CHAPITRE II
DESCRIPTION DU CORPUS
2.1 MOTIVATIONS :
Il existe différents moyens pour choisir un type de
corpus, cela varie entre le document écrit, l'interview, le sondage, et
le questionnaire, toutes ses méthodes ont étaient utilisés
dans plusieurs domaines et par plusieurs personnes, mais l'importance des
résultats que nous cherchons et leurs fiabilités nous ont
poussé à voir plus loin et chercher un moyen plus efficace et
plus sure pour prouver notre hypothèse, alors nous avons opté
pour l'enregistrement sonore pour une partie , et le questionnaire pour l'autre
partie.
Notre choix du corpus a été guidé par sa
réalité et sa nature, on a préféré choisir
l'enregistrement directe des interactions agent/client a travers un micro
caché pour avoir le plus de crédibilité possible, et
échapper aux fausses réponses qu'on peut trouver dans un face a
face.
Pour les agents, le questionnaire nous a parut plus efficace,
puisque nous ne pouvions pas savoir a partir du corpus enregistré si ils
ont suivie une formation spécialisé, ou quel était leurs
niveau d'éducation.
La deuxième chose qui nous a poussé a faire ce
choix, et l'accessibilité du corpus, puisque l'un de nous est agent
commerciale la bas, ça nous a beaucoup facilité la tache pour
l'emplacement du matériels et le fonctionnement de l'opération,
nous savons très
bien qu'il est difficile si ce n'est pas impossible d'avoir
accès a de tels moyens au sein d'une entreprise, tenu par le secret
professionnel ou par le manque de confiance, la plupart des responsables
évitent ce genre d'enquêtes qui ne savent pas dans quelle mains
peut elle tombées !
La dernière chose qui a motivé notre choix du
corpus, c'est la variété des personnes présente, on y
trouve des personnes de différentes couches sociales, de
différents niveaux d'éducation, et de différentes
régions et ban lieux, se qui donnera un gout exotique a notre
recherche.
Selon Angeline Aubert-Lotarski - « La population
est constituée par l'ensemble des sujets, unités ou
objets qui sont potentiellement concernés par l'enquête. En
fonction de l'étude, la population peut être constituée
d'un ensemble de personnes, d'organisations
ou d'objets matériels ».
Il est généralement impossible, voire inutile,
d'effectuer le recueil de données sur l'ensemble de la population. C'est
pourquoi on sélectionne une partie de la population -
l'échantillon - sur qui va effectivement porter
l'enquête.
2.2 DESCRIPTION :
L'usage de corpus n'est pas réservé aux linguistes.
Néanmoins ceux-ci en sont des utilisateurs patentés, du fait,
entre autres, que leurs analyses portent sur des productions linguistiques ou
langagières non finies dont l'étude ne peut s'opérer que
sur un échantillon. Mais pour que l'analyse prétende à
quelque validité, cet échantillon doit être
représentatif.
Représentatif de quoi ?
* D'une réalité qui à la fois
préexiste à l'analyse et qu'il contribue à cerner et
à établir.
D'où toute une palette de corpus dont les principaux types
en usage dans la discipline, selon les matériaux utilisés, selon
la clôture imaginée, selon la fonction assignée..., sont
brièvement rappelés. La réflexion est ensuite
centré sur la délimitation de la place et de la fonction du
corpus entre faits, analyses et théories ; il est montré,
quelques exemples à l'appui, empruntés à la
démarche du dialectologue et du lexicologue, que le corpus ne saurait
être qu'un construit et que sa construction fait partie intégrante
du prisme théorique à travers lequel le linguiste entend
appréhender le réel. (1)
Depuis plus d'un siècle, les linguistes collectent des
enregistrements sonores (des corpus oraux) afin de décrire les langues
dans toutes leurs variété et de réaliser des applications
diverses, de l'enseignement jusqu'au traitement automatique des langues. Depuis
une vingtaine d'années, les études sur les corpus de langues
parlées ont complètement renouvelé les sciences du
langage, tant sur le plan descriptif que théorique et
méthodologique.
