme suivante :
Les innovations - Les cinq constantes - Les cinq constantes et les coefficients sont différents selon le pays. D'où, cette fonction est hétérogène pour ces pays et on rejette la structure de panel dans ce cas. - Les cinq constantes sont identiques - Les coefficients sont identiques pour tous les pays
Pour discriminer ces différentes configurations et pour s'assurer du bien-fondé de la structure de panel pour notre modèle théorique, il convient d'adopter une procédure de tests d'homogénéités emboîtés. La procédure générale du test présentée dans Hsiao (1986) est décrite par les quatre étapes suivantes : Dans une première étape, on teste l'hypothèse d'une structure parfaitement homogène (constantes et coefficients homogènes) :
On utilise alors une statistique de Fisher pour tester ces
(k+1)(N-1) restrictions linéaires. Si, l'on suppose que les
résidus Si l'on accepte l'hypothèse nulle
Si en revanche, on rejette l'hypothèse nulle, on passe
à une seconde étape qui consiste à déterminer si
l'hétérogénéité provient des
coefficients La seconde étape consiste à tester pour tous les
individus des k composants des coefficients
Sous l'hypothèse nulle, on n'impose ici aucune
restriction sur les constantes individuelles En revanche si, on accepte l'hypothèse nulle d'homogénéité des coefficients, on retient la structure de panel et l'on cherche alors à déterminer dans une troisième étape si les constantes ont une dimension individuelle. La troisième étape de la procédure consiste à tester l'égalité des N constantes individuelles, sous l'hypothèse de coefficients communs à tous les individus :
Sous l'hypothèse nulle, on impose
Dans le cas où l'on accepte l'hypothèse
nulle Le premier tableau résume les tests d'homogénéités pour notre variable expliquée.
La première remarque de ce tableau est que tous les coefficients de l'IDE sont identiques pour l'échantillon de ces pays, malgré que les effets invariants de l'IDE sont hétérogènes entre ces pays. Par contre, les coefficients de celle-ci sont identiques. A partir de ces résultats, nous pouvons conclure que notre modèle peut être spécifié comme un panel avec effets individuels. La seconde remarque concerne l'origine de l'hétérogénéité de l'IDE qui peut être expliquée par les effets moyens des variables non explicatives. Cette hétérogénéité est dût, par exemple, aux caractéristiques économiques de chaque pays, le degré de l'ouverture de l'économie et l'inégalité des ressources naturelles acquises dans chaque pays de cet échantillon. 3.2.2.2- Estimation statique de la relation IDE-corruption : Les tests de spécifications montrent que notre modèle théorique peut être formalisé comme un panel avec des effets individuels. Afin d'estimer cette relation pour ces pays nous utiliserons les techniques Within et GLS (MCG). Le deuxième tableau récapitule ces deux procédures d'estimations dans l'observation de notre relation statique.
L'estimation de l'IDE par ces deux procédures d'estimations montre que l'effet de la corruption est négatif et significatif dans le cas de l'estimation Within, alors qu'il est négatif mais non significatif dans la deuxième technique d'estimation (GLS). Afin de comparer ces deux procédures, nous utiliserons la statistique d'Hausman (1978). Le test de spécification d'Hausman est un test général qui peut être appliqué à de nombreux problèmes de spécification en économétrie. Mais, son application la plus répondue est celle des tests de spécification des effets individuels en panel. Il sert ainsi à discriminer les effets fixes et aléatoires. L'idée générale de ce test est à la fois simple et géniale. Ce test cherche à étudier l'éventualité d'une corrélation ou d'un défaut de spécification. Admettons que l'on dispose de deux types d'estimateurs pour nos paramètres du modèle de base. Le premier estimateur est supposé être l'estimateur non biaisé à variance minimale sous l'hypothèse nulle de spécification correcte du modèle (absence d'une corrélation). En revanche, sous l'hypothèse alternative de mauvaise spécification, cet estimateur est supposé être biaisé. Les deux hypothèses d'Hausman peuvent être spécifiées comme suit :
Hausman (1978) préconise de fonder son test de spécification sur la statistique suivante :
Sous l'hypothèse nulle de spécification correcte, cette statistique est asymptotiquement distribuée selon un khi-deux à k degrés de liberté. Ainsi, sous l'hypothèse nulle, ce modèle théorique peut être spécifié avec des effets individuels aléatoires et on doit retenir l'estimateur des MCG (l'estimateur BLUE). Par contre, sous l'hypothèse alternative, le modèle doit être spécifié avec des effets individuels fixes et l'on doit retenir l'estimateur Within ou LSDV (l'estimateur non biaisé). Le troisième tableau récapitule le test d'Hausman (1978) pour notre modèle.
