4.1.3 Identification du modèle d'estimation et
présentation des résultats obtenus
L'identification du modèle a` estimer passe au
pr'ealable par une v'erification de l'existence ou non de relations de
coint'egration entre les variables. A cet effet, nous utilisons l'approche du
test de coint'egration de Johansen, appliqu'e dans ce type d'exercice.
Test de cointégration au sens de Johansen
Pour appliquer le test de coint'egration de Johansen, nous
utilisons la proc'edure qu'il a propos'e en 1998 (Voir la proc'edure en annexe
D).
49modèle VAR
50Voir annexe C
51année du début de la crise
économique au Cameroun
La première étape du test de
cointégration de Johansen, consiste a` stationnariser les séries.
Les séries étant toutes intégrées du même
ordre, nous passons a` la deuxième étape. Nous devons maintenant
déterminer le nombre de retards optimal p, du modèle VAR(p) des
variables en niveau. Il est donc nécessaire de fixer le nombre de
retards maximal Pmax.
Plusieurs formules existent dans la littérature
économétrique, sur la détermination du nombre de retards.
La première et la plus utilisée est Pmax =
T1/4. On utilise aussi celle de Neyman et West(1957) qui
est de la forme Pmax = 4×[N/100]2/9. La
première formule nous permet d'obtenir Pmax = 2, 36 et celle de Neyman
3, 08. Dans les deux cas, nous optons pour un retard maximal égal a` 3
.
La procédure normale du test de johansen, consiste a`
lancer le modèle VAR(p) pour un p fixéallant de 1 a` Pmax. Par la
suite, on détermine le retard optimal, en choisisant le retard qui
minimise la majoritédes critères d'information. Comme, nous
réalisons ces estimations avec le logiciel Eviews, lors du lancement du
modèle VAR il ne retient que 2 critères d'information (Akaike et
Schwarz). Par contre, la littérature propose cinq critères
d'information52 pour choisir le retard optimal. Pour corriger ce
problème, nous réalisons sous Eviews dans un premier temps un
modèle VAR (`a partir des séries en niveau) avec un retard
compris entre 1 et 3, et dans un deuxième temps, nous déterminons
de façon résumée, les estimations pour les cinq
critères d'information.
Les résultats obtenus sur l'ordre optimal de chaque
critère d'information, sont consignés dans le tableau suivant.
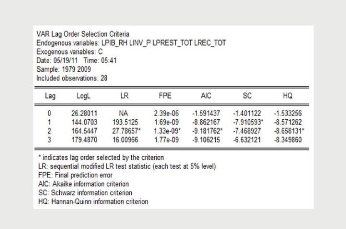
Tableau 4.2 : Retard optimal et critères d'information
Source : Sortie Eviews
52ces critères sont présentés en
annexe
D'après le tableau ci-dessus, le retard 2 est celui qui
minimise la plupart des critères d'information. En effet, les
critères FPE (Final Predicted Error), AIC (Akaike) et HQ (Hannan Quinn)
sont minimisés pour le retard 2, tandis que le critère SC
(Schwarz)est minimisépar le retard 1. Le critère LR donne aussi
le retard 2 comme retard optimal. Nous concluons a` cet effet, que le retard
optimal est p=2.
Le retard optimal que nous venons d'identifier est celui qu'on
utilisera pour effectuer le test de cointégration. La réalisation
du test de cointégration se fera au moyen de deux tests principaux dont
le test de la trace et le test de la valeur propre maximale. Ces tests ont pour
but de déterminer le nombre de relations de cointégration entre
les variables du modèle. Dans les estimations, la détermination
du nombre de relations de cointégrations, est nécessaire pour
identifier la forme du modèle a` correction d'erreur a` utiliser. La
littérature propose en effet cinq types de relations ou modèles
de cointégration dont :
? la relation de cointégration sans trend et sans
constante (modèle 1);
? la relation de cointégration sans trend et avec
constante (modèle 2);
? la relation de cointégration (linéaire) sans
trend et avec constante (modèle 3);
? la relation de cointégration (linéaire) avec
trend et constante (modèle 4);
? la relation de cointégration (quadratique) avec trend et
constante (modèle 5); Sur le plan pratique, la réalisation du
test de cointégration de Johansen (`a partir du logiciel Eviews)
effectue conjointement le test du nombre de relations de cointégration
donnépour chaque type de modèle présentéci-dessus,
et l'identification du modèle optimal, avec le nombre de relations de
cointégration retenu, a` partir des critères d'information (AIC
et SC).