Les corpus oraux font de plus en plus partie de notre quotidien,
aussi bien à travers le web que dans notre environnement professionnel.
Leur taille est dans une phase de très forte croissance.
Notre corpus est un enregistrement audio sur cd mp3.
Qu'est-ce qu'un corpus oral ?
Un corpus de langue parlée est constitué
d'échantillons enregistrés d'une langue dans toutes ses
variétés (régions, genres, locuteurs) et de leurs
transcriptions. L'échantillonnage doit être fait selon des
critères réfléchis et en vue d'utilisations diverses. La
transcription peut répondre à divers critères de finesse.
Le corpus luimême est accompagné de divers outils informatiques :
alignement texte/son, concordances nécessaires à l'analyse
lexicale, analyses syntaxiques et prosodiques, logiciels d'exploitation afin de
l'établir.
Nous avons d'abord choisis le logiciel informatique pour
l'enregistrement car on ne disposait pas d'un magnétophone, donc on a
préféré faire un enregistrement sonore a l'aide d'un
logiciel sur micro ordinateur, et aussi car cela nous facilitera la tache
puisque chaque agent dans l'agence en question dispose d'un PC
comme outil de travail, alors ça sera plus pratique et plus discret.
Ensuite ont a dus chercher un logiciel avec lequel nous allons
faire la fonction de magnétophone c'est-à-dire un logiciel
d'enregistrement et de mixage audio .
Le logiciel choisis été « AUDACITY » qui
est assez connus dans le milieu utilitaires infos.
Audacity peut être utilisé comme un simple
magnétophone (pour un enregistrement sonore par exemple). Audacity
permet d'enregistrer et d'éditer des fichiers audio.
Développé sous licence open source, ce qui signifie que tout le
monde peut apporter sa contribution de programmeur au logiciel, Audacity fait
désormais figure de référence lorsque l'on parle
d'éditeurs audio libres.
Nous avons eu besoin d'un micro pour PC, on a réussi
à s'en procurer un de marque NAGASAKE 970, qui est assez petit pour
être caché.
Le choix du jour de l'enregistrement, n'est pas venu par hasard
aussi, on a opté pour le jeudi, car, il y'a plus de monde et on pourra
collecter le maximum de corpus.
L'agent sur place « l'un de nous » a mis le
matériel en marche après avoir installé le logiciel
AUDACITY et l'a essayé, il a tout prévu et préparé
avent le jour J.dus que les clients arrivent.
Le Jeudi .../.../ 2008 il a mis en marche le matériel et
attendent l'arrivée des clients.
Lorsque quelqu'un s'apprêtais à rentrer, l'agent
lance l'enregistrement, le temps de l'interaction, a la fin de la discutions,
l'agent arrête l'enregistrement et classe le fichier par un
numéro.
Bien entendu, la conversation était parfois interrompue
par des coups de téléphones, ou bien un silence assez durable
lorsque l'agent faisait le saisi sur le micro, nous avons signalé cela
sur la transcription phonologique. (2)
Les clients étaient différents, ils y avaient des
fonctionnaires, des médecins, des commerçants et des ouvriers, la
pluparts résidaient en Algérie, mais il y avait quelques uns qui
étaient émigrés en France.
Chaque client prenait le temps qu'il fallait pour avoir les
renseignements ou les services requis, vue que le micro était
caché personne ne s'est senti mal a l'aise, l'interaction se
déroulait dans les meilleurs conditions et le matérielle
fonctionnaient très bien.
Une fois la journée terminé et le corpus
collecté, nous avons procédé a la gravure d'un CD audio
pour la conservation du corpus, après cela nous avons entamé la
transcription phonologique en se basant surtout sur une technique personnel,
car il y'avait trop de mots en arabe dialectale ce qui nous a
empêché de suivre une méthode de transcription reconnus.
