Structure et efficience bancaire: problématique théorique et validation empirique sur les banques tunisiennes( Télécharger le fichier original )par Lamia Daly FSJEG Jendouba - Mastère 2006 |

II-2- les méthodes de mesures de l'approche paramétrique.Sous cette méthode, on démontre les approches permettant le calcul des frontières paramétriques dont la principale différence avec les méthodes non paramétriques réside dans les hypothèses concernant les résidus. Cette approche est caractérisée par la spécification d'une forme fonctionnelle aux coûts, aux profits ou à la relation entre les inputs, les outputs et les facteurs environnementaux. (Il s'agit habituellement d'une fonction translogarithmique ou Cobb Douglass). @ Les spécifications de la fonction de production forsund, F.R . Lovell, C.A.D et Schmit, P., (1980)54(*) ont définit la fonction de production comme étant « une fonction qui permet de donner le maximum d'output possible qui peut produit à partir des quantités données d'input . De la même façon, une fonction coût donne le niveau minimum de coût pour lequel il est possible de produire quelque niveau d'output étant donné les prix d'inputs 55(*)» *) les spécifications de fonction coûts : Dans le cas où nous souhaitons spécifier une frontière de coûts stochastique, on altère tout simplement la spécification du terme d'erreur de (Vit - Uit) à (Vit + Uit). Cette substitution transformera la fonction de production en une fonction de coûts définie sous la forme suivante : Cit = Xit + (Vit + Uit) Cit est le logarithme du coût de production de la firme i à la période t. Xit est le vecteur des prix des inputs et de la quantité d'outputs (exprimés en log) de la firme i à la période t. est le vecteur des paramètres à estimer Ui et Vi sont définis comme pour le cas d'une fonction de production. Dans la fonction de coûts, le terme Ui est défini comme étant le degré d'inefficience qui situe la firme en dessus de la frontière efficiente : -Si on suppose que la firme est allocativement efficiente, alors dans ce cas le terme Ui correspond à l'infefficience technique de la firme i. -Si on suppose que la firme est non allocativement efficiente, dans ce cas la nature du terme Ui devient imprécise et englobe à la fois les inefficiences techniques et allocative. En s'inspirant des travaux de Allen et Rai [1996]55(*) et Berger et Mester [1997]56(*), nous avons adopté l'approche par intermédiation et supposé que l'output agrégé Qi est une mesure de l'activité bancaire (comme le cas de la méthode DEA). Nous allons exposer trois techniques de la frontière paramétriques : DFA, TFA, SFA. @ Distribution Free Approach (DFA) Sickles et Schmidt (1984)56(*) et Berger et Humphrey (1997)56(*) ont trouvé que la DFA ne pose aucune hypothèse restrictive sur la distribution des paramètres d'inéfficience ou d'erreur aléatoire. Elle utilise seulement des données de panel et elle permet aux coefficients à estimer à varier au cours du temps. La méthode DFA suppose qu'il existe un noyau d'efficacité ou une efficacité moyenne pour chaque firme dans le temps. Ce noyau d'inefficacité est distingué de l'erreur aléatoire (et quelques fluctuations temporaires dans l'efficacité ) en supposant qu'il est persistent dans le temps, alors que les erreurs aléatoires tendent à s'annuler dans la période étudiée. Cette approche utilise des séries temporelles (t = 1,2,.., T) et un panel de données d'un échantillon représentatif (i = 1,2,.., N) où chaque banque i est représentée dans chaque année t. La fonction de coût en logarithme naturel est données par : Log Cit = log f (yit, wit) + log ìit + log õit, - Où : C correspond au coût total, - Yi : les quantités d'outputs produites, - Pi : les prix d'inputs utilisés dans la production. - I incorpore l'erreur statistique ui, qui suit une distribution normale symétrique ( 0 , ² ) et la mesure de l'inefficience vi, qui suit une distribution semi normale asymétrique représentant ainsi l'écart entre la banque i et la frontière d'efficience. Ce terme tient compte de l'inéfficience technique et allocative56(*) . La logique est que l'inefficience doit suivre une distribution tronquée puisqu'elle ne peut pas être négative. Les termes d'erreur et devront être estimés pour pouvoir estimer le niveau de l'inefficience de