La mise en place d'une base des données pour la gestion de la facturation des abonnés de la Regideso.( Télécharger le fichier original )par Sylvain MUKENDI isic kananga - Graduat 2016 |

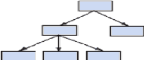
1.5. STRUCTURES DE DONNEESPour modéliser les données sous formes appropriée du SGBD a utiliser, il est nécessaire de connaitre quelques structures des bases de données. Dans cette partie nous présentons brièvement les différents modèles de représentations de données. 1.5 .1. LE MODELE HIERARCHIQUELe monde réel nous apparait souvent au travers des hiérarchies et étant donné que les BDD modélisent les informations du monde réel, il est normal que ce modèle soit l'un des modèles les plus répandus. Le modèle hiérarchique peut être vu comme un cas particulier du modèle réseau, l'ensemble de lignes entre types d'article devant former des graphes hiérarchiques. Cependant, les articles ne peuvent avoir des données répétitives. Dans cette structure les données sont organisées selon une arborescence. Chaque noeud (entité) de l'arbre correspondant à une classe d'entité du monde réel et le chemin entre les noeuds représente les liens existant entre les entités. Le SGBD le plus connu dans cette catégorie est IMS, produit ancien de IBM, très répandu dans les applications de production. Les concepts de la base du modèle sont les champs, plus petites unîtes de données possédant chacune un nom et l'article7(*). L'article : suite de champs, portant un nom et constituant l'unité d'échange entre la base de données et les applications. Les articles sont relies entre eux par de liens hiérarchiques : a un article père possédant N articles fils. La notion de type d'article qui désigne le schéma d'un article (description contenant) sa distingue ici de celle d'occurrences d'article qui représentent les différentes valeurs stockées de la base. Dans ce modèle nous pouvons retenir que : · Il y a un seul type article racine ; · La racine peut avoir un nombre quelconque de types d'articles d'enfant · Chaque type d'article enfant de la racine peut avoir un nombre quelconque de types d'articles d'enfant, et ainsi de suite ; · A une occurrence d'un type d'article donne, peuvent correspondre 0,1 ou N occurrence de chaque type d'article d'enfant ; · Une occurrence d'article enfant ne peut exister sans l'occurrence d'un article. Nota : Détruire une occurrence d'article père, détruit par conséquent également les occurrences des ses enfants. Exemple du modèle hiérarchique8(*)
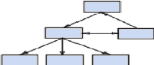
1.5.2. LE MODELE RESEAUDans ce modèle, les données sont représentées sous formes graphique, c'est une facilite très importante de représentation de la réalité d'une entreprise et proposant la notion de sous ensemble. Ce modèle est une extension de la structure hiérarchique dans lequel le graphe des objets n'est pas limite. Il permet en outre de représenter le partage ainsi que les cycliques entre les objets. Le SGBD conçu selon ce modèle se conforme aux normes fixées par le groupe CODASYL (Conférence On Data System Langages) en 1971. Les SGBD réseaux les plus représentes sur le marche sont les systèmes IDS II (Information Data Store), conçu par BACHMAN et WILLIAMS, ou IMS 2 d'IBM. Le SGBD réseau propose une solution pour : · gérer les relations porteuses de cardinalités maximales a n ; · prendre en compte la cardinalité mini à 0 ; · gérer les relations de type n=aire · obtenir plusieurs points d'accès, autres que le sommet de l'arbre. Pour cela, il modifie l'une des règles de dépendance entre les entités : Une entité "fille" peut avoir plusieurs entités "mères". Enfin les SGBD de type CODASYL permettent de mettre en place d'autres points d'entrée dans la base de données : les Data=Record=Key. Ces clés d'accès sont positionnées sur les segments régulièrement sollicites pour certains traitements, ce qui permet d'améliorer les temps d'accès aux données et d'alléger les traitements de recherche de ces mêmes données. Il est clair que ce type de SGBD apporte une plus grande souplesse et une plus grande rapidité aux différents traitements. Mais les chemins d'accès aux données restent très dépendants de la structure adoptée. Le langage navigationel qui permet d'accéder et de manipuler les données reste lourd : il faut connaitre le chainage et les jeux de pointeurs mis en place en plus de la signification des données. En dehors de traitements préétablis, la base de données n'est accessible qu'a des spécialistes. Le schéma de la base de données, avec les jeux de pointeurs et les clés d'accès aux records, nécessite une compilation a chaque modification de structure et la refonte des différents programmes. L'évolution ou la modification de telles bases de données restent donc délicates a mener. Exemple du modèle Réseau
* 7 CITUMBA J., techniques des bases des données, G3 Info ISGT, 2012, Inédit. * 8 Arnold Roch et Jose, M., La méthode Merise, pp. 23=25. CITUMBA J., techniques des bases des données, G3 Info, ISGT, 2012, Inédit. |
|