La statistique H est supérieure au seuil 1%, on rejette l'hypothèse nulle et l'on privilégie l'adoption d'effets individuels fixes et nous utilisons l'estimateur Within afin d'obtenir des estimateurs plus consistants. Conclusion :Dans ce chapitre, nous avons tenté de valider empiriquement la relation qui peut exister entre la corruption et l'investissement direct étranger. En théorie, cette relation fait l'objet d'un débat, qui porte sur le signe de cette relation : est ce qu'elle de nature négative (grabbing hand) ou positive (helping hand) ? Pour répondre à cette question, nous avons eu recours au modèle élaboré par Rahman, Kisunko et Kapoor (2000) un peu modifié. Notre validation confirme le signe négatif de la relation ; donc la corruption joue un rôle de « grabbing hand » pour l'investissement direct étranger, d'ailleurs c'est le résultat confirmé par la plupart des travaux empiriques. En plus, nous n'avons trouvé aucun appui empirique pour l'argument de « helping hand » avancé pour expliquer le signe positif de la relation corruption-investissement direct étranger. * 7 A l'exception de la variance des innovations que l'on supposera identique pour tous les individus. * 8 |
| |||||||||||||||||||||||||||||||||||


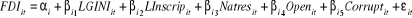 (1)
(1)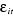 sont supposées être iid de moyenne nulle et de variance
égale à
sont supposées être iid de moyenne nulle et de variance
égale à . Ainsi, on suppose que les constantes
. Ainsi, on suppose que les constantes  de notre modèle peuvent différer dans la dimension
individuelle7
de notre modèle peuvent différer dans la dimension
individuelle7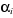 et les coefficients
et les coefficients 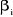 sont identiques :
sont identiques : 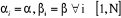 . On qualifie alors notre modèle par un panel homogène et
la relation IDE-corruption est identique pour les pays choisi.
. On qualifie alors notre modèle par un panel homogène et
la relation IDE-corruption est identique pour les pays choisi.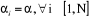 ; tandis que les coefficients sont différents selon le
pays. Dans ce cas, tous les coefficients du modèle, à l'exception
des constantes, sont différents selon le pays. On a donc cinq
différentes équations à estimer.
; tandis que les coefficients sont différents selon le
pays. Dans ce cas, tous les coefficients du modèle, à l'exception
des constantes, sont différents selon le pays. On a donc cinq
différentes équations à estimer.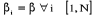 ; tandis que les constantes sont différentes selon le pays.
On obtient un modèle avec des effets individuels.
; tandis que les constantes sont différentes selon le pays.
