6.1 Distance
Un opérateur de ressemblance 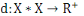 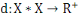 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 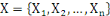 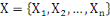 est dit distance, s'il vérifie en plus des deux
propriétés 1 et 2 les propriétés d'identité
et d'inégalité triangulaire suivantes : est dit distance, s'il vérifie en plus des deux
propriétés 1 et 2 les propriétés d'identité
et d'inégalité triangulaire suivantes :
3.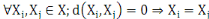 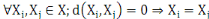 (propriété de d'identité) (propriété de d'identité)
4.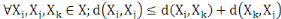 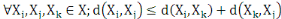 (inégalité triangulaire) (inégalité triangulaire)
6.2 Indice de similarité
Un opérateur de ressemblance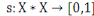 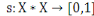 défini sur l'ensemble d'individus défini sur l'ensemble d'individus 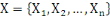 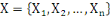 est dit indice de similarité (ou similarité), s'il
vérifie en plus de la propriété de symétrie (1) les
deux propriétés suivantes : est dit indice de similarité (ou similarité), s'il
vérifie en plus de la propriété de symétrie (1) les
deux propriétés suivantes :
5.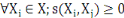 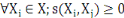 (propriété de positivité) (propriété de positivité)
6.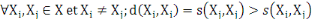 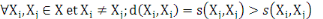 (propriété de maximisation). (propriété de maximisation).
Il convient de noter ici que le passage de l'indice de
similarité s à la notion duale d'indice de dissimilarité
(que nous noterons d), est trivial. Etant donné smax la
similarité d'un individu avec lui-même (smax= 1 dans le cas d'une
similarité normalisée), il suffit de poser :
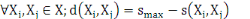
6.3 Mesure de ressemblance entre individus à
descriptions classiques
Le processus de classification vise à structurer les
données contenues dans X={X1, X2, ...,
Xn} en fonction de leurs ressemblances, sous forme d'un ensemble de
classes à la fois homogènes et contrastées.
L'ensemble d'individu X est décrit
généralement sur un ensemble de m variables Y= {Y1,
Y2,..., Ym} définies chacune par :
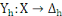
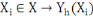
Où Äh est le domaine d'arrivée
de la variable Yh.
En conséquence, les données de classification
sont décrites dans un tableau Individus-variables où chaque case
du tableau contient la description d'un individu sur une des m variables. Ce
tableau Individus-Variables est en général un tableau
homogène qui peut être de type quantitatif (cas où toutes
les variables sont quantitatives) ou qualitatif (cas où toutes les
variables sont qualitatives).
6.4 Tableau de données numériques
(continues ou discrètes)
La distance la plus utilisée pour les données de
type quantitatives continues ou discrètes est la distance de Minkowski
d'ordre á définie dans Rm par :
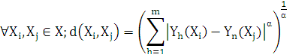
Où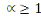 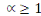 , , 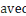 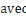 si : si :
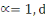 Ø Ø 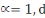 est la distance de city-block ou Manhattan. est la distance de city-block ou Manhattan.
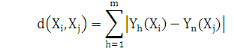
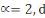 Ø Ø 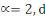 est la distance Euclidienne classique. est la distance Euclidienne classique.
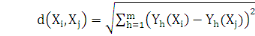 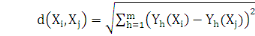
Avant de continuer nous allons faire une présentation
des méthodes statistiques que nous avons retenues. Vu que L'ACM est
souvent définie comme une analyse factorielle sur un tableau disjonctif
complet et l'analyse factorielle est à son tour définie comme une
double analyse en composantes principales. Nous allons faire un petit rappel
rapide sur ces méthodes factorielles en commençant par l'analyse
en composante principal et nous allons chuter avec la l'ACM.
| 