la banque. Tous les éléments peuvent varier dans le temps, avec l'exception seulement de ìt (représentant le terme d'efficacité) qui reste constant pour chaque banque par hypothèse. En estimation, les termes log ì et log õ sont traités comme un terme d'erreur composé, càd, log it= log ìit +log õit. Une fois le modèle est estimé, on fait la moyenne de ces résiduels à travers les T années pour chaque banque i. Cette moyenne (Ó t log i,t/T) est une estimation du terme d'efficacité log ìit, puisqu'on suppose que les terme aléatoires log õit vont s'annuler dans le temps ( quelques troncatures sont souvent utilisées pour vérifier cette hypothèse). La moyenne résiduelle estimée est ainsi transformée en mesure de l'x -efficacité de la banque i sur la période T, elle peut être écrite comme suit : INEFFit = exp (min (log ìt) - log ìit ) , Où : min (log ìt ) est la valeur minimale de log ìit de toutes les banques dans la période d'estimation T . La logique de ces hypothèses imposées sur les composantes des termes de l'erreur aléatoire compte sur la durée de la période de temps étudiée. Si une période courte est choisie (= 3 ans), les erreurs aléatoires peuvent ne pas s'annuler dans le temps, et dans ce cas l'erreur aléatoire peut être attribuée à l'inefficacité. Si, par contre, une période longue est choisie (= 10 ans), l'efficacité moyenne devient moins importante due aux changements de la gestion et autres évènements, c'est-à-dire, elle ne peut pas être constante dans la période de temps, ce qui viole l'hypothèse centrale de la méthode DFA. Deyong (1997.a) suggère qu'une période de temps de six années de données soit adéquate pour être sûr que l'efficacité estimée contient des faibles quantités d'erreurs aléatoires. L'approche DFA est une technique particulièrement attractive puisque ses hypothèses statistiques sont intuitives et elle est facile à appliquer. Contrairement à la méthode SFA, la méthode DFA n`impose aucune forte hypothèse concernant les distributions spécifiques des coefficients ou des erreurs aléatoires. En plus qu'elle utilise un panel de données, un autre avantage de la méthode DFA est qu'elle permet aux coefficients de varier dans le temps. Cependant, si l'efficacité est fluctuée dans le temps due aux changements techniques, des réformes de réglementation, au cycle du taux d'intérêt ou autre influence, la méthode DFA décrit ainsi la déviation moyenne de chaque firme à partie de la frontière de meilleure pratique plutôt que l'efficacité sur chaque point dans le temps. Par contre, cette approche suppose que l'efficience de chaque banque demeure stable au cours du temps puisque l'erreur aléatoire s'annule au cours de chaque période. L'inefficience de chaque banque de l'ensembles de l'échantillon est alors définie comme étant la différence entre sa moyenne résiduelle et la moyenne résiduelle d'une autre banque se situant sur la frontière efficiente La DFA suppose que l'inefficience peut suivre, à peu prés, n'importe quelle distribution tant que celle la n'est pas négative. Toutefois, d'après Berger et Humphrey (1997), si le nouveau d'efficience subit des changements au cours du temps suite aux changements technologiques, réformes régulatrices, cycles des taux d'intérêts ou autres alors la DFA continue à décrire les déviations moyennes de chaque firme par rapport à la frontière efficiente plutôt qu'évaluer l'efficience à n'importe quel instant fixe de la période. @ Thick Frontier Approch (TFA) Berger et Humphry (1991) 57(*) ont proposé que l'estimation des frontières à partir d'une fonction coût. En effet, la TFA spécifie une forme fonctionnelle pour la frontière et suppose que les déviations des valeurs prédites de la performance dans le quartile d'observation de performance les plus élevées et celui d'observation des performances les plus faibles, représentent l'erreur aléatoire, tandis que les déviations de la performance prévue entre le quartile inférieur et le quartile supérieur représentent l'inefficience. Le classement des banques se fait soit par l'enregistrement de la bonne ou mauvaise performance, soit les coûts moyens sont faibles ou élevés. Cette approches n'impose pas d'hypothèse restrictives, ni sur le terme d'inefficience, ni sur l'erreur aléatoire, sauf l'hypothèse que l'inefficience