La question a été posée plus haut de savoir
à quoi rime un corpus ; pourquoi le linguiste, en l'occurrence, use-t-il
d'un corpus ? La réponse paraît évidente : quel que soit le
domaine ou le champ linguistique à étudier, le volume de
données est si considérable que l'on ne saurait tout prendre en
compte dans le cours de l'analyse.
De sorte que l'on est conduit à faire l'hypothèse
(le pari) que les régularités susceptibles d'être
découvertes par l'analyste sont potentiellement récursives et
donc qu'une analyse limitée à un sous-ensemble de faits peut
être de nature à rendre compte de l'ensemble. (1)
c'est dans ce contexte que nous allons essayer de travailler ,
essayer de trouver quelque chose de spéciale dans le corpus quelque
chose qui nous pousse a faire des recherche et a se poser des questions, toutes
ces anomalies ou ces remarque nous allons les découvrir durant la
transcription phonologique du corpus.
Durant la transcription, nous avons rencontré quelque
difficultés, comme la transcription d'un son, ou d'un soupire ou autre,
nous avons jugé préférable de ne pas reporter ce son, vu
que ça ne touche pas le domaine de notre recherche, puis que nous
nous intéressons surtout au lexique et pas au comportement
des personnes ou de la sociolinguistique.
Il y a aussi le fait que nous n'avons pas choisis un model
universel de transcription vu que notre corpus contiens beaucoup de mot et
d'expressions en langage parler ordinaire, donc nous allons suivre notre propre
transcription phonologique qu'on indiquera les clefs nécessaires plus
loin.
* LE CORPUS « Agence de voyage »
Le corpus que nous avons entre les mains « agence de
voyage » se compose de quatre enregistrements audio mp3, issue des
interactions enregistrés entre l'agent du comptoir de l'agence de voyage
et des clients.
Dans notre collecte du corpus, nous avons enregistré
une douzaine d'enregistrement, après que ses enregistrements on
été effectué. Nous avons essayé de faire une sorte
de sélection de ces corpus, qu'on a juge intéressant à
étudier,
Notre choix est tombé sur quatre enregistrements. En effet
notre sélection repose sur les critères suivants :
La difficulté dans l'analyse et l'interprétation
ainsi que la transcription d'un grand nombre d'enregistrement, car une douzaine
d'enregistrement peut atteindre une centaine de page de transcription.
Dans certain enregistrement, nous avons constaté qu'il n'y
a pas vraiment une interaction entre l'agent du comptoir et le client, car les
interventions du client se limitaient à oui ou non.
Dans les quatre corpus choisi, nous avons trouvé une
certaine ressemblance, ainsi qu'une certaine symétrie, cependant ces
quatre corpus comportent une même durée de temps.
Le choix des quatre corpus nous facilite la tache dans l'analyse
et l'interprétation de notre travail. Afin de nous permettre d'atteindre
les objectifs de notre recherche et ainsi que répondre au
problématique et l'hypothèse du départ. L'ensemble de ces
critères nous on poussé à choisir ces quatre corpus.
* La durée des enregistrements :
La durée des enregistrements est définie par le
temps écoulé au cours de ces quatre enregistrements en incluant
:
Le temps de tour de parole : c'est le temps que prend un tour de
parole. Ce dernier est, en sociolinguistique, une notion
désignant la possibilité dont bénéficie un
interlocuteur de prendre la parole dans le cadre d'une
conversation. La distribution des tours de parole est régie par
des normes sociales et contextuelles qui ont été
étudiées, notamment, par la sociologie interactionniste.
La conversation téléphonique, par exemple, interdit les
silences trop longs durant l'interaction, ce qui conduit à une
définition plus stricte des tours de paroles.
Le temps d'arrêt : c'est un laps de temps ou on remarque
qu'il n'y a aucun échange entre les deux locuteurs.