On obtient un modèle avec des effets individuels.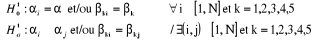
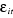 sont indépendamment distribués dans les dimensions i et
t, et suivent une loi normale d'espérance nulle et de variance finie
sont indépendamment distribués dans les dimensions i et
t, et suivent une loi normale d'espérance nulle et de variance finie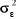 , alors cette statistique suit une distribution de Fisher avec
(k+1)(N-1) et NT-N(k+1) degrés de liberté. Les conclusions de ce
test sont les suivantes :
, alors cette statistique suit une distribution de Fisher avec
(k+1)(N-1) et NT-N(k+1) degrés de liberté. Les conclusions de ce
test sont les suivantes :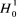 d'homogénéité, on obtient alors un modèle
de panel totalement homogène, c'est-à-dire la relation
IDE-corruption est identique pour l'ensemble des cinq pays de
l'échantillon. D'où le modèle théorique est typique
pour cet échantillon et peut être formalisé comme
suit :
d'homogénéité, on obtient alors un modèle
de panel totalement homogène, c'est-à-dire la relation
IDE-corruption est identique pour l'ensemble des cinq pays de
l'échantillon. D'où le modèle théorique est typique
pour cet échantillon et peut être formalisé comme
suit :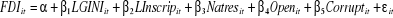 (2)
(2)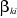 .
.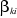 .
.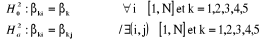
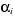 . De la même façon, on construit une statistique de Fisher
pour tester ces (N-1)k restrictions linéaires. Toujours sous
l'hypothèse d'indépendance et de normalité des
résidus, cette statistique suit une loi de Fisher avec (N-1)k et
NT-N(k+1) degrés de liberté. Si, l'on rejette l'hypothèse
nulle
. De la même façon, on construit une statistique de Fisher
pour tester ces (N-1)k restrictions linéaires. Toujours sous
l'hypothèse d'indépendance et de normalité des
résidus, cette statistique suit une loi de Fisher avec (N-1)k et
NT-N(k+1) degrés de liberté. Si, l'on rejette l'hypothèse
nulle 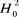 d'homogénéité des coefficients, on rejette aussi
la structure de panel, puisque, au mieux, seules les constantes
d'homogénéité des coefficients, on rejette aussi
la structure de panel, puisque, au mieux, seules les constantes 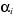 peuvent être identiques entre les pays.
peuvent être identiques entre les pays.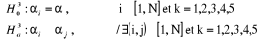
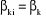 . Sous l'hypothèse d'indépendance et de normalité
des résidus, on construit une statistique de Fisher pour tester ces N-1
restrictions linéaires. Cette statistique suit une loi de Fisher avec
(N-1)k et N(T-1)-k degrés de liberté. Si, l'on rejette
l'hypothèse nulle d'homogénéité des constantes, on
obtient alors un modèle panel avec effets individuels, qui
s'écrit sous la forme standard suivante :
. Sous l'hypothèse d'indépendance et de normalité
des résidus, on construit une statistique de Fisher pour tester ces N-1
restrictions linéaires. Cette statistique suit une loi de Fisher avec
(N-1)k et N(T-1)-k degrés de liberté. Si, l'on rejette
l'hypothèse nulle d'homogénéité des constantes, on
obtient alors un modèle panel avec effets individuels, qui
s'écrit sous la forme standard suivante :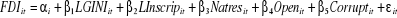 (3)
(3)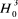 , on retrouve alors une structure de panel totalement homogène.
Ce test ne sert qu'à confirmer ou infirmer les conclusions du test
, on retrouve alors une structure de panel totalement homogène.
Ce test ne sert qu'à confirmer ou infirmer les conclusions du test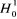 , étant donné que le fait de réduire le nombre de
restrictions linéaires permet d'accroître la puissance du test du
Fisher.
, étant donné que le fait de réduire le nombre de
restrictions linéaires permet d'accroître la puissance du test du
Fisher. 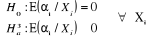 : la matrice des variables explicatives.
: la matrice des variables explicatives.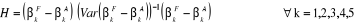 8
8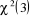 = 41.14 (0.0000)
= 41.14 (0.0000)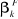 est le vecteur des estimateurs Within et
est le vecteur des estimateurs Within et 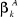 est le vecteur des estimateurs GLS..
est le vecteur des estimateurs GLS..