diffère entre les quartiles supérieur et inférieur et qu'un erreur aléatoire existe au sein des ces quartiles. La TFA ne fournit pas une mesure exacte de l'efficience, elle ne définit que son niveau général, puisqu'elle utilise dans son estimation les quartiles et les groupes de banques et par suite, elle ne permet pas d'estimer l'efficience pour chaque banque. @ Stochastic Frontier Approach (SFA) C'est la technique la plus utilisée, introduite par Aigner, Lovell et Schmid (1977)58(*) et qui utilise des modèles économétriques, généralement des fonctions de coûts, de profits ou de production, se présentant sous des formes fonctionnelles particulières bien déterminées, pour évaluer les capacités de production d'une banque pour la détermination de la frontière efficiente. Soit: Ln C = f(Yi, pi) + I ; Où : - C correspond au coût total, - Yi : les quantités d'outputs produites, - Pi : les prix d'inputs utilisés dans la production. - I incorpore l'erreur statistique ui, qui suit une distribution normale symétrique ( 0 , ² ) et la mesure de l'inefficience vi, qui suit une distribution semi normale asymétrique représentant ainsi l'écart entre la banque i et la frontière d'efficience. Ce terme tient compte de l'inéfficience technique et allocative59(*) . La logique est que l'inefficience doit suivre une distribution tronquée puisqu'elle ne peut pas être négative. Les termes d'erreur et devront être estimés pour pouvoir estimer le niveau de l'inefficience de la banque. La SFA utilise la méthode de maximum vraisemblance pour estimer la frontière stochastique. Toutefois le log de vraisemblance pour estimer se présente ainsi : Où : N : le nombre de firmes : La fonction de densité de la loi normale
Une fois le modèle est estimé, les mesures de l'inefficacité sont calculées en utilisant les résiduels. La moyenne et la méthode des distributions conditionnelles, E (i/I) et M (i/I ), respectivement sont toujours utilisées pour mesurer l'inefficacité de chaque firme dans l'échantillon. Cette espérance conditionnelle E (i/I ) donne une estimation de la mesure de l'X- efficacité pour chaque banque i L'utilisation de la (SFA) nous permet de dériver les estimations d'efficacité pour chaque banque en utilisant ses propres coûts opératoires et sans supposer que le frontière d'efficience est commune pour toutes les banques. Mais c'est une méthode qui basée sur l'hypothèse de la distribution, semi - normale des inefficacités relativement inflexibles, et présume que la plupart des firmes sont groupées prés de l'efficacité totale. En pratique, cependant, d'autre distribution sur le terme d'inefficacité (i ) peuvent être appropriées : tel que normal tronqué (Stevenson 1980), Berger et Deyoung (1997) ; gamma (Green 1990); exponentiel (Mester (1996) .. Toutefois ces méthodes permettent d'accorder plus de flexibilité à la distribution supposée d'inefficacité, peuvent rendre difficile la séparation de l'inefficacité (i) de l'erreur aléatoire (i) du fait que les distributions normales tronquées et les distributions gamma peuvent être proches de la distribution normale symétrique supposée de l'erreur aléatoire, ce qui peut mener à confondre entre l'inefficacité et l'erreur aléatoire. * 54 forsund, F.R . Lovell, C.A.D et Schmit, P., (1980),« A survey of frontier production functions and of their relationship to efficiency measurement». 70 op.cit * 55 Allen et Rai [1996] : « operational efficiency in Banking : international comparison ». 72 op,cit 73 Schmidt et Sickles (1984) : « Production frontier and panel data », Journal of business and economic statistics, 2, pp.(367- * 74 op, cit * 56 Ferrier,G.D. et Lovell, C.K. (1990) « Efficiency of Financial Institutions: International Survey and Directions for Future Research» Wharton Financial Center, Philadelphia, PA19104 U.S.A. * 57 op.cit * 58 Op.cit. * 59 Ferrier,G.D. et Lovell, C.K. (1990) « Efficiency of Financial Institutions: International Survey and Diretcions for Future Research» Wharton Financial Center, Philadelphia, PA19104 U.S.A. |
|


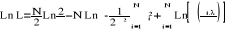

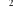 =
= 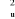 +
+ 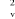 et
et 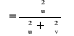 tel que [0,1].
tel que [0,1].