La durée des enregistrements nous permet de
dévoiler certaines anomalies, ainsi qu'elle nous permet de mieux
analyser et mieux interpréter notre corpus. Nous avons
chronométré l'ensemble des enregistrements afin de nous permettre
de calculer la durée de tous les enregistrements. Les résultats
sont les suivants :
La durée du premier enregistrement : 2 minutes 22
secondes.
La durée du deuxième enregistrement : 5
minutes 42 secondes. La durée du troisième
enregistrement : 1 minute 55 secondes. La durée du
quatrième enregistrement : 6 minutes 21
secondes. La durée totale des enregistrements
: 16 minutes 20 secondes. Les résultats sont
représentés par l'histogramme suivant : DUREE DES
ENREGISTREMENTS
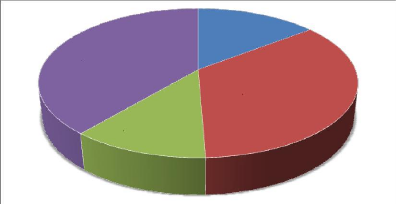
4e
enregistrement.
39%
3e
enregistrement.
12%
1er
enregistrement.
14%
2e
enregistrement.
35%
La transcription du corpus « agence de voyage
» :
La transcription du corpus et une opération essentielle
dans notre travail de recherche. La transcription est un procédé
qui consiste à prendre un document préalablement
enregistré en audio ou vidéo et de le taper sous forme de texte.
Il est assez long et difficile de transcrire un document, car la transcription
d'un discours prend beaucoup plus de temps que met la personne à parler.
En secrétariat, le texte est mis en forme de façon à ce
que n'importe qui puisse comprendre le document sous forme textuelle. En
revanche en linguistique, notamment dans la constitution de corpus
oraux, la transcription suit des conventions différentes.
Après que l'enregistrement eu été
effectué, nous avons entamé la transcription phonologique en se
basant surtout sur une technique personnel, car il y'avait trop de mots en
arabe dialectale ce qui nous a empêché de suivre une
méthode de transcription reconnus.
Dans notre transcription nous n'allons pas rendre compte des
phénomènes oraux, car cette étude des interactions n'est
pas figurée dans notre projet de recherche, dans notre travail ce qui
nous intéresse c'est les mots utilisés ainsi que la terminologie
spécialisé, les conventions que nous proposons ont
inévitablement leurs insuffisances mais s'efforcent de résoudre
la transcription d'une écoute attentive.
Pour faciliter la lecture, c'est la transcription orthographique
qui est choisie ; Les débuts des énoncés sont
marqués par des majuscules qui sont employés aussi pour les noms
propres et les sigles courants. Mais un certain nombre d'éléments
sont ajoutés ayant diverses fonctions :
Entête du corpus « agence de voyage >>
: elle comprend les informations nécessaires sur les
participants ainsi que sur le corpus lui même. Elle comprend les
informations suivantes : sujet ; sexe ; résidence ; métier ;
durée de l'enregistrement.
AG : agent.
C1; ; C3; C4 : client
: : Marques indiquant le début des
énoncées.
« >> : Marques indiquant les mots ou
phrase en arabe dialectale. Ex : AG : Trente et un, cinq ++c'est bon ? «
wela nezid. » ?
: « La zid. »
AG : « Nzidlek » après le cinq ?
: « Aya ~ce n'est pas la peine, ce n'est pas la peine
« we had ~l' retour toujours « fe lile » ?
AG : Dix neuf heures « tani »
AG : Après le cinq « andek » le huit ; le huit
janvier ...........(silence)
: « We chehal.. lah ykhallik ? »
+++ : Marques indiquant l'articulation
allongée. Ex :
C1 : « Eh naabih+++++ l'etnine aandi » rendez vous
« n'hat e dossier, « aaliha, maa lekhmis manakhdamch »
Mots en GRAS : Marque indiquant la terminologie
spécialisée. Ex : AG : Un visa touristique
normal « aandek ? mashi »visa étudient ?
AG : « Hado » avec réduction
valable quatre mois, c'est un billet promotionnel « machi
» plein tarif.