Nous avons trouvéau préalable le retard optimal
égal a` 2. Ce retard est diminuéde 1 lors de la
réalisation du test de cointégration avec le logiciel Eviews, du
fait que les
variables du test seront exprimées en différence
première53. Les résultats du test du nombre de
relations de cointégration entre les variables du modèle sont
consignés dans le tableau ci-après.
53Hamisultane H.
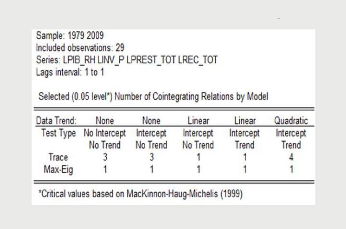
Tableau 4.3 : Test du nombre de relations de
cointégration
Source : Sortie Eviews
Les résultats présentés dans ce tableau
montrent que le test de la trace identifie 3 relations de cointégrations
pour les modèles 1 et 2, 1 relation de cointégration pour les
modèles 3 et 4, et 4 relations de cointégration pour le
modèle 5. Le test du critère du maximum de la valeur propre
indique 1 relation de cointégration pour tous les cinq modèles.
De ces résultats, nous déduisons que les variables de notre
modèle sont cointégrés. Nous estimons donc un
modèle VECM.
Estimation du modèle VECM
Nous venons de montrer que les séries de notre
modèle de long terme sont cointégrés, donc l'estimation
d'un modèle VECM est envisagée. Nous avons
présentéau chapitre pécédent le modèle de
base pour nos estimations. L'équation du modèle est en effet :
LPIBRHt = a0 + a1LINV Pt + a2LPRESTTOTt + a3LRECTOTt +
åt
Partant de cette équation matérialisant la
relation de long terme, nous spécifions une deuxième
équation (composée des relations de long et de court terme) qui
s'écrit de la manière suivante :
ÄLPIBRHt = â0 + ip j=1 èjÄLPIBRHt-j +
ip j=1 ãjÄLINV Pt-j + ip j=1 äjÄLPRESTTOTt-j +
ip j=1 çjÄLRECTOTt-j + ë(LPIBRHt-1 - a0 - a1LINV
Pt-1 - a2LPRESTTOTt-1 - a3LRECTOTt-1) + ut
O`u p est le retard optimal et ut est un bruit blanc. Dans
cette équation, le coefficient ë est la force de rappel vers
l'équilibre. Il est en effet, le coefficient de correction d'erreur. La
nature de la valeur de ce coefficient est capitale dans l'estimation du
modèle. En effet, il doit être négatif et significatif pour
estimer un modèle du type ECM (Error Correction Model). Dans le cas o`u
ce coefficient n'est pas négatif ou significatif, une
spécification du modèle de type ECM est rejetée
(Doucouré, 2004-2005). Par conséquent, la relation de long terme
serait détruite et on estime que la relation de court terme.
Après spécification des différents
modèles, nous estimons notre modèle VECM. L'estimation du
modèle VECM se fait en déterminant d'abord le type de
modèle54 avec le nombre de relations de cointégration.
A cet effet, nous nous contentons des résultats donnés par les
critères AIC et SC. Le tableau suivant présente pour chaque
critère d'information, le type de modèle et le nombre de
relations de cointégration a` retenir.

Tableau 4.4 : Critères d'information par type de
modèle et par nombre de relations de
cointégration
Source : Sortie Eviews
D'après le tableau ci-après, les deux
critères sont en accord sur le choix du modèle 4. Par contre, le
critère AIC propose 2 relations de cointégration et celui de
Schwarz propose une seule. Pour une meilleure estimation, nous retiendrons le
résultat donnépar le critère de Schwarz (SC), a` savoir le
modèle 4 avec une relation de cointégration.
54Il s'agit des 5 modèles
précédemment cités
A présent nous connaissons la nature de la relation de
long terme de notre modèle. Nous cherchons maintenant a` identifier la
relation de court terme. L'estimation du modèle VECM nous permettra de
trouver ces relations.
L'estimation du modèle VECM est obtenu a` partir des
résultats de l'annexe E (tableau E1). Elle permet de constater que la
valeur du coefficient de rappel55 est négative (-0,386) et
significative au seuil de 1 % (-9,152 est supérieur en valeur obsolue a`
2,5856). Nous pouvons a` cet effet valider l'hypothèse de
représentation sous forme de MCE des variables du modèle et
interpréter sans souci, la relation de long terme. Les coefficients des
variables du modèle VECM n'ont pas toutes la même
significativité. D'autres coefficients sont non significatifs.
