4.2.3 Détermination du
nombre de retards du VAR à niveau
L'estimation du modèle VAR nécessite de
déterminer au préalable le nombre de retards p. plusieurs
critères peuvent être utilisés pour réaliser cet
exercice crucial :
· une méthode basée sur l'examen des
propriétés statistiques des résidus du modèle
VAR ;
· une méthode basée sur l'utilisation des
critères d'information ;
· une méthode basée sur des tests de
nullité emboîtés sur les paramètres associés
au dernier décalage du modèle.
Nous utiliserons la méthode basée sur les
critères d'information.
Encadré 4 :
Détermination du nombre de retards du VAR à l'aide des
critères d'information
L'idée sur laquelle sont basés les
critères d'information est que l'ajout d'un ensemble de variables
explicatives dans le modèle améliore l'information mais en
même temps réduit les degrés de liberté. La
démarche consiste à fixer une valeur maximale pour p, (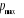 ), et de
calculer pour chaque modèle VAR (p), ), et de
calculer pour chaque modèle VAR (p), 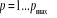 la valeur
du critère d'information. Le retard retenu est celui qui optimise
(minimise) la valeur du critère d'information. la valeur
du critère d'information. Le retard retenu est celui qui optimise
(minimise) la valeur du critère d'information.
Dans les modèles VAR, quatre critères sont
généralement utilisés :
Critère FPE (Final Predictor Error)
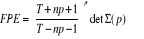
Critère AIC (Akaike Information
Criterion)
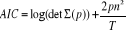
Critère SC (Schwartz Criterion)
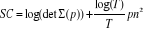
Critère HQ (Hannan Quinn)
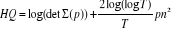
4.2.4 Analyse des
résultats de l'estimation du VECM
4.2.4.1 Tests de
causalité
Une variable X cause une variable Y si la
prédictibilité de Y est meilleure lorsque l'on tient compte de
l'information apportée par X. Plusieurs définitions statistiques
de la causalité existent. Nous utiliserons l'approche de Granger. La
causalité peut se mesurer de plusieurs manières :
Mesure de la causalité de X vers Y
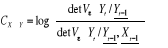
Mesure de la causalité instantanée de X
vers Y
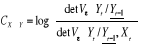
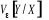 désigne l'erreur de prévision de Y sachant X
désigne l'erreur de prévision de Y sachant X
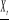 désigne l'information relative au passé
désigne l'information relative au passé 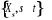
Si X ne cause pas Y, 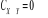
Statistique de test
Le test est effectué au moyen de la statistique du
maximum vraisemblance. L'on teste l'hypothèse nulle d'absence de
causalité. La statistique de test est 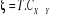 qui suit
sous qui suit
sous 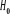 une loi de chi-deux à une loi de chi-deux à  degré de libertés.
degré de libertés.
· Si 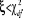 , on ne
rejette pas l'hypothèse nulle d'absence de causalité , on ne
rejette pas l'hypothèse nulle d'absence de causalité
· Sinon, l'hypothèse nulle d'absence de
causalité est rejetée.
En présence d'une co-intégration, les tests de
causalité de court terme ou de long terme sont menés à
partir du VECM.
| 

