Chapitre III
Commandes linealres (LORI LOG,
LQGILTR)

35
Dans ce chapitre, nous nous penchons sur l'aspect
contrôle optimal de la suspension active par les commandes
linéaires (LQR, LQG, LQG/LTR). Dans un Premier temps, nous
présentons la théorie du contrôle optimale de chacune de
ces techniques de commande. Ensuite, chaque stratégie de contrôle
est appliquée au modèle quart de véhicule et
comparée à la suspension dite passive (en boucle ouverte).
3.1. Introduction
3.1.1. Contrôle optimal
La théorie de contrôle moderne se présente
comme la synthèse de la matrice de gain du contrôle par retour
d'état. Le contrôle intervient dans l'équation
d'état comme une donnée que l'on peut choisir, en imposant une
énergie de contrôle, afin de minimiser l'énergie
mécanique de la structure. Le problème du contrôle optimal
consiste essentiellement à déterminer le contrôle *( ),
admissible, apte à conduire le système vers un état
désiré *( ), tout en minimisant une fonctionnelle coût.
Afin de déterminer la solution d'un problème du contrôle
optimal, il existe plusieurs approches dont deux sont principales, la
première, constituée de la théorie de Hamilton-Jacobi,
consiste à établir des conditions suffisantes d'optimalité
global et la deuxième se base sur le principe de minimum de Pontriaguine
qui est un principe de variation, le contrôle optimal
doit minimiser une fonction appelée Hamiltonien.
3.2. Commande Linéaire Quadratique
3.2.1. Formulation du problème de commande (LQR)
Nous considérons le système linéaire
continu, invariant dans le temps, stabilisable et observable décrit par
les équations d'états suivantes :
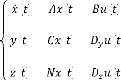
( ) = ( ) + ( )
( ) = ( ) + ( ) (3.1)
( ) = ( ) + ( )
où :
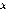

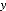
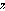
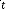
( ) : Vecteur d'état, de dimension x 1.
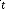
( ) : Vecteur de commande, de dimension x 1.
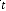
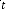
( ) : Vecteur de sortie ou d'observation, de dimension x 1. ( ) :
Vecteur de sorties contrôlées, de dimension x 1.
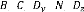
, , , ,
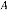
,
Sont des matrices de dimensions appropriées
indépendantes du temps.
La synthèse linéaire quadratique
dénommée LQ ou LQR (linear quadratic regulator) consiste
en la recherche d'une matrice gain , telle que la commande par
retour d'état ( ) =
- ( ) stabilise le système et minimise
l'expression quadratique à horizon infini [1] de la
fonction coût suivante :
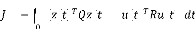
8
( ( ) ( ) + ( ) ( ))
2
=
1
(3.2)
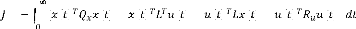
2 ( ( ) ( ) + ( ) ( ) + ( ) ( ) + ( ) ( ))
=
1
(3.3)
où les matrices de pondérations ,
, p p
satisfont :

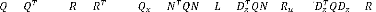
= ( + )
= ~ 0, = > 0, =
, =
que l'on peut réécrire sous la forme:

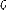

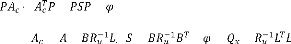
Est une matrice carrée symétrique définie
semi-positive et est une matrice symétrique définie positive. , ,
Sont respectivement les matrices de pondération sur l'état, de
couplage état-action et sur l'action.
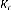
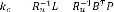
Comme nous l'avons vu précédemment, l'objectif de
la commande quadratique est de minimiser une fonctionnelle définie par
l'équation (3.2) à l'aide de la matrice gain optimale
placée dans la boucle de réaction. La solution à ce
problème d'optimisation à horizon infini1 est
donnée par l'expression de suivante :
= ( + ) (3.4)

où est une matrice constante, solution de
l'équation algébrique de Riccati suivante :
+ - + = 0 (3.5)
Avec = -
, = p - -

37
L'obtention du gain passe donc par la recherche de la solution
symétrique définie
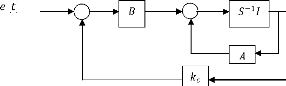
positive de l'équation de Riccati (3.5). La structure du
système de commande est conforme au schéma fonctionnel suivant
:
( ) = 0 +
+
+
+

( )

( )
Figure 3.1 - Schéma général de la commande
linéaire quadratique (LQR).
1 Lors de contrôle a horizon infini, aucune
condition n'est imposée sur l'état final

La force de cette méthode réside dans sa
simplicité, mais c'est aussi sa faiblesse, car à tout instant,
l'intégralité du vecteur d'état doit être
observée, ce qui n'est pas réalisable sur des systèmes
mécaniques complexes. Dans la majorité des problèmes de
commande, on ne dispose que d'une connaissance partielle du vecteur
d'état. Dans le cas de la suspension active, la déflexion du pneu
en est un bon exemple.
| 