L'équation globale du modèle est donnée par la relation
suivante :
Equation 1
ÄLPIBRHt = -0, 0097** - 0,
2046*ÄLPIBRHt-1 - 0, 0287-ÄLINV Pt-1
+ 0, 1595***ÄLPRESTTOTt-1 - 0, 0456*ÄLRECTOTt-1
- 0, 386***(LPIBRHt-1 - 0, 4505***LINV Pt-1 +
0, 4885***LPRESTTOTt-1 - 0, 111-LRECTOTt-1 - 0,
01585***t - 9, 164)
De cette équation, nous tirons l'équation de la
relation de long terme. Cette équation est en effet :
Equation 2
LPIBRHt = 0, 4505***LINV Pt-0,
4885***LPRESTTOTt+0, 111-LRECTOTt-1+ 0,
01585***t + 9, 164
***(**)[*]»-»Le
coefficient est significatif a` 1%(5%)[10%]»Le coefficient n'est
pas
significatif»
Le modèle VECM étant
déjàestimé, il convient désormais de le valider.
Nous devrions au préalable vérifier certaines
hypothèses.
55la variable dépendante étant LPIB RH
56quartile de 0,01 de la loi normale
Validation des hypoth`eses
Pour interpr'eter le modèle dont nous venons de
proc'eder aux estimations, nous validons au pr'ealable certaines
hypothèses. D'après la figure E1 en annexe, nous pouvons dire que
les r'esidus des variables de notre modèle sont bruits blancs. On
remarque n'eanmoins quelques d'ecalages de ces r'esidus par rapport aux seuils
limites de progression. Nous validons a` cet effet, l'hypothèse de bruit
blanc des r'esidus.
Test de normalitédes résidus
Les hypothèses relatives aux tests de normalit'e des
r'esidus utilis'es sont les suivantes : H0 : les r'esidus suivent une loi
normale
H1 : Les r'esidus ne suivent pas une loi normale
D'après les r'esultats du tableau E2 en annexe, les
tests Skewness, Kurtosis et JarqueBera montrent que les r'esidus suivent une
loi normale. Toutes les P-valeurs des tests sont strictement sup'erieures a` 5
%. Au risque de se tromper au seuil de 5 %, nous validons l'hypothèse de
normalit'e des r'esidus.
Test de non autocorrélation des résidus Ce test
admet les hypothèses suivantes :
H0 : les r'esidus sont non autocorrel'es
H1 : Les r'esidus sont autocorrel'es
Les r'esidus du modèle ne sont pas correl'es. En effet,
le test du multiplicateur de Lagrange (LM test) r'ealis'e sur les r'esidus est
non significatif pour tous les retards (voir tableau E3 en annexe).
L'hypothèse de non corr'elation des r'esidus n'est pas rejet'e au seuil
de 5 %. Nous validons par cons'equent l'hypothèse de non
autocorr'elation des r'esidus.
Test d'homoscédasticitédes résidus
Pour ce test, nous nous servons du test de White, dont les
hypothèses sont : H0 : les r'esidus sont homosc'edastiques
H1 : Les r'esidus sont h'et'erosc'edastiques
Le test d'homosc'edasticit'e de White a une nature identique aux
autres tests. Les r'esultats du tableau E4 en annexe, nous conforte sur la
validation de cette hypothèse.
Test de significativitéglobale du modèle VECM
D'après l''equation 1 du modèle a` correction
d'erreur, l'on peut constater que la plupart des coefficients des variables
explicatives sont significativement diff'erents de 0 (à1 %, 5 % o`u 10
%). De plus la F-statistique (32,2) est sup'erieur a` 2,32 le quantile de la
loi de Fisher57. Le modèle a` correction d'erreur est donc
globalement significatif. L'hypothèse de significativit'e globale du
modèle est donc valid'ee.
Stabilitédu modèle VECM
La figure E2 en annexe montre que toutes les racines du
polynôme caract'eristique sont repr'esent'ees a` l'int'erieur du cercle
unit'e. Celàindique que le modèle a` correction d'erreur est
globalement stable.
Les hypothèses du modèle 'etant valid'ees, nous
pouvons a` pr'esent interpr'eter les r'esultats issus des estimations de notre
modèle.
| 

