II.
PROCÉDURES ÉCONOMÉTRIQUES : ESTIMATIONS DES COURBES
LISSES.
Deux éléments importants doivent rester
à esprit lorsqu'on veut appliquer économétriquement la
méthode de Bohn (1998) : rechercher la forme fonctionnelle de la
fonction de réaction de la politique fiscale et la dynamique du
coefficient de réaction dans le cas hypothétique de la non
linéarité. Contrairement à Bohn (1998), nous n'allons pas
procéder à des estimations paramétriques linéaires
mais plutôt supposer que la forme fonctionnelle de la relation est
inconnue. Nous procéderons donc à des estimations non
paramétriques et semi-paramétriques39(*). Dans cette partie, nous
allons dans un premier temps présenter les deux principales
méthodes d'estimation qui vont être utilisées :
estimations non paramétriques et estimations semi-paramétriques.
Ensuite nous analyserons les données que nous allons utiliser dans le
cadre du Cameroun.
II.1.
MÉTHODES D'ESTIMATION DES MODÈLES NON PARAMÉTRIQUES ET
SEMI-PARAMÉTRIQUES.
Nous allons faire une présentation sommaire des
méthodes d'estimation non paramétriques et des méthodes
semi-paramétriques. Les modèles non paramétrique ont
été introduit par Hastie et Tibshirani (1990)40(*). Cette idée de
modèle flexible a été étendue dans les estimations
des modèles à coefficient variant dans le temps par Hastie et
Tibshirani (1993).
II.1.1. ESTIMATIONS NON
PARAMETRIQUES.
Les méthodes retenues ici sont celles des
modèles GAM41(*)
qui supposent que les relations non linéaires qui existent entre la
variable expliquée et chacune des variables explicatives sont sous forme
additionnelle.
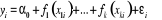 (3.07) (3.07)
Où 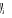 est la variable endogène, est la variable endogène, 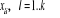 les variables exogènes et les variables exogènes et  des fonctions lisses inconnues. On supposera que le terme d'erreur des fonctions lisses inconnues. On supposera que le terme d'erreur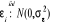 et non corrélé42(*). On veut estimer les fonctions f(x) pour
chaque point x. La pente, et non corrélé42(*). On veut estimer les fonctions f(x) pour
chaque point x. La pente, 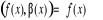 est le gradient de f dans le cas multidimensionnel. est le gradient de f dans le cas multidimensionnel. 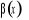 est la pente de la tangente de f en x et varie en
fonction de la valeur de x. Les estimations des noyaux de
densité de est la pente de la tangente de f en x et varie en
fonction de la valeur de x. Les estimations des noyaux de
densité de 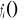 sont obtenues en utilisant la méthode des moindres carrés
ordinaires local (MCOL). On l'obtient en minimisant sous la contrainte que
chaque point est borné, la somme carrée des erreurs43(*) : sont obtenues en utilisant la méthode des moindres carrés
ordinaires local (MCOL). On l'obtient en minimisant sous la contrainte que
chaque point est borné, la somme carrée des erreurs43(*) :
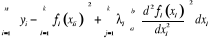 (3.08) (3.08)
Henderson et Ullah (2004) montrent que dans le cas où
les erreurs sont autocorrélées, il est possible de tenir compte
de l'information contenue dans la matrice de variance covariance des erreurs en
appliquant les moindres carrés ordinaires local pondérés
(MCOLP). Pour simplifier on peut supposer que les variables sont
ordonnées et écrire les contraintes de la façon suivante
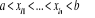 . .  le multiplicateur de Lagrange est le paramètre de lissage et son
choix joue un rôle très important44(*). Une petite valeur pour le multiplicateur de Lagrange est le paramètre de lissage et son
choix joue un rôle très important44(*). Une petite valeur pour  réduit la variance de l'ajustement mais élève le
biais. On parle de substitution biais-variance (Hasti et Tibshirani, 1990). Une
façon de déterminer le paramètre de lissage réduit la variance de l'ajustement mais élève le
biais. On parle de substitution biais-variance (Hasti et Tibshirani, 1990). Une
façon de déterminer le paramètre de lissage 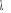 est de recourir au critère GCV45(*) (Hasti et Tibshirani, 1990, chapitre 3).
D'après ce critère, est de recourir au critère GCV45(*) (Hasti et Tibshirani, 1990, chapitre 3).
D'après ce critère, 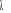 est choisi de façon à ce que est choisi de façon à ce que
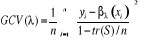 (3.09) (3.09)
soit minimal. S est une matrice appelée le lisseur et
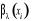 est l'ajustement au point est l'ajustement au point 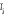 . Ce critère fonctionne comme le critère Ordinary Cross
Validation (OCV) : le model est ajusté aux données avec une
observation en moins. Ensuite, on mesure la différence carrée
entre la valeur du point ignorée et la prévision de ce point par
le modèle. Le processus est répété pour chacune des
observations. On calcule la différence moyenne entre le modèle
(ajuster pour toutes les observations à l'exception d'une observation)
et les points ignorées. Enfin on cherche à minimiser cette
différence moyenne. L'idée est que si le modèle est un peu
trop lissé ou très peu lissé, il ne pourra pas faire une
bonne prédiction de l'observation ignorée dans le processus
d'ajustement. La différence entre OCV et GCV est que le critère
GCV remplace les éléments de la diagonale du lisseur par leur
valeur moyenne, . Ce critère fonctionne comme le critère Ordinary Cross
Validation (OCV) : le model est ajusté aux données avec une
observation en moins. Ensuite, on mesure la différence carrée
entre la valeur du point ignorée et la prévision de ce point par
le modèle. Le processus est répété pour chacune des
observations. On calcule la différence moyenne entre le modèle
(ajuster pour toutes les observations à l'exception d'une observation)
et les points ignorées. Enfin on cherche à minimiser cette
différence moyenne. L'idée est que si le modèle est un peu
trop lissé ou très peu lissé, il ne pourra pas faire une
bonne prédiction de l'observation ignorée dans le processus
d'ajustement. La différence entre OCV et GCV est que le critère
GCV remplace les éléments de la diagonale du lisseur par leur
valeur moyenne, 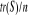 qui est plus facile à calculer (Greiner et al., 2005). qui est plus facile à calculer (Greiner et al., 2005).
Il faut enfin noter que pour un grand nombre d'observations,
les estimateurs MCOLP sont asymptotiquement sans biais et de variance minimale
(Lin et Carroll, 2000).
* 39 Grâce aux
développements des logiciels statistiques, Plusieurs auteurs ont
adopté de façon satisfaisante des approches non
paramétriques et semi-paramétriques : Greiner (2004) ;
Greiner et Kauermann (2005) ; Greiner et al. (2005) etc.
* 40 Leur implémentation
a été rendue possible grâce aux développements de
logiciels tels Splus, R ou Gauss...
* 41 General Additive Models
* 42 iid est
l'abréviation d'indépendantes et identiquement
distribuées.
* 43 Voir Ryan (1997).
* 44Voir Fan et Gijbels (1992)
et Pagan et Ullah (1999) pour des détails.
* 45 Generalized cross
validation.
|