: La cabine « be » seize mille.
Mots en Gras Italique : marques
indiquant une interférence au cours de l'interaction. Ex :
AG : « Maalikche khouya ~ .... « Sonnerie
du téléphone »
AG : « répond au téléphone.
»
: Marques indiquant les pauses. Ex :
AG : Après le cinq « andek » le huit ; le huit
janvier ..... (Silence)
: « Makach ; makach.... »
AG « Loukan tfout » la date de départ «
tzid le..... »
!!!!!!!!!! : Marques indiquant une grande
exclamation. Ex :
C3 : EEEEhhhhhhhhhh !!!!
AG : Trente quatre !!!!!
C4 : Ohh là !!!!!
? : Marques indiquant une interrogation. Ex
AG : Le retour sur Marseille ou sur Alicante ? C4 : C'est bon
? Donc samedi « inchallah » ? Le nombre de page dans la
transcription :
Il nous a fallut douze page, pour faire toute la transcription de
ces quatre enregistrement, la transcription du premier enregistrement est faite
sur deux page ; quatre pour le deuxième enregistrement ; trois pour le
troisième enregistrement; et trois pour le dernier enregistrement.
2e
enregistrement
.; 4
4,5
3e
enregistrement
.; 3
4e
enregistrement
.; 3
4
3,5
3
2,5
2
1,5
1
0,5
1er
enregistrement
.; 2
0

1er enregistrement.2e enregistrement.3e enregistrement.4e
enregistrement
Cette répartition est représentée par
l'histogramme suivant :
Le nombre de tour de parole :
Le nombre de tour de parole varie entre un enregistrement et un
autre. Nous avons calculé le nombre de tour de parole de notre corpus
entre client et agent du comptoir, dans le premier enregistrement on a
relevé quarante tours de paroles ; dans le deuxième quatre vingt
tours de paroles ; pour le troisième nous avons relevé soixante
deux tours de paroles ; et pour le dernier enregistrement on a
enregistré quarante six tours de paroles.
Nous avons au totale 228 tours de paroles dans les interactions
entre l'agent de comptoir et les clients. Ces résultats seront
représentés sur l'histogramme suivant :
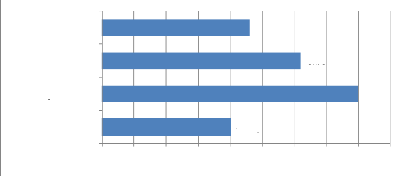
0 10 20 30 40 50 60 70 80 90
4e enregistrement.
3e enregistrement.
2e enregistrement.
1er enregistrement.
3e
enre
nt.;
80
1er
enregi
4e
enregistrement.;
46
strement.;
40
gistrement.; 62
2e
enregistreme
Le nombre de mots Utilisés :
Dans notre corpus « agence de voyage » il ya 1402 mots
utilisées, répartis sur 4 enregistrements, le premier
enregistrement comporte 184 mots, le deuxième 589 mots, le
troisième 370 mots, et le dernier 295 mots.
Pour mieux expliquer ces résultats nous allons utiliser un
histogramme. Ces résultats seront représentés sur
l'histogramme suivant :
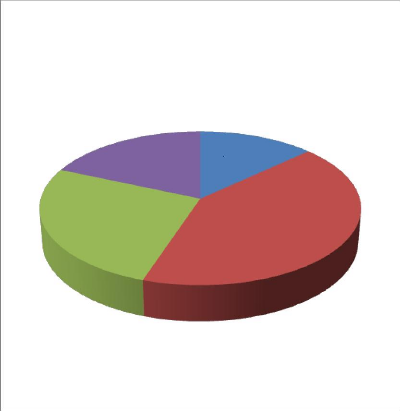
statestique des mots utilisés dans les
4
enregistrements En générale
4e
enregistrement.
1er
enregistrement.
3e
enregistrement.
2e
enregistrement.
| 

